http://img.youtube.com/vi/qmmnFe_IfKc/0.jpgThis is an updated version of the old video from back in 2017, revised for the Laravel 8, the latest Laravel Excel version, and Tailwind with Laravel Breeze.Laravel News Links
Ben Cook: PyTorch DataLoader Quick Start
PyTorch comes with powerful data loading capabilities out of the box. But with great power comes great responsibility and that makes data loading in PyTorch a fairly advanced topic.
One of the best ways to learn advanced topics is to start with the happy path. Then add complexity when you find out you need it. Let’s run through a quick start example.
What is a PyTorch DataLoader?
The PyTorch DataLoader class gives you an iterable over a Dataset. It’s useful because it can parallelize data loading and automatically shuffle and batch individual samples, all out of the box. This sets you up for a very simple training loop.
PyTorch Dataset
But to create a DataLoader, you have to start with a Dataset, the class responsible for actually reading samples into memory. When you’re implementing a DataLoader, the Dataset is where almost all of the interesting logic will go.
There are two styles of Dataset class, map-style and iterable-style. Map-style Datasets are more common and more straightforward so we’ll focus on them but you can read more about iterable-style datasets in the docs.
To create a map-style Dataset class, you need to implement two methods: __getitem__() and __len__(). The __len__() method returns the total number of samples in the dataset and the __getitem__() method takes an index and returns the sample at that index.
PyTorch Dataset objects are very flexible â they can return any kind of tensor(s) you want. But supervised training datasets should usually return an input tensor and a label. For illustration purposes, let’s create a dataset where the input tensor is a 3×3 matrix with the index along the diagonal. The label will be the index.
It should look like this:
dataset[3]
# Expected result
# {'x': array([[3., 0., 0.],
# [0., 3., 0.],
# [0., 0., 3.]]),
# 'y': 3}Remember, all we have to implement are __getitem__() and __len__():
from typing import Dict, Union
import numpy as np
import torch
class ToyDataset(torch.utils.data.Dataset):
def __init__(self, size: int):
self.size = size
def __len__(self) -> int:
return self.size
def __getitem__(self, index: int) -> Dict[str, Union[int, np.ndarray]]:
return dict(
x=np.eye(3) * index,
y=index,
)Very simple. We can instantiate the class and start accessing individual samples:
dataset = ToyDataset(10)
dataset[3]
# Expected result
# {'x': array([[3., 0., 0.],
# [0., 3., 0.],
# [0., 0., 3.]]),
# 'y': 3}If happen to be working with image data, __getitem__() may be a good place to put your TorchVision transforms.
At this point, a sample is a dict with "x" as a matrix with shape (3, 3) and "y" as a Python integer. But what we want are batches of data. "x" should be a PyTorch tensor with shape (batch_size, 3, 3) and "y" should be a tensor with shape batch_size. This is where DataLoader comes back in.
PyTorch DataLoader
To iterate through batches of samples, pass your Dataset object to a DataLoader:
torch.manual_seed(1234)
loader = torch.utils.data.DataLoader(
dataset,
batch_size=3,
shuffle=True,
num_workers=2,
)
for batch in loader:
print(batch["x"].shape, batch["y"])
# Expected result
# torch.Size([3, 3, 3]) tensor([2, 1, 3])
# torch.Size([3, 3, 3]) tensor([6, 7, 9])
# torch.Size([3, 3, 3]) tensor([5, 4, 8])
# torch.Size([1, 3, 3]) tensor([0])Notice a few things that are happening here:
- Both the NumPy arrays and Python integers are both getting converted to PyTorch tensors.
- Although we’re fetching individual samples in
ToyDataset, theDataLoaderis automatically batching them for us, with the batch size we request. This works even though the individual samples are in dict structures. This also works if you return tuples. - The samples are randomly shuffled. We maintain reproducibility by setting
torch.manual_seed(1234). - The samples are read in parallel across processes. In fact, this code will fail if you run it in a Jupyter notebook. To get it to work, you need to put it underneath a
if __name__ == "__main__":check in a Python script.
There’s one other thing that I’m not doing in this sample but you should be aware of. If you need to use your tensors on a GPU (and you probably are for non-trivial PyTorch problems), then you should set pin_memory=True in the DataLoader. This will speed things up by letting the DataLoader allocate space in page-locked memory. You can read more about it here.
Summary
To review: the interesting part of custom PyTorch data loaders is the Dataset class you implement. From there, you get lots of nice features to simplify your data loop. If you need something more advanced, like custom batching logic, check out the API docs. Happy training!
The post PyTorch DataLoader Quick Start appeared first on Sparrow Computing.
Planet Python
Visualizing Ammo Cost Trends Across Nine Popular Calibers
https://www.thefirearmblog.com/blog/wp-content/uploads/2021/10/ammo-cost-trends-180×180.png
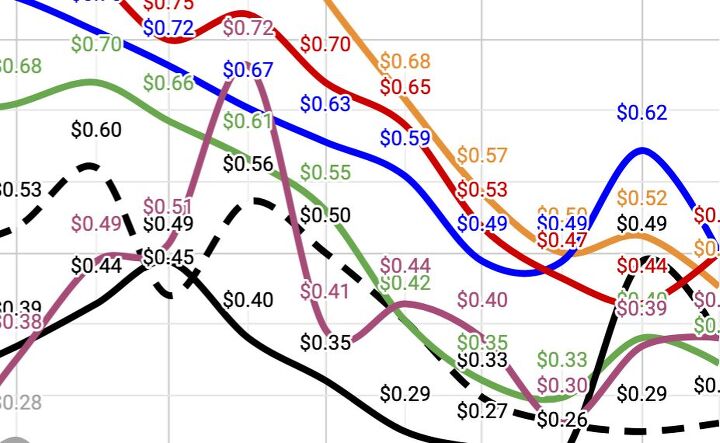 It’s no secret that the ammunition market has been volatile (to say the least) since the Covid pandemic took hold, but some calibers seem to be easing off while others rise. Redditor, Chainwaxologist, owns a web-based hunting and fishing retail store, FoundryOutdoors.com, so to keep his ammo cost and supply competitive, he set out to […]
It’s no secret that the ammunition market has been volatile (to say the least) since the Covid pandemic took hold, but some calibers seem to be easing off while others rise. Redditor, Chainwaxologist, owns a web-based hunting and fishing retail store, FoundryOutdoors.com, so to keep his ammo cost and supply competitive, he set out to […]
The post Visualizing Ammo Cost Trends Across Nine Popular Calibers appeared first on The Firearm Blog.
The Firearm Blog
Step-By-Step Guide to Deploying Laravel Applications on Virtual Private Servers
https://production.ams3.digitaloceanspaces.com/2021/09/Social-Sharing-photo-Template-1-14.png
Developing modern full-stack web applications has become much easier thanks to Laravel but deploying them on a real server is another story.
There are just so many options.
PaaS like Heroku or AWS Elastic Beanstalk, unmanaged virtual private servers, shared hosting, and so on.
Deploying a Laravel app on a shared server using cPanel is as easy as zipping up the source code along with all the dependencies and uploading it to the server. But on shared hosting, you don’t have much control over the server.
PaaS like Heroku or AWS Elastic Beanstalk strikes a good balance between ease of usage and control, but they can be expensive at times. A standard 1x dyno from Heroku, for example, costs $25 per month and comes with only 512MB of RAM.
Unmanaged virtual private servers are affordable and provide a lot of control on the server. You can avail a server with 2GB of RAM, 20GB of SSD space, and 2TB of transfer bandwidth, costing only $15 per month.
Now the problem with unmanaged virtual private servers is that they are unmanaged. You’ll be responsible for installing all necessary software, configuring them, and keeping them updated.
In this article, I’ll guide you step-by-step in the process of how to deploy a Laravel project on an unmanaged virtual private server (we’ll refer to it as VPS from now on). If you want to check out the benefits of the framework first, go ahead and get an answer to the question of why use the Laravel framework. If you are ready, without any further ado, let’s jump in.
Prerequisites
The article assumes that you have previous experience with working with the Linux command-line. The server will use Ubuntu as its operating system, and you’ll have to perform all the necessary tasks from the terminal. The article also expects you to understand basic concepts like Sudo, file permissions, differences between a root and non-root user, and git.
Project Code and Deployment Plan
I’ve built a dummy project for this article. It’s a simple question board application where users can post a question, and others can answer that question. You can consider this a dumbed-down version of StackOverflow.
The project source code is available on https://github.com/fhsinchy/guide-to-deploying-laravel-on-vps repository. Make a fork of this repository and clone it on your local computer.
Once you have a copy of the project on your computer, you’re ready to start the Laravel deployment process. You’ll start by provisioning a new VPS and setting up a way for pushing the source from your local computer to the server.
Provisioning a New Ubuntu Server
There are several VPS providers out there, such as DigitalOcean, Vultr, Linode, and Hetzner. Although working with an unmanaged VPS is more or less the same across providers, they don’t provide the same kind of services.
DigitalOcean, for example, provides managed database services. Linode and Vultr, on the other hand, don’t have such services. You don’t have to worry about these differences.
I’ll demonstrate only the unmanaged way of doing things. So regardless of the provider, you’re using, the steps should be identical.
Before provisioning a new server, you’ll have to generate SSH keys.
Generating New SSH Keys
According to Wikipedia – “Secure Shell (SSH) is a cryptographic network protocol for operating network services securely over an unsecured network.” It allows you to connect to a remote server using a password or a key-pair.
If you’re already familiar with SSH and have previously generated SSH key-pairs on your computer, you may skip this subsection. To generate a new key-pair on macOS, Linux, or Windows 10 machines, execute the following command:
ssh-keygen -t rsaYou’ll see several prompts on the terminal. You can go through them by pressing enter. You don’t have to put any password either. Once you’ve generated the key-pair, you’ll find a file named id_rsa.pub inside the ~/.ssh/ directory. You’ll need this file when provisioning a new VPS.
Provisioning a New VPS
I’ve already said there are some differences between the VPS service providers, so if you want to be absolutely in line with this article, use DigitalOcean.
