by Ajoy Majumdar, Zhen Li
Most large companies have numerous data sources with different data formats and large data volumes. These data stores are accessed and analyzed by many people throughout the enterprise. At Netflix, our data warehouse consists of a large number of data sets stored in Amazon S3 (via Hive), Druid, Elasticsearch, Redshift, Snowflake and MySql. Our platform supports Spark, Presto, Pig, and Hive for consuming, processing and producing data sets. Given the diverse set of data sources, and to make sure our data platform can interoperate across these data sets as one “single” data warehouse, we built Metacat. In this blog, we will discuss our motivations in building Metacat, a metadata service to make data easy to discover, process and manage.
Objectives
The core architecture of the big data platform at Netflix involves three key services. These are the execution service (Genie), the metadata service, and the event service. These ideas are not unique to Netflix, but rather a reflection of the architecture that we felt would be necessary to build a system not only for the present, but for the future scale of our data infrastructure.
Many years back, when we started building the platform, we adopted Pig as our ETL language and Hive as our ad-hoc querying language. Since Pig did not natively have a metadata system, it seemed ideal for us to build one that could interoperate between both.
Thus Metacat was born, a system that acts as a federated metadata access layer for all data stores we support. A centralized service that our various compute engines could use to access the different data sets. In general, Metacat serves three main objectives:
- Federated views of metadata systems
- Unified API for metadata about datasets
- Arbitrary business and user metadata storage of datasets
It is worth noting that other companies that have large and distributed data sets also have similar challenges. Apache Atlas, Twitter’s Data Abstraction Layer and Linkedin’s WhereHows (Data Discovery at Linkedin), to name a few, are built to tackle similar problems, but in the context of the respective architectural choices of the companies.
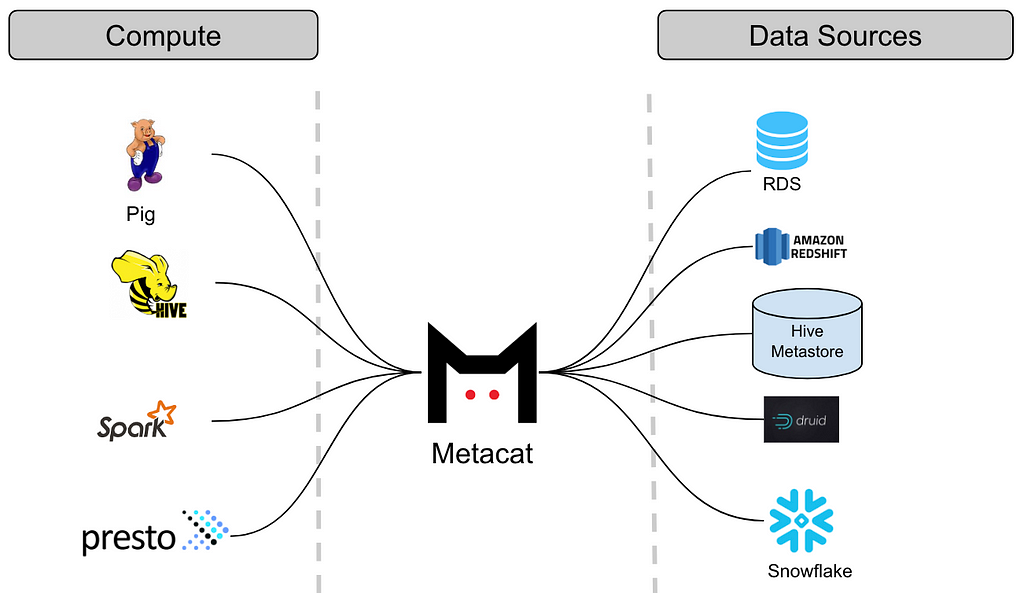
Metacat
Metacat is a federated service providing a unified REST/Thrift interface to access metadata of various data stores. The respective metadata stores are still the source of truth for schema metadata, so Metacat does not materialize it in its storage. It only directly stores the business and user-defined metadata about the datasets. It also publishes all of the information about the datasets to Elasticsearch for full-text search and discovery.
