https://opengraph.githubassets.com/10ff2c561ee9af0da28dbb031cb9b5ad5e961f52b7032cbb54b0d6e3c8ed6c9f/haruncpi/laravel-query-log
Laravel News Links
Just another WordPress site
https://opengraph.githubassets.com/10ff2c561ee9af0da28dbb031cb9b5ad5e961f52b7032cbb54b0d6e3c8ed6c9f/haruncpi/laravel-query-log
Laravel News Links
https://s0.wp.com/i/blank.jpg
Laravel Notifications are an awesome tool that provides built-in support for sending notifications, in dozens of different channels, like Slack, Telegram, SMS, etc.
In this tutorial, we will see how we can customise Laravel Notifications core to accommodate a multi-tenant setup in a single database.
Note: This tutorial is using Laravel 9.x but should be working for older Laravel versions as well.
The first thing we need to do is publish the default notifications table using
php artisan notifications:tableYou should now have a new migration file under database/migrations which should look like this
<?php
use Illuminate\Database\Migrations\Migration;
use Illuminate\Database\Schema\Blueprint;
use Illuminate\Support\Facades\Schema;
return new class extends Migration {
public function up()
{
Schema::create('notifications', function (Blueprint $table) {
$table->uuid('id')->primary();
$table->string('type');
$table->morphs('notifiable');
$table->text('data');
$table->timestamp('read_at')->nullable();
$table->timestamps();
});
}
};Ideally, we would like to have a foreign key to the tenant model.
Schema::create('notifications', function (Blueprint $table) {
$table->uuid('id')->primary();
$table->string('type');
$table->morphs('notifiable');
$table->text('data');
$table->timestamp('read_at')->nullable();
$table->timestamps();
$table->foreignId('tenant_id')->constrained(); // <- Add this
});If tenants are supposed to be receiving notifications you might want to make the tenant_id column nullable.
The next step would be to find a way to fill in that column whenever a notification is being stored in the database. For that, we need to extend the default DatabaseChannel class and replace our version in the Laravel Container.
What we need is a new class called DatabaseChannel which extends Illuminate\Notifications\Channels\DatabaseChannel.
<?php
namespace App\Notifications\Channels;
use Illuminate\Notifications\Notification;
class DatabaseChannel extends \Illuminate\Notifications\Channels\DatabaseChannel
{
public function buildPayload($notifiable, Notification $notification)
{
return [
'id' => $notification->id,
'type' => get_class($notification),
'data' => $this->getData($notifiable, $notification),
'read_at' => null,
'tenant_id' => $notification->tenant_id,
];
}
}
Now, whenever we create a new notification we need to inject the tenant_id property so that we can insert it into the database.
<?php
namespace App\Notifications;
use Illuminate\Notifications\Notification;
class BaseNotification extends Notification
{
public $tenant_id;
public function __construct($tenant_id)
{
$this->tenant_id = $tenant_id;
}
public function via()
{
return ['database'];
}
public function toDatabase($notifiable)
{
return [
// your payload
];
}
}Finally, we need to switch Laravel’s implementation of the DatabaseChannel with ours. To do that we just need to set this up inside the boot method of the AppServiceProvider.
<?php
namespace App\Providers;
use App\Notifications\Channels\DatabaseChannel;
use \Illuminate\Notifications\Channels\DatabaseChannel as BaseDatabaseChannel;
class AppServiceProvider extends ServiceProvider
{
public function boot()
{
$this->app->instance(BaseDatabaseChannel::class, new DatabaseChannel());
}
}
And that’s it!
You now have multi-tenant notifications set up in your Laravel project!
Laravel News Links
The Wyoming Senate has voted 16 to 14 to eliminate the U. of Wyoming Gender Studies program. (Bill below). This will not only eliminate not only the gender studies department, but also courses and non-academic programs related to gender.
Please re-tweet to amplify and stop this pic.twitter.com/5AJVxG4gZD
— Kate Hartmann (@kateahart) February 28, 2022
Every Red state needs to do this.
Systematically go through and weed out every department and degree program that is just accredited Leftist indoctrination.
Fire the professors.
Spend the money on vocational education.
Gun Free Zone
https://blogger.googleusercontent.com/img/a/AVvXsEgnnDS-XiJwHSmquVOhmNPxIjeBCNTEWyMYuWsOzgdsZDbBEh2EM3rqkddbXqQvbC_OkNY0xf6kwcYignJZhaQhy2xHyBu-SoEIGlXApGkVa-rjE2EO3Sl5DRrUmOETMCgjfcQul6jskUYyfw0l8tnxGce7DLrkqeHNSb81JOTsoJj8hxU05yKGAhVX=w325-h400
Gathered from around the Internet over the past week. There are fewer than usual, thanks to a three-day road trip to attend the wedding of a friend, during which time I had limited Internet access. Click any image for a larger view.




