A single virtual private server on DigitalOcean is known as a droplet. On Vultr, it’s called an instance, and on Linode, it’s called a linode. Log into your provider of choice and create a new VPS. Use Ubuntu 20.04 LTS as the operating system.
For size, pick the one with 1GB of RAM and 25GB of SSD storage. It should cost you around $5 per month. For the region, choose the one closest to your users. I live in Bangladesh, and most of my users are from here, so I deploy my applications in the Singapore region.
Under the SSH section, create a new SSH key. Copy the content from the ~/.ssh/id_rsa.pub file and paste it as the content. Put a descriptive name for the key and save.
You can leave the rest of the options untouched. Most of the providers come with an automatic backup service. For this demonstration, keep that option disabled. But in a real scenario, it can be a lifesaver. After the process finishes, you’ll be ready to connect to your new server using SSH.
Performing Basic Setup
Now that your new server is up and running, it’s time to do some basic setup. First, use SSH with the server IP address to log in as the root user.
ssh [email protected]You can find the server’s IP address on the dashboard or inside the server details. Once you’re inside the server, the first thing to do is create a new non-root user.
By default, every server comes with the root user only. The root user, as you may already know, is very mighty. If someone manages to hack your server and logs in as the root user, the hacker can wreak havoc. Disabling login for the root user can prevent such mishaps.
Also, logging in using a key-pair is more secure than logging in using a password. So, disabling logging in using a password should be disabled for all users.
To create a new user from the terminal, execute the following command inside your server:
adduser nonrootThe name nonroot can be anything you want. I used nonroot as the name to make the fact clear that this is a non-root user. The adduser program will ask for a password and several other information. Put a strong password and leave the others empty.
After creating the user, you’ll have to add this new user to the sudo group. Otherwise, the nonroot user will be unable to execute commands using sudo.
usermod -aG sudo nonrootIn this command, sudo is the group name, and nonroot is the username. Now, if you try to log into this account, you’ll face a permission denied error.
It happens because most of the VPS providers disable login using a password when you add an SSH key to the server, and you haven’t configured the new user to use SSH key-pairs. One easy way to fix this is to copy the content of /root/.ssh directory to the /home/nonroot/.ssh directory. You can use the rsync program to do this.
rsync --archive --chown=nonroot:nonroot /root/.ssh /home/nonrootThe –archive option for rsync copies directories recursively preserving symbolic links, user and group ownership, and timestamps. The –chown option sets the nonroot user as the owner in the destination. Now you should be able to log in as the new user using SSH.
After logging in as a non-root user, you should update the operating system, including all the installed programs on the server. To do so, execute the following command:
sudo apt update && sudo apt upgrade -y && sudo apt dist-upgrade -yDownloading and installing the updates will take a few minutes. During this process, if you see a screen titled “Configuring openssh-server” asking about some file changes, select the “keep the local version currently installed” option and press enter.
After the update process finishes, reboot the server by executing the sudo reboot command. Wait a few minutes for the server to boot again and log back in as a non-root user.
Deploying Code on the Server
After completing the basic setups, the next thing you’ll tackle is deploying code on the server. I’ve seen people cloning the repository somewhere on the production server and logging into the server to perform a pull whenever there are some new changes to the code.
There is a much better way of doing this. Instead of logging into the server to perform a pull, you can use the server itself as a repository and push code directly to the server. You can also automate the post-deployment steps like installing dependencies, running the migrations, and so on, which will make the Laravel deploy to server an effortless action. But before doing all these, you’ll first have to install PHP and Composer on the server.
Installing PHP
You can find a list of PHP packages required by Laravel on the official docs. To install all these packages, execute the following command on your server:
sudo apt install php7.4-fpm php7.4-bcmath php7.4-json php7.4-mbstring php7.4-xml -yDepending on whether you’re using MySQL or PostgreSQL, or SQLite in your project, you’ll have to install one of the following packages:
sudo apt install php7.4-mysql php7.4-pgsql php7.4-sqlite3 -yThe following package provides support for the Redis in-memory databases:
sudo apt install php7.4-redisApart from these packages, you’ll also need php-curl, php-zip, zip, unzip, and curl utilities.
sudo apt install zip unzip php7.4-zip curl php7.4-curl -yThe question bank project uses MySQL as its database system and Redis for caching and running queues, so you’ll have to install the php7.4-mysql and the php7.4-redis packages.
Depending on the project, you may have to install more PHP packages. Projects that work images, for example, usually depend on the php-gd package. Also, you don’t have to mention the PHP version with every package name. If you don’t specify a version number, APT will automatically install whatever is the latest.
At the writing of this article, PHP 7.4 is the latest one on Ubuntu’s package repositories but considering that the question board project requires PHP 7.4 and PHP 8 may become the default in the future, I’ve specified the version number in this article.
Installing Composer
After installing PHP and all the required packages on the server, now you’re ready to install Composer. To do so, navigate to the official composer download page and follow the command-line installation instructions or execute the following commands:
php -r "copy('https://getcomposer.org/installer', 'composer-setup.php');"
sudo php composer-setup.php --install-dir /usr/local/bin --filename composer
php -r "unlink('composer-setup.php');"Now that you’ve installed both PHP and Composer on your server, you’re ready to configure the automated deployment of your code.
Deploying Code Using Git
For automating code deployment on the server, log in as a non-root user and create a new directory under the /home/nonroot directory. You’ll use this directory as the repository and push production code to it.
mkdir -p /home/nonroot/repo/question-board.gitThe -p option to the mkdir command will create any nonexistent parent repository. Next, cd into the newly created directory and initialize a new bare git repository.
cd /home/nonroot/repo/question-board.git
git init --bareA bare is the same as a regular git repository, except it doesn’t have a working tree. The practical usage of such a git repository is as a remote origin. Don’t worry if you don’t understand what I said just now. Things will become lucid as you keep going.
Assuming you’re still inside the /home/nonroot/repo/question-board.git directory, cd inside the hooks subdirectory and create a new file called post-receive.
cd hooks
touch post-receiveFiles inside this directory are regular shell scripts that git invokes when some major event happens on a repository. Whenever you push some code, git will wait until all the code has been received and then call the post-receive script.
Assuming you’re still inside the hooks directory, open the post-receive script by executing the following command:
nano post-receiveNow update the script’s content as follows:
#!/bin/sh
sudo /sbin/deployAs you may have already guessed, /sbin/deploy is another script you’ll have to create. The /sbin directory is mainly responsible for storing scripts that perform administrative tasks. Go ahead and touch the /sbin/deploy script and open it using the nano text editor.
sudo touch /sbin/deploy
sudo nano /sbin/deployNow update the script’s content as follows:
#!/bin/sh
git --work-tree=/srv/question-board --git-dir=/home/nonroot/repo/question-board.git checkout -fEvident by the #!/bin/sh line, this is a shell script. After that line, the only line of code in this script copies the content of the /home/nonroot/repo/question-board.git repository to the /srv/question-board directory.
Here, the –work-tree option specifies the destination directory, and the –git-dir option specifies the source repository. I like to use the /srv directory for storing files served by this server. If you want to use the /var/www directory, go ahead.
Save the file by hitting Ctrl + O and exit nano by hitting Ctrl + X key combination. Make sure that the script has executable permission by executing the following command:
sudo chmod +x post-receiveThe last step to make this process functional is creating the work tree or the destination directory. To do so, execute the following command:
sudo mkdir /srv/question-boardNow you have a proper work tree directory, a bare repository, and a post-hook that in turn calls the /sbin/deploy script with sudo. But, how would the post-receive hook invoke the /sbin/deploy script using sudo without a password?
Open the /etc/sudoers file on your server using the nano text editor and append the following line of code at the end of the file:
nonroot ALL=NOPASSWD: /sbin/deployThis line of code means that the nonroot user will be able to execute the /sbin/deploy script with sudo on ALL hosts with NOPASSWD or no password. Save the file by pressing Ctrl + O and exit nano by pressing the Ctrl + K key combination.
Finally, you’re ready to push the project source code. Assuming that you’ve already forked and cloned the https://github.com/fhsinchy/guide-to-deploying-laravel-on-vps repository on your local system, open up your terminal on the project root and execute the following command:
git remote add production ssh://[email protected]/home/nonroot/repo/question-board.gitMake sure to replace my IP address with the IP address from your server. Now assuming that the stable code is no the master branch, you can push code to the server by executing the following command:
git push production masterAfter sending the code to the server, log back in as a non-root user and cd into the /srv/question-board directory. Use the ls command to list out the content, and you should see that git has successfully checked out your project code.
Automating Post Deployment Steps
Congratulations on you being able to deploy Laravel project on the server directly but, is that enough? What about the post-deployment steps? Tasks like installing or updating dependencies, migrating the database, caching the views, configs, and routes, restarting workers, and so on.
Honestly, automating these tasks is much easier than you may think. All you’ve to do is create a script that does all these for you, set some permissions, and call that script from inside the post-receive hook.
Create another script called post-deploy inside the /sbin directory. After creating the file, open it inside the nano text editor.
sudo touch /sbin/post-deploy
sudo nano /sbin/post-deployUpdate the content of the post-deploy script as follows. Don’t worry if you don’t clearly understand everything. I’ll explain each line in detail.
#!/bin/sh
cd /srv/question-board
cp -n ./.env.example ./.env
COMPOSER_ALLOW_SUPERUSER=1 composer install --no-dev --optimize-autoloader
COMPOSER_ALLOW_SUPERUSER=1 composer update --no-dev --optimize-autoloaderThe first line changes the working directory to the /srv/question-board directory. The second line makes a copy of the .env.example file. The -n option makes sure that the cp command doesn’t override a previously existing file.
The third and fourth commands will install all the necessary dependencies and update them if necessary. The COMPOSER_ALLOW_SUPERUSER environment variable disables a warning about running the composer binary as root.
