
Running databases on cloud infrastructure is getting increasingly popular these days. Although a cloud VM may not be as reliable as an enterprise-grade server, the main cloud providers offer a variety of tools to increase service availability. In this blog post, we’ll show you how to architect your MySQL or MariaDB database for high availability, in the cloud. We will be looking specifically at Amazon Web Services and Google Cloud Platform, but most of the tips can be used with other cloud providers too.
Both AWS and Google offer database services on their clouds, and these services can be configured for high availability. It is possible to have copies in different availability zones (or zones in GCP), in order to increase your chances to survive partial failure of services within a region. Although a hosted service is a very convenient way of running a database, note that the service is designed to behave in a specific way and that may or may not fit your requirements. So for instance, AWS RDS for MySQL has a pretty limited list of options when it comes to failover handling. Multi-AZ deployments come with 60-120 seconds failover time as per the documentation. In fact, given the “shadow” MySQL instance has to start from a “corrupted” dataset, this may take even longer as more work could be required on applying or rolling back transactions from InnoDB redo logs. There is an option to promote a slave to become a master, but it is not feasible as you cannot reslave existing slaves off the new master. In the case of a managed service, it is also intrinsically more complex and harder to trace performance problems. More insights on RDS for MySQL and its limitations in this blog post.
On the other hand, if you decide to manage the databases, you are in a different world of possibilities. A number of things that you can do on bare metal are also possible on EC2 or Compute Engine instances. You do not have the overhead of managing the underlying hardware, and yet retain control on how to architect the system. There are two main options when designing for MySQL availability – MySQL replication and Galera Cluster. Let’s discuss them.
MySQL Replication
MySQL replication is a common way of scaling MySQL with multiple copies of the data. Asynchronous or semi-synchronous, it allows to propagate changes executed on a single writer, the master, to replicas/slaves – each of which would contain the full data set and can be promoted to become the new master. Replication can also be used for scaling reads, by directing read traffic to replicas and offloading the master in this way. The main advantage of replication is the ease of use – it is so widely known and popular (it’s also easy to configure) that there are numerous resources and tools to help you manage and configure it. Our own ClusterControl is one of them – you can use it to easily deploy a MySQL replication setup with integrated load balancers, manage topology changes, failover/recovery, and so on.
One major issue with MySQL replication is that it is not designed to handle network splits or master’s failure. If a master goes down, you have to promote one of the replicas. This is a manual process, although it can be automated with external tools (e.g. ClusterControl). There is also no quorum mechanism and there is no support for fencing of failed master instances in MySQL replication. Unfortunately, this may lead to serious issues in distributed environments – if you promoted a new master while your old one comes back online, you may end up writing to two nodes, creating data drift and causing serious data consistency issues.
We’ll look into some examples later in this post, that shows you how to detect network splits and implement STONITH or some other fencing mechanism for your MySQL replication setup.
Galera Cluster
We saw in the previous section that MySQL replication lacks fencing and quorum support – this is where Galera Cluster shines. It has a quorum support built-in, it also has a fencing mechanism which prevents partitioned nodes from accepting writes. This makes Galera Cluster more suitable than replication in multi-datacenter setups. Galera Cluster also supports multiple writers, and is able to resolve write conflicts. You are therefore not limited to a single writer in a multi-datacenter setup, it is possible to have a writer in every datacenter which reduces the latency between your application and database tier. It does not speed up writes as every write still has to be sent to every Galera node for certification, but it’s still easier than to send writes from all application servers across WAN to one single remote master.
As good as Galera is, it is not always the best choice for all workloads. Galera is not a drop-in replacement for MySQL/InnoDB. It shares common features with “normal” MySQL – it uses InnoDB as storage engine, it contains the entire dataset on every node, which makes JOINs feasible. Still, some of the performance characteristics of Galera (like the performance of writes which are affected by network latency) differ from what you’d expect from replication setups. Maintenance looks different too: schema change handling works slightly different. Some schema designs are not optimal: if you have hotspots in your tables, like frequently updated counters, this may lead to performance issues. There is also a difference in best practices related to batch processing – instead of executing queries in large transactions, you want your transactions to be small.