At a higher level, Metacat features can be categorized as follows:
- Data abstraction and interoperability
- Business and user-defined metadata storage
- Data discovery
- Data change auditing and notifications
- Hive metastore optimizations
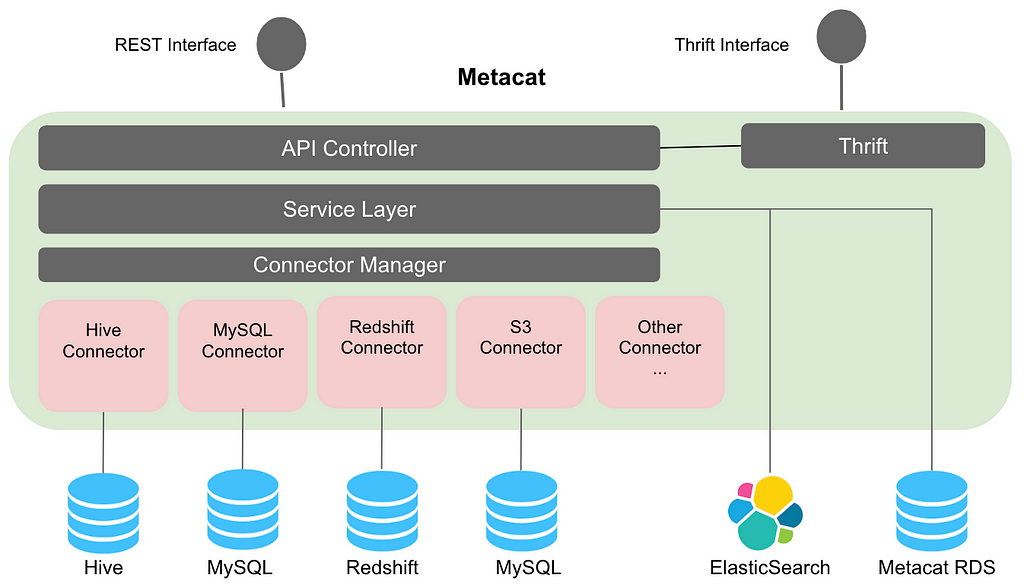
Data Abstraction and Interoperability
Multiple query engines like Pig, Spark, Presto and Hive are used at Netflix to process and consume data. By introducing a common abstraction layer, datasets can be accessed interchangeably by different engines. For example: A Pig script reading data from Hive will be able to read the table with Hive column types in Pig types. For data movement from one datastore to another, Metacat makes the process easy by helping in creating the new table in the destination data store using the destination table data types. Metacat has a defined list of supported canonical data types and has mappings from these types to each respective data store type. For example, our data movement tool uses the above feature for moving data from Hive to Redshift or Snowflake.
The Metacat thrift service supports the Hive thrift interface for easy integration with Spark and Presto. This enables us to funnel all metadata changes through one system which further enables us to publish notifications about these changes to enable data driven ETL. When new data arrives, Metacat can notify dependent jobs to start.
Business and User-defined Metadata
Metacat stores additional business and user-defined metadata about datasets in its storage. We currently use business metadata to store connection information (for RDS data sources for example), configuration information, metrics (Hive/S3 partitions and tables), and tables TTL (time-to-live) among other use cases. User-defined metadata, as the name suggests, is a free form metadata that can be set by the users for their own usage.
Business metadata can also be broadly categorized into logical and physical metadata. Business metadata about a logical construct such as a table is considered as logical metadata. We use metadata for data categorization and for standardizing our ETL processing. Table owners can provide audit information about a table in the business metadata. They can also provide column default values and validation rules to be used for writes into the table.
Metadata about the actual data stored in the table or partition is considered as physical metadata. Our ETL processing stores metrics about the data at job completion, which is later used for validation. The same metrics can be used for analyzing the cost + space of the data. Given two tables can point to the same location (like in Hive), it is important to have the distinction of logical vs physical metadata because two tables can have the same physical metadata but have different logical metadata.
Data Discovery
As consumers of the data, we should be able to easily browse through and discover the various data sets. Metacat publishes schema metadata and business/user-defined metadata to Elasticsearch that helps in full-text search for information in the data warehouse. This also enables auto-suggest and auto-complete of SQL in our Big Data Portal SQL editor. Organizing datasets as catalogs helps the consumer browse through the information. Tags are used to categorize data based on organizations and subject areas. We also use tags to identify tables for data lifecycle management.
Data Change Notification and Auditing
Metacat, being a central gateway to the data stores, captures any metadata changes and data updates. We have also built a push notification system around table and partition changes. Currently, we are using this mechanism to publish events to our own data pipeline (Keystone) for analytics to better understand our data usage and trending. We also publish to Amazon SNS. We are evolving our data platform architecture to be an event-driven architecture. Publishing events to SNS allows other systems in our data platform to “react” to these metadata or data changes accordingly. For example, when a table is dropped, our S3 warehouse janitor services can subscribe to this event and clean up the data on S3 appropriately.
Hive Metastore Optimizations
The Hive metastore, backed by an RDS, does not perform well under high load. We have noticed a lot of issues around writing and reading of partitions using the metatore APIs. Given this, we no longer use these APIs. We have made improvements in our Hive connector that talks directly to the backed RDS for reading and writing partitions. Before, Hive metastore calls to add a few thousand partitions usually timed out, but with our implementation, this is no longer a problem.
Next Steps
We have come a long way on building Metacat, but we are far from done. Here are some additional features that we still need to work on to enhance our data warehouse experience.
- Schema and metadata versioning to provide the history of a table. For example, it is useful to track the metadata changes for a specific column or be able to view table size trends over time. Being able to ask what the metadata looked like at a point in the past is important for auditing, debugging, and also useful for reprocessing and roll-back use cases.
- Provide contextual information about tables for data lineage. For example, metadata like table access frequency can be aggregated in Metacat and published to a data lineage service for use in ranking the criticality of tables.
- Add support for data stores like Elasticsearch and Kafka.
- Pluggable metadata validation. Since business and user-defined metadata is free form, to maintain integrity of the metadata, we need validations in place. Metacat should have a pluggable architecture to incorporate validation strategies that can be executed before storing the metadata.
As we continue to develop features to support our use cases going forward, we’re always open to feedback and contributions from the community. You can reach out to us via Github or message us on our Google Group. We hope to share more of what our teams are working on later this year!
And if you’re interested in working on big data challenges like this, we are always looking for great additions to our team. You can see all of our open data platform roles here.
Metacat: Making Big Data Discoverable and Meaningful at Netflix was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
via Planet MySQL
Metacat: Making Big Data Discoverable and Meaningful at Netflix