Save the file by pressing Ctrl + O and exit nano by pressing Ctrl + X key combination. Make sure that the script has executable permission by executing the following command:
sudo chmod +x /sbin/post-deployOpen the /home/nonroot/repo/question-board.git/hooks/post-receive script with nano and append the following line after the sudo /sbin/deploy script call:
sudo /sbin/post-deployMake sure that you call the post-deploy script after calling the deploy script. Save the file by pressing Ctrl + O and exit nano by pressing the Ctrl + K key combination.
Open the /etc/sudoers file on your server using the nano text editor once again and update the previously added line as follows:
nonroot ALL=NOPASSWD: /sbin/deploy, /sbin/post-deploySave the file by pressing Ctrl + O and exit nano by pressing the Ctrl + K key combination. You can add more post deploy steps to this script if necessary.
To test the new post-deploy script, make some changes to your code, commit the changes and push to the production master branch. This time you’ll see composer packages installation progress on the terminal and outputs from other artisan calls.
Once the deployment process finishes, log back into the server, cd into the /srv/question-board directory, and list the content by executing the following command:
ls -laAmong other files and folders, you’ll see a newly created vendor directory and an env file. At this point, you can generate the application encryption key required by Laravel. To do so, execute the following command:
sudo php artisan key:generateIf you look at the content of the .env file using the nano text editor, you’ll see the APP_KEY value populated with a long string.
Installing and Configuring NGINX
Now that you’ve successfully pushed the source code to the server, the next step is to install a web server and configure it to serve your application. I’ll use NGINX in the article. If you want to use something else like Apache, you’ll be on your own.
This article will strictly focus on configuring the webserver for serving a Laravel application and will not discuss NGINX-related stuff in detail. NGINX itself is a very complex software, and if you wish to learn NGINX from the ground up, The NGINX Handbook is a solid resource.
To install NGINX on your Ubuntu server, execute the following command:
sudo apt install nginx -yThis command should install NGINX and should also register as a systemd service. To verify, you can execute the following command:
sudo systemctl status nginxYou should see something as follows in the output:
You can regain control of the terminal by hitting q on your keyboard. Now that NGINX is running, you should see the default welcome page of NGINX if you visit the server IP address.
You’ll have to change the NGINX configuration to serve your Laravel application instead. To do so, create a new file /etc/nginx/sites-available/question-board and open the file using the nano text editor.
sudo touch /etc/nginx/sites-available/question-board
sudo nano /etc/nginx/sites-available/question-boardThis file will contain the NGINX configuration code for serving the question board application. Configuring NGINX from scratch can be difficult, but the official Laravel docs have a pretty good configuration. Follows is the code copied from the docs:
server {
listen 80;
server_name 104.248.157.172;
root /srv/question-board/public;
add_header X-Frame-Options "SAMEORIGIN";
add_header X-Content-Type-Options "nosniff";
index index.php;
charset utf-8;
location / {
try_files $uri $uri/ /index.php?$query_string;
}
location = /favicon.ico { access_log off; log_not_found off; }
location = /robots.txt { access_log off; log_not_found off; }
error_page 404 /index.php;
location ~ \.php$ {
fastcgi_pass unix:/var/run/php/php7.4-fpm.sock;
fastcgi_param SCRIPT_FILENAME $realpath_root$fastcgi_script_name;
include fastcgi_params;
}
location ~ /\.(?!well-known).* {
deny all;
}
}You don’t have to make any changes to this code except the first two lines. Make sure you’re using the IP address from your server as the server_name , and the root is pointing to the correct directory. You’ll replace this IP address with a domain name in a later section.
Also, inside the location ~ \.php$ { } block, make sure that the fastcgi_pass directive is pointing to the correct PHP version. In this demonstration, I’m using PHP 7.4, so this configuration is correct. If you’re using a different version, like 8.0 or 8.1, update the code accordingly.
If you cd into the /etc/nginx directory and list out the content using the ls command, you’ll see two folders named sites-available and sites-enabled.
The sites-available folder holds all the different configuration files serving applications (yes, there can be multiple) from this server.
The sites-enabled folder, on the other hand, contains symbolic links to the active configuration files. So if you do not make a symbolic link of the /etc/nginx/sites-available/question-board file inside the sites-enabled folder, it’ll not work. To do so, execute the following command:
sudo ln -s /etc/nginx/sites-available/question-board /etc/nginx/sites-enabled/question-board
sudo rm /etc/nginx/sites-enabled/defaultThe second command gets rid of the default configuration file to avoid any unintended conflict. To test if the configuration code is okay or not, execute the following command:
sudo nginx -tIf everything’s alright, reload the NGINX configuration by executing the following command:
sudo nginx -s reloadIf you visit your server IP address, you’ll see that NGINX is serving your application correctly but the application is throwing a 500 internal server error.
As you can see, the application is trying to write to the logs folder but fails. It happens because the root user owns the /srv/question-board directory, and the www-data user owns the NGINX process. To make the /srv/question-board/storage directory writable by the application, you’ll have to alter the directory permissions.
Configuring Directory Permissions
There are different ways of configuring directory permissions in a Laravel project but, I’ll show you the one I use. First, you’ll have to assign the www-data user that owns the NGINX process as the owner of the /srv/question-board directory as well. To do so, execute the following command:
sudo chown -R :www-data /srv/question-boardThen, set the permission of the /srv/question-board/storage to 755, which means read and execute access for all users and write access for the owner by executing the following command:
sudo chmod -R 775 /srv/question-board/storageFinally, there is one more subdirectory that you have to make writable. That is the /srv/question-board/bootstrap/cache directory. To do so, execute the following command:
sudo chmod -R 775 /srv/question-board/bootstrap/cacheIf you go back to the server IP address now and refresh, you should see that the application is working fine.
Installing and Configuring MySQL
Now that you’ve successfully installed and configured the NGINX web server, it’s time for you to install and configure MySQL. To do so, install the MySQL server by executing the following command:
sudo apt install mysql-server -yAfter the installation process finishes, execute the following command to make your MySQL installation more secure:
sudo mysql_secure_installationFirst, the script will ask if you want to use the validate password component or not. Input “Y” as the answer and hit enter. Then, you’ll have to set the desired level of password difficulty. I recommend setting it as high. Although picking a hard-to-guess password every time you want to create a new user can be annoying, but for the sake of security, roll with it. In the next step, set a secure password for the root user. You can put “Y” as the answer for the rest of the questions. Give the questions a read if you want to.
Now, before you can log into your database server as root, you’ll have to switch to the root user. To do so, execute the following command:
sudo suLog into your database server as root by executing the following command:
mysql -u rootOnce you’re in, create a new database for the question board application by executing the following SQL code:
CREATE DATABASE question_board;Next, create a new database user by executing the following SQL code:
CREATE USER 'nonroot'@'localhost' IDENTIFIED BY 'password';Again, I used the name nonroot to clarify that this is a non-root user. You can use whatever you want as the name. Also, replace the word password with something more secure.
After that, provide the user full privilege of the question_board database to the newly created user by executing the following SQL code:
GRANT ALL PRIVILEGES ON question_board . * TO 'nonroot'@'localhost';In this code, question_board.* means all the tables of the question_board database. Finally, quit the MySQL client by executing the \q command and exit the root shell by invoking the exit command.
Now, try logging in as the nonroot user by executing the following command:
mysql -u nonroot -pThe MySQL client will ask for the password. Use the password you put in when creating the nonroot user. If you manage to log in successfully, exit the MySQL client by executing the \q command.
Now that you have a working database server, it’s time to configure the question board project to make use of it. First, cd into the /srv/question-board directory and open the env file using the nano text editor:
cd /srv/question-board
sudo nano .envUpdate the database configuration as follows:
DB_CONNECTION=mysql
DB_HOST=localhost
DB_PORT=3306
DB_DATABASE=question_board
DB_USERNAME=nonroot
DB_PASSWORD=passwordMake sure to replace the username and password with yours. Save the file by pressing Ctrl + O and exit nano by pressing Ctrl + X key combination. To test out the database connection, try migrating the database by executing the following command:
php artisan migrate --forceIf everything goes fine, that means the database connection is working. The project comes with two seeder classes, one for seeding the admin user and another for the categories. Execute the following commands to run them:
php artisan db:seed --class=AdminUserSeeder
php artisan db:seed --class=CategoriesSeederNow, if you visit the server IP address and navigate to the /questions route, you’ll see the list of categories. You’ll also be log in as the admin user using the following credentials:
email: [email protected]
password: passwordIf you’ve been working with Laravel for a while, you may already know that it is common practice to add new migration files when there is a database change. To automate the process of running the migrations on every deployment, open the /sbin/post-deploy script using nano once again and append the following line at the end of the file:
php artisan migrate --forceThe –force option will suppress an artisan warning about running migrations on a production environment. Unlike migrations, seeders should run only once. If you add new seeders on later deployments, you’ll have to run them manually.
Configure Laravel Horizon
The question board project comes with Laravel Horizon pre-installed and pre-configured. Now that you have Redis up and running, you’re ready to start processing jobs.
The official docs suggest using the supervisor program for running Laravel Horizon on a production server. To install the program, execute the following command:
sudo apt install supervisor -ySupervisor configuration files live within your server’s /etc/supervisor/conf.d directory. Create a new file /etc/supervisor/conf.d/horizon.conf and open it using the nano text editor:
sudo touch /etc/supervisor/conf.d/horizon.conf
sudo /etc/supervisor/conf.d/horizon.confUpdate the file’s content as follows:
[program:horizon]
process_name=%(program_name)s
command=php /srv/question-board/artisan horizon
autostart=true
autorestart=true
user=root
redirect_stderr=true
stdout_logfile=/var/log/horizon.log
stopwaitsecs=3600Save the file by pressing Ctrl + O and exit nano by pressing the Ctrl + X key combination. Now, execute the following commands to update the supervisor configuration and starting the horizon process:
sudo supervisorctl reread
sudo supervisorctl update
sudo supervisorctl start horizonTo test out if Laravel Horizon is running or not, visit your server’s IP address and navigate to the /login page. Log in as the admin user and navigate to the /horizon route. You’ll see Laravel Horizon in the active state.