Proxy tier
It is very hard and cumbersome to build a highly available setup without proxies. Sure, you can write code in your application to keep track of database instances, blacklist unhealthy ones, keep track of the writeable master(s), and so on. But this is much more complex than just sending traffic to a single endpoint – which is where a proxy comes in. ClusterControl allows you to deploy ProxySQL, HAProxy and MaxScale. We will give some examples using ProxySQL, as it gives us good flexibility in controlling database traffic.
ProxySQL can be deployed in a couple of ways. For starters, it can be deployed on separate hosts and Keepalived can be used to provide Virtual IP. The Virtual IP will be moved around should one of the ProxySQL instances fail. In the cloud, this setup can be problematic as adding an IP to the interface usually is not enough. You would have to modify Keepalived configuration and scripts to work with elastic IP (or static -however it might be called by your cloud provider). Then one would use cloud API or CLI to relocate this IP address to another host. For this reason, we’d suggest to collocate ProxySQL with the application. Each application server would be configured to connect to the local ProxySQL, using Unix sockets. As ProxySQL uses an angel process, ProxySQL crashes can be detected/restarted within a second. In case of hardware crash, that particular application server will go down along with ProxySQL. The remaining application servers can still access their respective local ProxySQL instances. This particular setup has additional features. Security – ProxySQL, as of version 1.4.8, does not have support for client-side SSL. It can only setup SSL connection between ProxySQL and the backend. Collocating ProxySQL on the application host and using Unix sockets is a good workaround. ProxySQL also has the ability to cache queries and if you are going to use this feature, it makes sense to keep it as close to the application as possible to reduce latency. We would suggest to use this pattern to deploy ProxySQL.
Typical setups
Let’s take a look at examples of highly available setups.
Single datacenter, MySQL replication
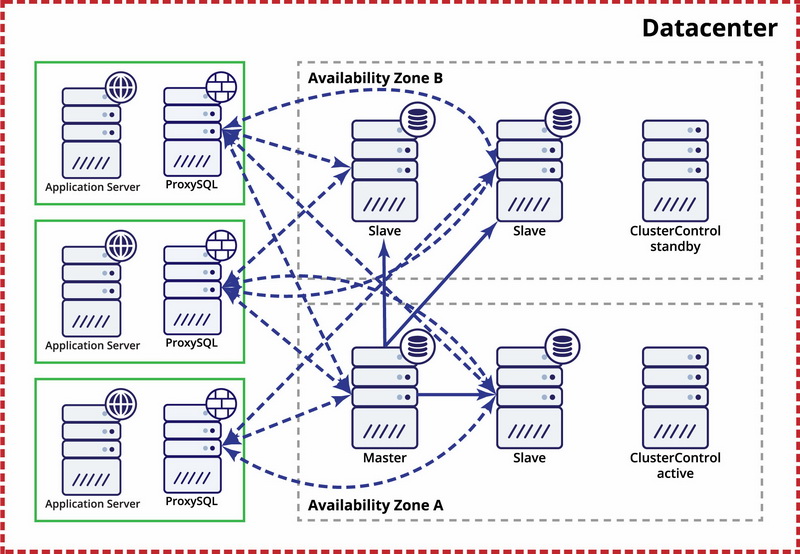
The assumption here is that there are two separate zones within the datacenter. Each zone has redundant and separate power, networking and connectivity to reduce the likelihood of two zones failing simultaneously. It is possible to set up a replication topology spanning both zones.
Here we use ClusterControl to manage the failover. To solve the split-brain scenario between availability zones, we collocate the active ClusterControl with the master. We also blacklist slaves in the other availability zone to make sure that automated failover won’t result in two masters being available.