I’ve configured Laravel Horizon to only let the admin user in, so if you log in with some other user credential, you’ll see a 403 forbidden error message on the /horizon route.
One thing that catches many people off guard is that if you make changes to your jobs, you’ll have to restart Laravel Horizon to read those changes. I recommend adding a line to the /sbin/post-deploy script to reinitiate the Laravel Horizon process on every deployment.
To do so, open the /sbin/post-deploy using the nano text editor and append the following line at the end of the file:
sudo supervisorctl restart horizonThis command will stop and restart the Laravel Horizon process on every deployment.
Configuring a Domain Name With HTTPS
For this step to work, you’ll have to own a custom domain name of your own. I’ll use the questionboard.farhan.dev domain name for this demonstration.
Log into your domain name provider of choice and go to the DNS settings for your domain name. Whenever you want a domain name to point to a server’s IP address, you need to create a DNS record of type A.
To do so, add a new DNS record with the following attributes:
Type: A Record
Host: questionboard
Value: 104.248.157.172
Make sure to replace my IP address with yours. If you want your top-level domain to point to an IP address instead of a subdomain, just put a @ as the host.
Now go back to your server and open the /etc/nginx/sites-available/questionboard config file using the nano text editor. Remove the IP address from the server_name directive and write your domain name. Do not put HTTP or HTTPS at the beginning.
You can put multiple domain names such as the top-level domain and the www subdomain separated by spaces. Save the configuration file by pressing Ctrl + O and Ctrl + X key combination. Reload NGINX configuration by executing the following command:
sudo nginx -s reloadNow you can visit your application using your domain name instead of the server’s IP address. To enable HTTPS on your application, you can use the certbot program.
To do so, install certbot by executing the following command:
sudo snap install --classic certbotIt is a python program that allows you to use free SSL certificates very easily. After installing the program, execute the following command to get a new certificate:
sudo certbot --nginxFirst, the program will ask for your email address. Next, it’ll ask if you agree with the terms and agreements or not.
Then, It’ll ask you about sharing your email address with the Electronic Frontier Foundation.
In the third step, the program will read the NGINX configuration file and extract the domain names from the server_name directive. Look at the domain names it shows and press enter if they are all correct. After deploying the new certificate, the program will congratulate you, and now you’ve got free HTTPS protection for 90 days.
After 90 days, the program will attempt to renew the certificate automatically. To test the auto-renew feature, execute the following command:
sudo certbot renew --dry-runIf the simulation succeeds, you’re good to go.
Configuring a Firewall
Having a properly configured firewall is very important for the security of your server. In this article, I’ll show you how you can configure the popular UFW program.
UFW stands for uncomplicated firewall, and it comes by default in Ubuntu. You’ll configure UFW to, by default, allow all outgoing traffic from the server and deny all incoming traffic to the server. To do so, execute the following command:
sudo ufw default deny incoming
sudo ufw default allow outgoingDenying all incoming traffic means that no one, including you, will be able to access your server in any way. The next step is to allow incoming requests in three specific ports. They are as follows:
Port 80, used for HTTP traffic.
Port 443, used for HTTPS traffic.
Port 22, used for SSH traffic.
To do so, execute the following commands:
sudo ufw allow http
sudo ufw allow https
sudo ufw allow sshFinally, enable UFW by executing the following command:
sudo ufw enableThat’s pretty much it. Your server now only allows HTTP, HTTPS, and SSH traffic coming from the outside, making your server a bit more secure.
Laravel Post-deployment Optimizations
Your application is now almost ready to accept requests from all over the world. One last step that I would like to suggest is caching the Laravel configuration, views, and routes for better performance.
To do so, open the /sbin/post-deploy script using the nano text editor and append the following lines at the end of the file:
php artisan config:cache
php artisan route:cache
php artisan view:cacheNow, on every deployment, the caches will be cleared and renewed automatically. Also, make sure to set the APP_ENV to production and APP_DEBUG to false inside the env file. Otherwise, you may unintentionally compromise sensitive information regarding your server.
Conclusion
I would like to thank all Laravel developers for the time they’ve spent reading this article. I hope you’ve enjoyed it and have learned some handy stuff regarding application deployment. If you want to learn more about NGINX, consider checking out my open-source NGINX Handbook with tons of fun content and examples.
Also, if you want to broaden your knowledge of Laravel, you can check the Laravel vs Symfony, the Laravel Corcel, and Laravel Blockhain articles.
If you have any questions or confusion, feel free to reach out to me. I’m available on Twitter and LinkedIn and always happy to help. Till the next one, stay safe and keep on learning.
Laravel News Links
The US economy is in imminent danger of seizing up solid
http://img.youtube.com/vi/E7t5yj1rScI/0.jpg
I’ve always said that logistics are the true bellwether of many economic issues. If logistics (a.k.a. the ability to provide enough supply to meet demand) are working, the economy is lubricated and runs smoothly. If they’re not, the economy is in danger of seizing up like an engine running without adequate oil supply. General Omar Bradley‘s famous observation is as true in economic disciplines as it is in military: "Amateurs study tactics. Professionals study logistics."
Let me put the next paragraph in big, bold, black letters to emphasize how serious I am.
Right now, our logistics snarl-up is posing the real danger of seizing up our economy – and the danger is growing worse by the day. The next two to three months are likely to prove absolutely critical. If I were talking about the potential for military conflict, I’d call this article a WAR WARNING. In economic terms, I suppose I’ll have to call it a COLLAPSE WARNING.
Yes, it is getting that bad – and it all boils down to logistics. The problem is that there are too many goods seeking shipment, and not enough containers, vessels, vehicles and aircraft – not to mention people – available to move them. If a container ship is anchored off a Chinese port for a month, waiting to load cargo, then sails across the Pacific to a US port, then anchors off one of our harbors for another month to await unloading, it’s occupied for three to four months with a single cargo. Under normal circumstances, it’d carry three to four cargoes during that same period – but the clogged-up arteries of the world’s transport and logistics system simply can’t cope with that any more.
CNBC offers this overview of the problems being experienced by container ships.
The result of the clogged-up ocean shipping system is that, due to delays and waiting periods, literally hundreds of the biggest cargo ships in the world are forced to carry no more than a quarter of the cargo they’d normally transport during any given year. All those manufacturers and countries that gleefully exported their manufacturing capacity to China or Asia in past years are now sitting with goods overseas that they can’t get to the customers who want them. That’s the living definition of a logistics bottleneck, right there. Some high-value, low-bulk items can be transferred to aircraft for shipment (at much greater expense), but that doesn’t apply to many heavier or bulkier manufactured goods. They have to wait for a ship, or take the railroad from China across Siberia and Russia to Europe, and be distributed there or sent on by ship to the USA and elsewhere – but the ships to carry them are, as mentioned above, in drastically short supply.
Here in the USA, ships are waiting one to two months to get off-loaded; then their containers are sitting in harbors, waiting for rail or road transport to their destinations. However, land transportation is also backlogged, struggling to cope with the huge influx of containers and cargo. It’s not just at the harbors, either. Railroad companies have only so many freight cars, and road transport companies have only so many trucks that can carry containers. They may want to order more, but the companies that make them often rely on raw materials and parts from – guess where? – CHINA, or other overseas manufacturers. (For example, almost every rail car relies on computer chips to control its brakes, send signals to the engine if it has a problem, etc. The chip shortage currently affecting motor vehicle manufacturers is affecting rail car manufacturers, too.)
Here’s a report of how rail congestion in and near Chicago is affecting one small business – and it’s far from alone.
It’s gotten to the point where goods are being delivered to stores in this country, and bought by anxious customers before they’re even put out on the shelves. That happened to me just yesterday. I wanted to buy a couple of 5-gallon cans of kerosene for our newly-purchased heater, but no store in the big city nearby had any in stock – just smaller plastic 1- and 2½-gallon containers. Eventually, Tractor Supply’s national Web site said that its local store had the cans in stock, so I went straight there. The assistants inside all said that no, they were out of stock: but when I insisted, they went to the rear to check – and found that six cans had just been delivered that morning. They brought back two for me, only to find another customer had just arrived, having checked online as I had, and also wanted two. They ended up having only two out of six to put on the shelves, and I learned later those sold within the hour. They don’t know when they’ll be getting more in; they’re dependent on their regional office to send what they can, when they can, and they’re never sure what will arrive on that day’s truck.
These aren’t isolated incidents or rare examples. This sort of thing is happening more and more often, all over the country. The pipelines of supply are clogging up, so that most places can’t get enough of what they want, or know for sure what they’re getting and when they’re getting it. I wrote about a number of examples in my recent articles on supply chain problems, and I’m hearing more and more complaints like that.
If the supply pipeline gets much more clogged – and it’s getting worse almost by the day – there will come a time when nothing can move. The deadweight hanging over the system will squash it flat, and everything will come to a grinding halt.
Let me try to paint the broad picture as best I can by citing several articles that, taken together, provide enough flashing red lights and economic sirens to scare anybody.
Not only were people locked down [during the COVID-19 pandemic], but society and therefore practically the whole economy was forcefully paused. The problem here is that there is no "Pause button" for the economy. It may sound easy for politicians, who have no conception of how the real world works. But you cannot simply pause a business. You also cannot pause the supply chain. If you have ever run a business you know that being an entrepreneur is not a steady state but a changing process. It is a constant struggle to get money to come in so that you can cover costs that you’ve assumed long ago. That’s what entrepreneurs and businesses do. They assume costs and imagine they will be paid for their efforts later, and paid more than the cost they already assumed.
In other words, if you "pause," a business, the costs remain but you get no revenue. How are you going to pay those bills when everything is on pause? You cannot. This is perhaps easy to understand … so easy that even some politicians grasp the concept. So many countries like the United States have offered relief in the form of loans to businesses. Of course, such schemes come with the usual cronyism and favoritism. The loans often do not end up in the hands of those intended. They also shift power and influence away from the market to the bureaucrats in government. Or to put it differently, businesses survive or go under as decided by bureaucrats, not by consumers.
There is more than simply money. Imagine food processing and the beef farmer when the politicians press Pause, which stops businesses from dealing with slaughtering, cutting, processing, and shipping meat. But it doesn’t stop the farming. The farmer’s animals will not stop growing and will not stop eating because the economy is paused. The farmer will go bankrupt because he needs to cover their food, water, and care without being able to sell any beef. Even if he has savings to cover the expense, the meat will lose quality and value as the cows grow older than their prime. At the same time, no meat is reaching the shelves in the stores. So while the farmer is stuck with costs he cannot cover because he cannot sell the meat he produces, consumers cannot find meat in stores. Consequently, we experience a shortage of food, while at the same time farmers and other producers have surpluses that they cannot afford to keep and are unable to sell. What a ludicrous situation.
The effect of this is of course that the farmer will not be able to rise again as the politicians press Play on the economy and beef processing is resumed. He will not have been able to make those continuous investments in his business in order to meet future demand for meat. After all, he was stuck with additional costs and no revenue. So pressing Play will not solve the food shortage.
The same story can be told for other types of businesses as well. You cannot stop the freighter that is on its way around the world. You cannot store logs of timber waiting for the sawmill. You cannot pause mines and smelting plants. And if one task can be paused, it affects the other task in the supply chain. The longer the lockdown, the more businesses would have failed and the supply chains lain in shambles. This is an enormous loss. While it can be rebuilt, it can only be so at an enormous expense. And it still requires that there are people with the know-how and willingness to start such businesses again. Can we rely on them to rise and try again, even after they have been crushed?
BLOOMBERG: "Europe’s Energy Crisis is Coming for the Rest of the World, Too"
This winter, the world will be fighting over something that’s invisible, yet rarely so vital—and in alarmingly shorter supply.
Nations are more reliant than ever on natural gas to heat homes and power industries amid efforts to quit coal and increase the use of cleaner energy sources. But there isn’t enough gas to fuel the post-pandemic recovery and refill depleted stocks before the cold months. Countries are trying to outbid one another for supplies as exporters such as Russia move to keep more natural gas home. The crunch will get a lot worse when temperatures drop.
The crisis in Europe presages trouble for the rest of the planet as the continent’s energy shortage has governments warning of blackouts and factories being forced to shut.
. . .
American exporters are poised to ship more LNG than ever as new projects come online toward the end of the year. But as more gas goes abroad, less will be available at home. Even though gas prices have been notably lower in the U.S. than in Europe and Asia, they are trading near the highest level since 2014. Gas inventories are running below their five-year seasonal average, yet U.S. shale drillers are reluctant to boost production out of concern that would crimp their profitability and put off investors.
FINANCIAL SURVIVAL NETWORK: "Get Ready for Non-Transitory Inflation: Ten Things About to Shoot Up in Price"
Transportation A large part of our personal budgets are consumed by getting from point a to point b. The cost of doing this has risen and will rise even higher. With gasoline prices up a whopping 85% in the past 12 months, commuters are already feeling the bite. Politicians often increase gasoline excise taxes when seeking more revenue. Same with liquor excise taxes. With electric vehicles expected to capture higher market share, these taxes will have to be raised to make up the difference. In addition, tolls will also increase, to pay higher operating and labor costs in running and maintaining highways, bridges and tunnels.
. . .
Food Expect food shortages, supply chain disruptions and weather issues to drive food prices much higher in the months and years to come. There’s a reason that the government excludes food prices from the consumer price index (cpi) and it’s not because they’re going down. Higher fuel costs will also result in higher food prices, as modern farming techniques are energy intensive, not to mention that virtually all food produced must be shipped to market. Fertilizers and pesticides will go right up along with oil and natural gas prices.
REDSTATE: "Groups Warning of Imminent Global Supply Chain System Collapse"
Cargo ships anchored off California and New York, and in rail yards and on trucking routes, shipping consumer goods are incredibly backlogged due to a lack of manpower and pandemic restrictions to unload the goods. And now, there are warnings that the supply chain may be on the brink of collapse.
Shipping ports which normally only had one or two ships in dock waiting to be unloaded prior to the pandemic now have dozens lined up, waiting to be unloaded for up to four weeks, slowing the whole chain. In Los Angeles and Long Beach, as many as 73 vessels were waiting to be unloaded last month. The bottlenecks at the ports are also impacting railways and trucking. In Chicago — that has one of the largest rail yards — it was at one point backed up for 25 miles.
WALL STREET JOURNAL: "China’s Power Shortfalls Begin to Ripple Around the World"
The power crunch, on a scale unseen in more than a decade, highlights how some of Beijing’s changing policy priorities, including its effort to limit carbon emissions, can ripple through a global economy that has been reshaped by the pandemic.
"There’ll be a cascading effect," said Mike Beckham, Oklahoma-based co-founder and CEO of Simple Modern, which makes products such as insulated water bottles and backpacks. "As we started to comprehend the ramifications of what’s happening, we realized that this is potentially bigger than anything we’ve seen in our business careers."
Two weeks ago, one of Mr. Beckham’s main suppliers, based in Quzhou city in eastern China, was told by the local government that it could only operate four days a week, instead of the usual six. In addition, it must adhere to a power-usage cap, which cuts the capacity of the factory by about one-third as a result.
Mr. Beckham anticipates U.S. retail prices for many products could increase by as much as 15% next spring, as appetite from retailers stays strong.
. . .
Steve Cooke … said he relies on suppliers who source 80% of their products from China.
Already this year, rising freight costs and supply-chain bottlenecks have pushed up his costs and lengthened delivery times for his customers. He said he expects those pressures to intensify as the power crunch squeezes production.
"We rely so much on China, it’s incredible," Mr. Cooke said.
CNN: "The workers who keep global supply chains moving are warning of a ‘system collapse’ "
Seafarers, truck drivers and airline workers have endured quarantines, travel restrictions and complex Covid-19 vaccination and testing requirements to keep stretched supply chains moving during the pandemic.
But many are now reaching their breaking point, posing yet another threat to the badly tangled network of ports, container vessels and trucking companies that moves goods around the world.
YAHOO! FINANCE: "China Orders Top Energy Firms to Secure Supplies at All Costs"
China’s central government officials ordered the country’s top state-owned energy companies — from coal to electricity and oil — to secure supplies for this winter at all costs … A severe energy crisis has gripped the country, and several regions have had to curtail power to the industrial sector, while some residential areas have even faced sudden blackouts. China’s power crunch is unleashing turmoil in the global commodities markets, fueling rallies in everything from fertilizer to silicon.
. . .
Volatility in the energy markets is poised to intensify on the order from the central government, said Bjarne Schieldrop, chief commodities analyst at SEB.
China’s statement “to me implies that we are in no way on a verge of a cool-off. Rather it looks like it is going get even more crazy,” he said. “They will bid whatever it takes to win a bidding war for a cargo of coal” or liquefied natural gas.
GCAPTAIN: "Port Operator DP World Sees Lasting Supply Chain Disruptions: ‘Maybe in 2023’ "
Dubai’s DP World, one of the biggest global port operators, expects supply chain bottlenecks that have rattled global trade flows to continue at least for another two years … Global supply chains are struggling to keep pace with demand and overcome labor disruptions caused by Covid outbreaks. The world’s largest shipping line, A.P. Moller-Maersk, has also warned bottlenecks may last longer than expected.
CHARLES HUGH SMITH: "The U.S. Economy In a Nutshell: When Critical Parts Are On "Indefinite Back Order," the Machine Grinds to a Halt"
If the part that blew out is 0.1% of the entire machine, and the other 99.9% still works perfectly, the entire machine is still dead in the water without that critical component. That is a pretty good definition of systemic vulnerability and fragility, a fragility that becomes much, much worse if there are two or three components which are on indefinite back order.
This is the problem with shipping much of your supply chain overseas: you create extreme systemic vulnerability and fragility even as you rake in big profits from reducing costs.
. . .
The Federal Reserve can print trillions of dollars and the federal government can borrow and blow trillions of dollars, but neither can print or borrow supply chains, scarce skills, institutional depth or competence.
And, to sum up the effect on the "man (or woman) in the street", Gun Free Zone notes:
The family went grocery shopping on Saturday.
Food was abundant, albeit more expensive than in the past, it was the other consumables that we had a hard time finding. Things like shampoo, body wash, mouth wash, cleaning supplies, foot spray, OTC drugs, were low, especially the store brand generics.
Today I went to Walmart at lunch and it took was low on a lot of non-food supplies.
Some specialty food items like Gatorade/sports drinks have been low or empty for weeks.
I haven’t seen store shelves this picked clean since the early lockdown days of COVID over a year ago.
. . .
Manufacturing, transportation, and distribution should be back into near-full swing. The economy should be recovering fast.
Instead, it looks like we’ve rolled the clock back 18 months and we’re about to get ****ed.
I think the bottom is about to out of the market and it’s going to be a disaster.
I wrote recently about steps I was taking to protect my family from the supply chain snarl-up. I can only recommend most strongly that you check your own supplies, make a list of things you need to get through at least the next two to three months, and stock up on them right now, while they’re still to be found. You may find some are already unavailable; if so, look for substitutes, and don’t quibble about getting exactly the brand or variety you wanted.
Right now, we’re bracing for impact. I don’t believe we’re going to make it to Christmas without things getting much, much worse.
Peter
Bayou Renaissance Man
Here Are All The Headlines The Babylon Bee Would Have Written If We Were Around In Bible Times
https://media.babylonbee.com/articles/article-9624-1.jpg
Here Are All The Headlines The Babylon Bee Would Have Written If We Were Around In Bible Times
Brought to you by:
Sadly, The Babylon Bee has only been around for five years, which is 5,995 fewer years than the Earth has been around. Had we existed during Bible times, we definitely would have had some hilarious, scathing headlines to cover all the events that happened in ancient Israel and beyond.