Multiple datacenters, MySQL replication
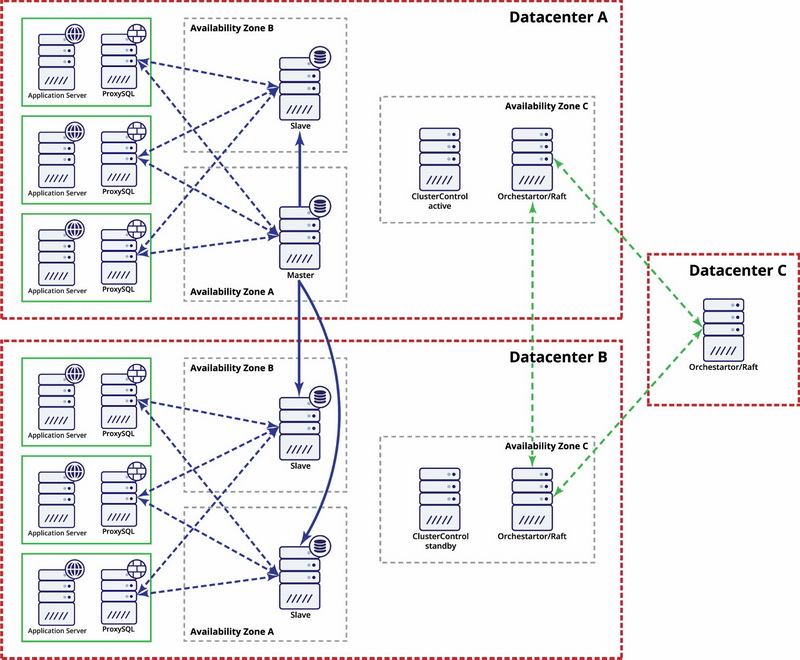
In this example we use three datacenters and Orchestrator/Raft for quorum calculation. You might have to write your own scripts to implement STONITH if master is in the partitioned segment of the infrastructure. ClusterControl is used for node recovery and management functions.
Multiple datacenters, Galera Cluster
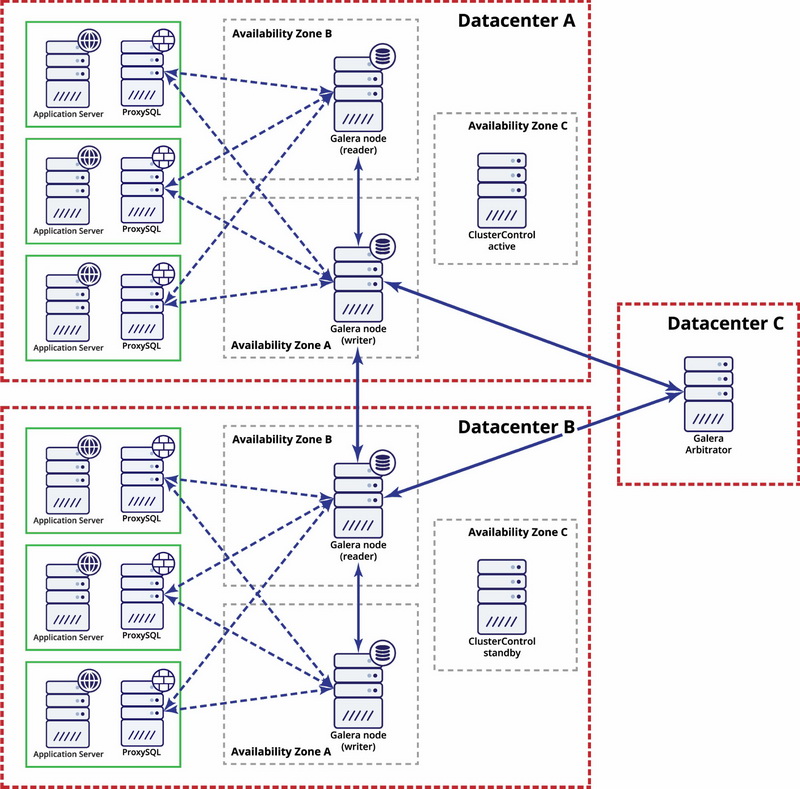
In this case we use three datacenters with a Galera arbitrator in the third one – this makes possible to handle whole datacenter failure and reduces a risk of network partitioning as the third datacenter can be used as a relay.
For further reading, take a look at the “How to Design Highly Available Open Source Database Environments” whitepaper and watch the webinar replay “Designing Open Source Databases for High Availability”.
via Planet MySQL
How to Make Your MySQL or MariaDB Database Highly Available on AWS and Google Cloud