But we wanted to bless you. We went back through the Bible archives and came up with our best headlines for what happened in the Bible. Here they are:
OLD TESTAMENT
Closed-Minded God Only Creates Two Genders
Crazy Young-Earth Creationist Adam Claims Earth Is Only 7 Days Old
Bigot Noah Only Allows Two Genders of Each Animal on Ark
Work On Tower Of Babel Near Completion, Grbizt Mcbkd Flimadpt Dipbdeth Swn
Friends Concerned for Job After Finding Him Sitting In A Cave Listening To Daniel Powter’s ‘Bad Day’ On Repeat
LGBTQ Community Beat: Things Heating Up In Sodom And Gomorrah
New Reality Show Follows Wild Misadventures Of Jacob, 2 Wives, And 13 Boys
Joseph Canceled For Wearing LGBTQ Coat Despite Being A Cishet Male
Angel Of Death Says Blood On Doorpost Booster May Be Necessary
Pharaoh Starting To Get Weird Feeling He Should Let Israelites go
Moses Arrested As He Did Not Have A Permit For Parting Of Red Sea
Moses Accidentally Drops Tablet Containing 11th Commandment Saying ‘Thou Shalt Not Start A Social Media Company’
God Says We Can’t Go Out For Manna Because We Have Manna At Home
Manna Renamed To More Inclusive ‘Theyna’
Israelites Spend 40 Years Wandering In Desert After Moses Forgets To Update Apple Maps
Jericho Wall Collapse Blamed On Failure To Pass Infrastructure Bill
Goliath Identifies As Female To Compete In Women’s MMA
Results Of David And Goliath Bout Bankrupts Numerous Bookies
God Confirmed Libertarian After Warning Israel Against Having A King
Saul Throws Spear At David ‘Cause He Keeps Playing ‘Moves Like Jagger’
‘Real Housewives Of Solomon’s Harem’ Reality Show Announced
Breaking: King Solomon Diagnosed With Syphilis
Jonah Telling Crazy Stories Again
Israel Totally Going To Be Obedient And Follow God This T–Update: Never Mind They Blew It
Sources Confirm Ba’al Was Indeed On The Crapper While His Prophets Were Getting Owned
Bible Scholars Reveal: Lions Lost Appetite After Hearing Daniel’s Anti-Vax Conspiracy Rant
NEW TESTAMENT
Choir Of Heavenly Hosts Cited For Violating Bethlehem’s 8pm Noise Ordinance
King Herod Calls For Destroying Any Clumps Of Cells Less Than Two Years Old
Pharisee Wears Phylactery So Large He Can’t Lift His Head
Zacchaeus Sues Jesus For Not Following ADA Guidelines At Event
Pharisees Condemn Jesus’s Miraculous Healings As Unapproved Treatment For Leprosy
Jesus Totally Owns Pharisees By Turning Their Tears Into Wine
Jesus Heals Your Mom Of Obesity
CNN Reports Jesus Only Able To Walk On Water Because Of Climate Change
Jesus Hatefully Slut-Shames Woman At Well
Pontius Pilate Diagnosed With Germaphobia For Frequent Hand-Washing
Jesus Uncancels The Whole World
Local Stoner Named Saul Becomes Apostle
Apostle John Praised For Isolating, Social Distancing On Island Of Patmos
NOT SATIRE: Trust in media is at an all-time low (shocking… we know) but let’s keep “walking around completely uninformed” as a backup plan.
The Pour Over provides concise, politically neutral, and entertaining summaries of the world’s biggest news paired with reminders to stay focused on eternity, and delivers it straight to your inbox. The Pour Over is 100% free for Bee readers.
Supplement your satire… try The Pour Over today!
(100% free. Unsubscribe anytime.)
The Babylon Bee
Larger Laravel Projects: 12 Things to Take Care Of
https://laraveldaily.com/wp-content/uploads/2021/09/Larger-Laravel-Projects.png
Probably the most difficult step in the dev career is to jump from simple CRUD-like projects in the early years into some senior-level stuff with bigger architecture and a higher level of responsibility for the code quality. So, in this article, I tried to list the questions (and some answers) to think about, when working with large(r) Laravel projects.
This article will be full of external links to my own content and community resources, so feel free to check them out.
Disclaimer: What is a LARGE project?
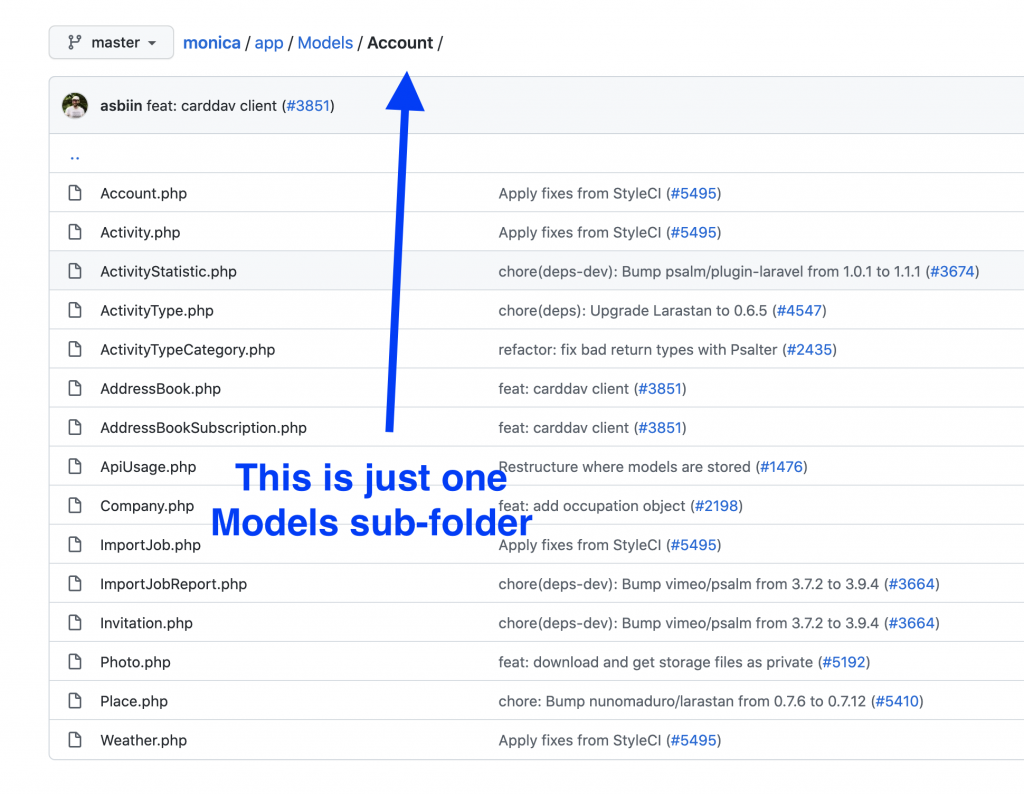
First, I want to explain what I mean by “large”. Some people measure that in the number of database records, like million rows in users table is large. Yes, but it’s a large database, not the Laravel project itself.
What I mean by a larger project is mostly the number of entities to manage. In simple terms, how many Eloquent Models your project has. If you have many models, it usually means complexity. With that, as secondary measurement numbers, you may count the number of routes or public Controller methods.
Example from an open-source Monica CRM project that has 300+ lines of code in routes/web.php file:
With the scope of work this big, there are usually multiple developers working on the project, which brings the complexity to manage the codebase.
Also, a third non-tech feature of a large project is the price of the error. I would like to emphasize those projects where your inefficient or broken code may cause real money to be lost: like 30 minutes of downtime in an e-shop may lose $10,000 to the business easily. Or, some broken if-statement may lead real dozens of people to NOT place the orders.
So yes, I’ll be talking about those large projects below.
1. Automated Tests
In smaller projects, there’s usually a smaller budget and a stronger push to launch “something” quicker, so automated tests are often ignored as a “bonus feature”.
In larger projects, you just cannot physically manually test all the features before releasing them. You could test your own code, yes, but you have no idea how it may affect the old code written by others. Heck, you may even have no idea how that other code or modules work because you’re focused on your parts of the application.
So, how else would you ensure that the released code doesn’t cause bugs? Quite often a new code is just a refactoring of the old code, so if you change something in the project structure, how would you be able to test that nothing is broken? Don’t fall into the mindset I call “fingers-crossed driven development“.
Also, getting back to the definition of a larger project – remember, the price of the bug is high. So, literally, your broken code may cause financial loss to the business. If that argument still doesn’t convince you to cover the code with tests, probably nothing else will.
Yes, I know that typical argument that “we don’t have time to write tests“. I have a full video about it.
But this is where you need to find that time. It involves some communication: evaluate the deadlines thinking about the time to write tests, also talk to the managers about what would happen if you don’t write tests. They will then understand and allow that extra time. If they don’t, it means they don’t care about quality that much, so then maybe time to find another company?
Now, I’m not necessarily talking about a mythical “100% test coverage”. If you are really pressured on time, pick the functions to test that are crucial for your app to work. As Matt Stauffer famously said, “first, write tests for features, which, if they break, would cause you to lose your job“. So, anything related to payments, user access, stability of the core most used functionality.
2. Architecture and Project Structure
Ahh, yes, a million-dollar question: how to structure a Laravel project? I even published a 5-hour course on that topic, back in 2019, and I still feel I only scratched the surface there.
There are many different models or ideas that you may follow: divide the project into modules, use the DDD approach, pick some from the design patterns, or just follow SOLID principles. It is all a personal preference.
The thing is there’s no silver bullet and a one-size-fits-all approach. No one can claim that, for example, all bigger Laravel projects should follow DDD. Even SOLID principles sometimes are busted as not the best for some cases.
But the problem is clear: as your project structure grows, you need to change something, and re-structure the files/folders/classes into something more manageable. So what are the essential things you should do?
First, move things into sub-folders and namespace everything accordingly. Again, the example from the Monica CRM is pretty good.
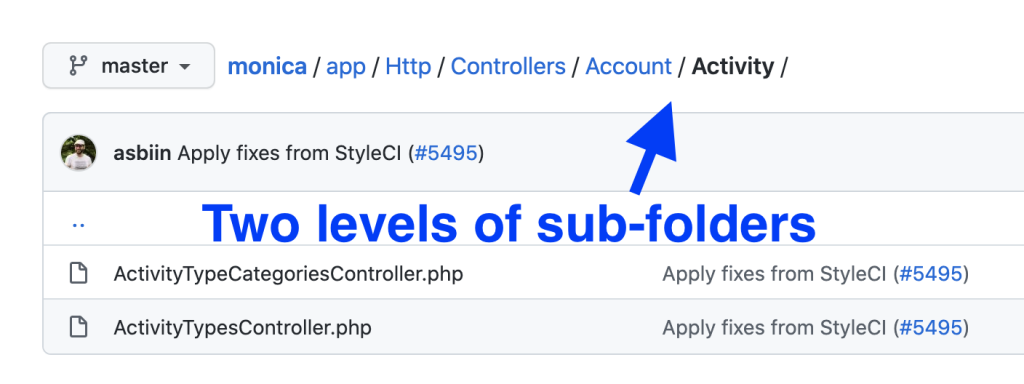
Then, make sure that your classes/methods are not too large. There’s no magic number to follow, but if you feel that you need to scroll up&down too often, or spend too much time figuring out what the class/method does, it’s time to refactor and move the parts of the code somewhere else. The most common example of this is too big Controller files.
These are just two pieces of advice, but just those two changes make your code massively more readable, maintainable, and even more testable.
And yes, sometimes it requires a big “risky” refactoring of classes, but hey, you probably have automated tests to check everything, right? Right?
3. “Fake Data” with Factories and Seeds
A topic related to the automated testing we’ve already talked about. If you want to stress-test your application features, you need a large amount of data. And factories+seeds are a perfect combination to achieve that pretty easily.
Just get into the habit of, when creating a new Eloquent model, create a factory and a seed immediately, from the very beginning. Then, whoever will use it in the future to generate some fake data, will thank you very much.
But it’s not only about testing. Also, think about the fresh installation of your application. Large successful projects tend to grow only larger, so you would definitely have to onboard new developers. How much would they struggle with the installation process and getting up to speed, if they don’t have any sample data to work with?
You will also probably need to install your application multiple times on various servers – local, staging, some Docker-based environments, etc. You can customize the seeds to run under the condition of whether it’s a production or local environment.
4. Database structure
Although I mentioned in the beginning that database size is not the definition of a large Laravel project, but database structure is a hugely important thing for long-term performance and maintainability.
Which relationships to use? In Laravel terms, should it be a HasOne? HasMany? BelongsToMany? Polymorphic?
Also, other questions. One larger table or several smaller ones? ENUM field or a relationship? UUID or ID column? Of course, each case is individual, and I have a full course on structuring databases, but here is my main short tip.
Try to ask your “future self” about what potential SQL queries will there be on these DB tables, and try to write those queries first.
In other words, think about the end goal, and reverse engineer the structure from that. It would help you to “feel” the correct structure.
If you have factories and seeds ready (notice the pattern of how the topics in this article help each other?), you would be able to easily simulate the future usage, maybe even measure A vs B options, and decide on which is the correct one. This moment is actually very important: changing the DB structure in the future, with a large amount of live data, is probably one of the most complex/expensive/risky changes to make. So you better make a good decision up front.
That said, you shouldn’t be afraid to refactor the database if there’s a real need for that. Move some data into a separate less-used table, change HasMany into Polymorphic, choose other column types, etc.
Just make sure you don’t lose any customer data.
5. External Packages and Laravel Upgrades
When you choose what Laravel/PHP packages to include in your composer.json, in the very beginning it’s pretty easy: just use the latest versions of everything, and make sure the package is useful.
But later, when the project is alive for a year or two, there’s a need to upgrade the versions. Not only Laravel itself but also the packages, too.
Luckily, Laravel switched to a yearly release schedule from 6-months (and later moved Laravel 9 release to be in sync with Symfony), so developers don’t have that headache every 6 months anymore.
Generally, the framework itself has a pretty stable core, and the upgrades to new versions are relatively easy, should take only a few hours. Also, a service called Laravel Shift is a huge helper for developers who want to save time on this.
But the problem arises from the packages you use.
Pretty typical scenario: you want to upgrade the project to a new Laravel version, but a few packages from your composer file haven’t released their new versions yet to support that Laravel upgrade. So, in my experience, project upgrades are happening at least a few months after the official Laravel release, when the package creators catch up.
And, there are worse scenarios: when the package creator doesn’t have time to release the upgrade (remember, most of them do it for free, in their spare time), or even abandon the package. What to do then?
First, of course, you can help the creator, and submit a Pull Request with the suggested upgrade (don’t forget to include automated tests). But even then, they need to review, test, and approve your PR, so I rarely see that happening in real life. The packages are either actively maintained, or close to abandoned status. So, the only reasonable solution then is to fork the package and use your own version in the future.
But, an even better decision, is to think deeper at the time of choosing what packages to use. Questions to ask are: “Do we REALLY need that package?” and “Does the package creator have a reputation of maintaining their packages?“
6. Performance of everything
If the project becomes successful, its database grows with more data, and the server needs to serve more users at a time. So then, the loading speed becomes an important factor.
Typically, in the Laravel community, we’re talking about performance optimization of Eloquent queries. Indeed, that’s the no.1 typical reason of performance issues.
But Eloquent and database are only one side of the story. There are other things you need to optimize for speed:
– Queue mechanism: your users should not be waiting for 5 minutes for the invoice email to arrive
– Loading front-end assets: you shouldn’t serve 1 MB of CSS/JS if you can minimize it
– Running automated tests suite: you can’t wait for an hour to deploy new changes
– Web-server and PHP configuration: users shouldn’t be “waiting in line” while other 10,000 users are browsing the website
– etc.
Of course, each of those topics is a separate world to dive deep in, but the first thing you should do is set up a measurement and reporting system, so you would be notified if there’s a slow query somewhere, a spike in visitors at some time or your server is near CPU limit.
7. Deployment Process and Downtime
In a typical smaller project, you can deploy new changes by just SSHing to the server and running a few git and artisan commands manually.
But if you have bigger traffic and a larger team, you need to take care of two things:
– Zero-downtime deployment: to avoid any angry visitors that would see the “deploying changes…” screen, and collisions for visitors pre-post deployment. There’s the official Envoyer project for this and a few alternatives.
– Automatic deployments: not everyone on your team has (or should have) SSH access to production servers, so deployment should be a button somewhere, or happen automatically, triggered by some git action
Also, remember automated tests? So yeah, you should automate their automation. Sounds meta, I know. What I mean is that tests should be automatically run before any deployment. Or, in fact, they should be run whenever new code is pushed to the staging/develop branch.
You can schedule to perform even more automated actions at that point. In general, automation of this build/deploy process is called Continuous Integration or Continuous Delivery (CI/CD). It reduces some stress when releasing new features.
Recently, the most popular tool to achieve that became Github Actions, here are a few resources about it:
– Build, Test, and Deploy Your Laravel Application With GitHub Actions
– How to create a CI/CD for a Laravel application using GitHub Actions
But it’s not only about setting up the software tools. The important thing is the human factor: every developer should know the deployment process and their responsibility in it. Everyone should know what branch to work on, how to commit code, and who/how closes the issues. Things like “don’t push directly to the master branch” or “don’t merge until the tests passed” should be followed on the subconscious level.
There are also social norms like “don’t deploy on Fridays”, but that is debatable, see the video below.
8. Hardware Infrastructure for Scaling
If your project reaches the stage of being very popular, it’s not enough to optimize the code performance. You need to scale it in terms of hardware, by putting up more server power as you need it, or even upsizing/downsizing based on some expected spikes in your visitor base, like in the case of Black Friday.
Also, it’s beneficial to have load balancing between multiple servers, it helps even in case one of the servers goes down, for whatever reason. You can use Laravel Forge for this, see the screenshot below.
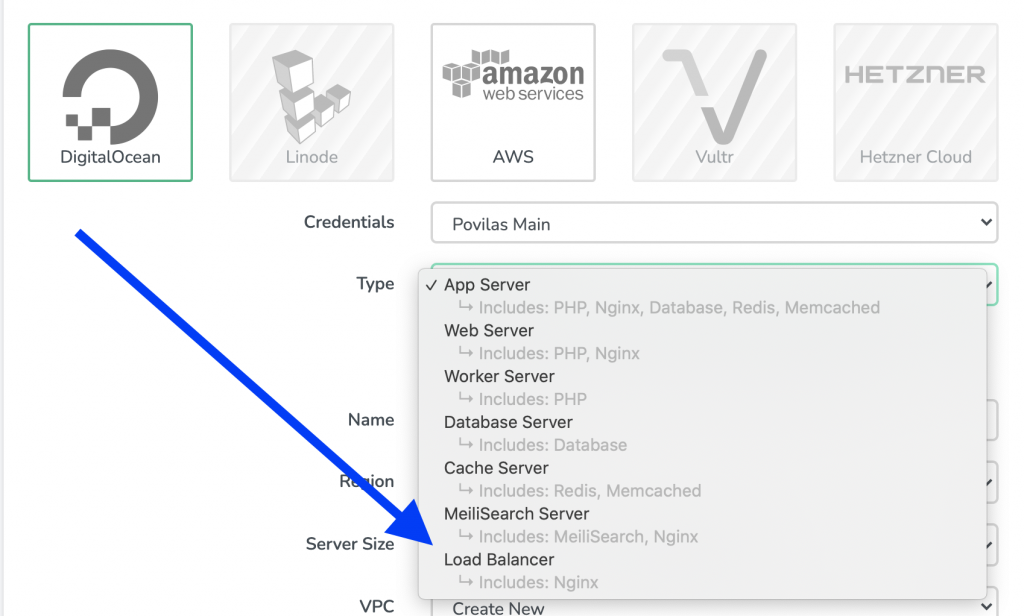
Also, don’t forget the scaling of external services. There are separate infrastructure hardware solutions to power your File Storage, Queues, Elasticsearch/Algolia, Socket real-time stuff, Databases, etc. It would be a huge article on each of those areas.
There are so many various tools out there that I can’t really recommend one, in particular, everything depends individually on your project needs, your budget, and your familiarity with a certain ecosystem.
The obvious server-power leader of the world is Amazon with their AWS Ecosystem, but often it’s pretty hard to understand its documentation, there are even explanation websites like AWS in Plain English.
Also, there’s a relatively new “player” in town, called serverless. It became a thing in the Laravel world with the release of Laravel Vapor – a serverless deployment platform for Laravel, powered by AWS.
Probably the best resource to get deeper into this whole scaling world is the course Scaling Laravel.
9. Backups and Recovery Strategy
Everyone probably knows that you need to perform regular backups of your database. And, on the surface, it’s pretty easy to do with a simple Spatie Laravel Backup package:
And, of course, you need to automate it, like “set it and forget it”. But, an important question is have you tried the recovery from that DB backup, at least once?
You need to actually test the scenario: what if your current DB server totally dies, or someone drops the whole production database, and all you have is that backup SQL. Try to actually run the import from it, and test if nothing breaks. If there’s a problem with a backup recovery, you better know it before the disaster happens.

Also, it gets more complicated when you have multiple Database servers, replication, and also you want to not slow down your server while the backup is in progress. So you may tweak the process or use some database backup tools directly, even outside the Laravel world.
10. Bug Monitoring Process
Of course, the larger the codebase, the bigger probability of bugs happening. Also, when there are dozens of features, developers can’t test them all themselves, and even automated tests don’t catch all the possible scenarios and cases. Bugs happen to real users of the system, in the wild.
Your goal as a team is to monitor them and be informed when they happen. There are various tools to help with that, I personally use Bugsnag, but there’s also Flare, Sentry, Rollbar – all of them perform pretty much the same thing: notify you about the bugs, with all possible information that helps to trace and fix that bug.
But again, it’s not only about setting up the tool, it’s about the human factor, as well. The team needs to know the process of who reacts to what bug and how exactly: which bugs are urgent, which ones can be postponed, or totally ignored.
Also, the question “Who’s on duty today” is pretty relevant: if the bug tracking software notifies about something, who needs to get that message and via which channel? In our team, we use Slack notifications, and then ideally the situation should be fixed by the developer responsible for that part of the application which is buggy. Of course, in reality, it doesn’t happen all the time, but at least the team needs to know the time-to-react goals.
There’s also another part of the team: non-tech people. Developers need to be in touch with customer support people, and with managers, informing them about the severity and the status of the situation, so the “front-facing” people would talk to the customers accordingly.
11. Security
This question is kinda obvious, so I won’t explain it in too much detail. In addition to generally avoid getting hacked, probably the most important thing is to secure the personal data of your users – both from other users in multi-tenant systems and from the outside world.
I recommend reading this article: How to Protect Your Laravel Web Application Against the OWASP Top 10 Security Risks
Also, I recommend trying to hack yourself. Yes, I’m not kidding – ask some trusted friend/company from the outside to break into your app and do some damage. Heck, even pay for that – there are companies specializing in this area. Of course, you could try to do it yourself, but, as the author of the code, you’re kinda biased, and you probably wouldn’t try something unusual as a typical hacker would.
Finally, I’d like to express my happiness about the fact that we don’t need to explain the need for an SSL certificate anymore: with browser warning changes, and with free tools like Let’s Encrypt, there’s no excuse to not have https:// in your website.
12. Docs for onboarding new devs
The final point in this big article is about people. If you work on the project not from its first day, remember the day when you were introduced to it. Do you remember the feeling of installing everything, reading the docs, playing around with testing data, trying to understand how things work?
Now, imagine the mind of a new developer doing that on the current project, which is not much more complex. So, you need to help those poor guys, as much as you can.
I would suggest to even become that “new developer” for a day. When was the last time you tried to install your application, from the ground up? On a new computer or re-installed OS, for example. So yeah, try that, you may get a few unpleasant “surprises” to fix.
Things like installation instructions in Readme (maybe even with Docker images), comments in the code, making the code “clickable” in the IDE, understandable messages in git commits – all of that should be taken care of. And, remember when we talked about factories and seeds? Yes, that applies here, massively.
By the way, there are tools to help you, like this Readme generator.
And it’s not only about totally new developers – the same may happen to any existing team member who needs to fix something in the module that they hadn’t seen before. Any help is appreciated.
Your Thoughts?
What do you think about these 12 questions? I tried to provide short comments and external links, but obviously, it’s just an overview. Would you add any more questions to this list? Or, maybe you have a particular question you want me to expand on, in future articles/videos? Shoot in the comments below.
Laravel News Links
Synchronize Tables on the Same Server with pt-table-sync
https://www.percona.com/blog/wp-content/uploads/2021/10/Synchronize-Tables-on-the-Same-MySQL-Server-300×157.png
 It is a common use case to synchronize data in two tables inside MySQL servers. This blog post describes one specific case: how to synchronize data between two different tables on the same MySQL server. This could be useful, for example, if you test DML query performance and do not want to affect production data. After few experiments, tables get out of sync and you may need to update the test one to continue working on improving your queries. There are other use cases when you may need to synchronize the content of the two different tables on the same server, and this blog will show you how to do it.
It is a common use case to synchronize data in two tables inside MySQL servers. This blog post describes one specific case: how to synchronize data between two different tables on the same MySQL server. This could be useful, for example, if you test DML query performance and do not want to affect production data. After few experiments, tables get out of sync and you may need to update the test one to continue working on improving your queries. There are other use cases when you may need to synchronize the content of the two different tables on the same server, and this blog will show you how to do it.
Table Content Synchronization
The industry-standard tool for table content synchronization – pt-table-sync – is designed to synchronize data between different MySQL servers and does not support bulk synchronization between two different databases on the same server yet. If you try it, you will receive an error message:
$ pt-table-sync D=db1 D=db2 --execute --no-check-slave You specified a database but not a table in D=db1. Are you trying to sync only tables in the 'db1' database? If so, use '--databases db1' instead.
However, it is possible to synchronize two individual tables on the same server by providing table names as DSN parameters:
$ pt-table-sync D=db1,t=foo D=db2,t=foo --execute --verbose # Syncing D=db2,t=foo # DELETE REPLACE INSERT UPDATE ALGORITHM START END EXIT DATABASE.TABLE # 0 0 5 0 GroupBy 03:24:26 03:24:26 2 db1.foo
You may even synchronize two tables in the same database:
$ pt-table-sync D=db2,t=foo D=db2,t=bar --execute --verbose # Syncing D=db2,t=bar # DELETE REPLACE INSERT UPDATE ALGORITHM START END EXIT DATABASE.TABLE # 0 0 5 0 GroupBy 03:25:34 03:25:34 2 db2.foo
We can use this feature to perform bulk synchronization.
First, we need to prepare a list of tables we want to synchronize:
$ mysql --skip-column-names -se "SHOW TABLES IN db2" > db1-db2.sync $ cat db1-db2.sync bar baz foo
Then we can invoke the tool as follows:
$ for i in `cat db1-db2.sync`; do pt-table-sync D=db1,t=$i D=db2,t=$i --execute --verbose; done # Syncing D=db2,t=bar # DELETE REPLACE INSERT UPDATE ALGORITHM START END EXIT DATABASE.TABLE # 0 0 0 0 GroupBy 03:31:52 03:31:52 0 db1.bar # Syncing D=db2,t=baz # DELETE REPLACE INSERT UPDATE ALGORITHM START END EXIT DATABASE.TABLE # 0 0 5 0 GroupBy 03:31:52 03:31:52 2 db1.baz # Syncing D=db2,t=foo # DELETE REPLACE INSERT UPDATE ALGORITHM START END EXIT DATABASE.TABLE # 0 0 0 0 GroupBy 03:31:52 03:31:52 0 db1.foo
If you have multiple database pairs to sync, you can agree on the file name and parse it before looping through table names. For example, if you use pattern
SOURCE_DATABASE-TARGET_DATABASE.sync
you can use the following loop:
$ for tbls in `ls *.sync`
> do dbs=`basename -s .sync $tbls`
> source=${dbs%-*}
> target=${dbs##*-}
> for i in `cat $tbls`
> do pt-table-sync D=$source,t=$i D=$target,t=$i --execute --verbose
> done
> done
# Syncing D=cookbook_copy,t=limbs
# DELETE REPLACE INSERT UPDATE ALGORITHM START END EXIT DATABASE.TABLE
# 0 0 4 0 GroupBy 04:07:07 04:07:07 2 cookbook.limbs
# Syncing D=cookbook_copy,t=limbs_myisam
# DELETE REPLACE INSERT UPDATE ALGORITHM START END EXIT DATABASE.TABLE
# 5 0 5 0 GroupBy 04:07:08 04:07:08 2 cookbook.limbs_myisam
# Syncing D=db2,t=bar
# DELETE REPLACE INSERT UPDATE ALGORITHM START END EXIT DATABASE.TABLE
# 0 0 5 0 GroupBy 04:07:08 04:07:08 2 db1.bar
# Syncing D=db2,t=baz
# DELETE REPLACE INSERT UPDATE ALGORITHM START END EXIT DATABASE.TABLE
# 5 0 5 0 GroupBy 04:07:08 04:07:08 2 db1.baz
# Syncing D=db2,t=foo
# DELETE REPLACE INSERT UPDATE ALGORITHM START END EXIT DATABASE.TABLE
# 5 0 0 0 GroupBy 04:07:08 04:07:08 2 db1.foo
Note that
pt-table-sync
synchronizes only tables that exist in both databases. It does not create tables that do not exist in the target database and does not remove those that do not exist in the source database. If your schema could be out of sync, you need to synchronize it first.
I used option
--verbose
in all my examples, so you can see what the tool is doing. If you omit this option the tool still is able to synchronize tables on the same server.
Complete the 2021 Percona Open Source Data Management Software Survey
Planet MySQL