More next week.
Peter
Bayou Renaissance Man
https://www.percona.com/blog/wp-content/uploads/2022/02/MySQL-Restore-Backup-Comparison.png
 A little bit ago, I released a blog post comparing the backup performance of different MySQL tools such as mysqldump, the MySQL Shell feature called Instance Dump, mysqlpump, mydumper, and Percona XtraBackup. You can find the first analysis here:
A little bit ago, I released a blog post comparing the backup performance of different MySQL tools such as mysqldump, the MySQL Shell feature called Instance Dump, mysqlpump, mydumper, and Percona XtraBackup. You can find the first analysis here:
However, we know the backups are just the first part of the story. What about the restore time? And which tool performs better for the complete operation (backup+restore)?
Let’s see the results and the conclusion in the following sections.
I ran the benchmark on an m5dn.8xlarge instance, with 128GB RAM, 32 vCPU, and two io1 disks of 600GB (one for backup and the other one for MySQL data) with 5000 provisioned IOPS. The MySQL version was 8.0.26 and configured with 89Gb of the buffer pool, 20Gb of redo log, and a sample database of 96 GB (more details below).
When we sum the backup time and the restore time, we can observe the results in the chart below:

And if we analyze the chart without mysqldump to have a better idea of how the other tools performed:

The backup size created by each tool:

Note that the backup size of XtraBackup (without compression) is the size of the datadir without the binary logs. Next, we can see the backup time:

And the restore time:

When we sum backup and restore times, we observe that the fastest tool is Percona XtraBackup. The main point of XtraBackup is not even the speed but its capacity to perform PITR backups. Also, the tool supports compression and encryption.
We can also observe that mydumper/myloader and MySQL Shell utilities produce good results in both phases. The difference from Xtrabackup is that both tools perform logical backups, which means that these tools connect to MySQL and extract the data to dump files. Because they have to extract data from MySQL, these tools are more sensitive for the MySQL configuration and backup/restore parametrization. For example, MyDumper/MyLoader has some extra options that can improve the backup and restore performance, such as --rows, --chunk-filesize, and --innodb-optimize-keys.
Note that XtraBackup, MyDumper, and mysqldump support stream restore, reducing overall timing to perform the backup and restore operation.
The tool that has the most inconsistent behavior is mysqlpump where the tool can make speedy backups, but the restore performance is terrible since it is single-threaded the same way as mysqldump.
Based on the tests, we can observe that compression, TLS, socket, or TCP/IP do not significantly impact the time needed to perform the whole operation. Because there is no significant impact, tools that can perform compression and use TLS like MySQL Shell, mydumper/myloader, and XtraBackup have a good advantage since their backups are safer and use less disk space (less disk space = fewer costs). The trade-off between the features of these tools and the time spent to backup and restore the database is something that all DBAs should evaluate.
And to answer some questions/comments about this topic:
The difference you see between MySQL Shell and mydumper can be explained by the use of SSL in one and clear transfer in the other. Encryption has a cost, unfortunately.
A: Indeed, SSL has a cost. However, when we put the security benefits of the SSL and consider the whole process, it is a small cost (in the same way as compression).
Does XtraBackup support ZSTD?
A: At this moment, no. However, there is a feature request for this (you can follow the JIRA ticket to receive updates about it):
https://jira.percona.com/browse/PXB-2669
Is there any difference substituting mysqldump | gzip with a different compression tool?
A: The difference is neglectable piping with gzip or sending the uncompressed dump to the disk. The mysqldump tool is the most inefficient option due to its single-thread nature, severely impacting performance. Because of its single-thread nature, the tool cannot extract maximum performance from hardware resources (in particular I/O).
How is the performance impact on MySQL when running the backups?
A: Unfortunately, I did not measure this. Based on my experience, there is a dedicated replica server for backup most of the time. If the MySQL community is interested in this test, I can write another post about this (leave in the comments your opinion).
It is possible to squeeze more juice from MySQL in the restore phase. We can take some actions like disabling the binary log and making asynchronous writes. You can check the advice (pros and cons) in these two blog posts:
https://www.percona.com/blog/2020/05/14/tuning-mysql-innodb-flushing-for-a-write-intensive-workload/
https://www.percona.com/blog/2014/05/23/improve-innodb-performance-write-bound-loads/
To conclude, this blog post is intended to give an overall idea of how these tools perform. I tried to stick with the default options of each tool (except the number of threads) to keep the test as fair as possible. Also, time is not the only thing that companies consider to adopt a backup method (security, encryption, and data protection are very important). In my daily tasks, I use mydumper/myloader and XtraBackup because I’m more familiar with the commands, and I have used them for a long time. However, I would advise keeping an eye on the MySQL Shell utilities since it is becoming a fascinating tool to perform many tasks (backup and restore have excellent results).
These are the specs of the benchmark:
Finally, you can reach us through the social networks, our forum, or access our material using the links presented below:
Percona Database Performance Blog
https://laravelnews.imgix.net/images/Laravel-cover-image—2-01-1646017014.png?ixlib=php-3.3.1
Scout APM is a Laravel application performance monitoring tool that ties performance anomalies directly to endpoints, saving developers hours of time spent on troubleshooting and debugging.
Scout recently expanded its service offerings to include microservices and managed service monitoring for PHP applications, giving you more cohesive and actionable observability metrics. Learn more about how to monitor a laravel application with Scout APM by reading below.
To get started monitoring your Laravel applications you will first of all need a Scout account. If you don’t have one already, you can sign up for a free 14-day free trial (no credit card required) here.
The next thing to do is to add the low-overhead monitoring agent to your project’s dependencies, this can be done with a single command in your shell:
1composer require scoutapp/scout-apm-laravel
This command will install two packages: scout-apm-laravel and scout-apm-php.
The next thing to do is to define some configurations settings to link the agent to your account. To do that, open up your project’s .env file in your favourite text editor and add the following three lines to the end of the file:
1SCOUT_MONITOR=true
2SCOUT_KEY=”enter your Agent Key here”
3SCOUT_NAME=”enter the name of you application here”
You can find your account’s Agent Key on the settings page of Scout.
And that’s it! Deploy, and after approximately 5 minutes, your data will start to appear in Scout. For more information about Heroku installs or to troubleshoot installation problems, either take a look at the documentation or shoot an email to support@scoutapm.com and we’ll be happy to help.
So you’ve created a Scout account, hooked up the monitoring agent, but where do you start with diagnosing your application’s performance issues? Let’s take a look at the main features of Scout which can help you to understand your performance issues quickly.
The first page that you are presented with when you log into Scout is the overview page (shown below) which gives you a clear, clutter-free, snapshot of the health and performance of your application in one quick glance.

The chart is highly configurable, allowing you to change the time period and toggle which metrics you want to see. It also features a neat drag-and-drop tool (shown below) that allows you to draw a box around areas you wish you explore in more detail. A pop-up window will dynamically load as you draw these boxes, showing all the endpoints that were accessed during this time period. This can be particularly useful when you see a performance spike on the chart and you want to see what caused it.

A great place to start if you are trying out Scout for the first time are the insights tabs. Here we have a set of algorithms which analyze your project to identify potential n+1 queries and slow queries. These offer you the “low-hanging fruit” of performance fixes that can often instantly improve your application’s performance.

Scout primarily provides application performance metrics at two levels. First of all, from the perspective of an Endpoint. For example, on average, how long does this endpoint take to access and what is the breakdown of where time was spent?
If you take a look at the screenshot below, you can clearly see that on the 3 occasions that this ForgetPasswordController endpoint was accessed 78% of the 2,371ms mean request time was spent in the controller layer indicating that would be the first place to investigate if we wanted to try to improve this sluggish endpoint.

The second perspective that Scout primarily presents metrics from is at the Trace level. For example, during this particular web request that somebody made, how long did it take to complete, and which levels of the request consumed the most time etc. Looking at the trace of the update action of the UserController below, we can see that in this case 98% of time was spent in the SQL layer, and most of this time was spent in those 2 calls to the query on the top line. If we click that SQL button we can see a backtrace and see if we can perhaps improve the query.

These pages are where you will spend most of your time in Scout, and they give you the sort of visibility that is essential when trying to understand your performance issues. You can reach Endpoint and Trace pages either by coming directly from the main overview page and insights tabs, or by clicking on the Web Endpoints link at the top of the page (shown below).

Now that we’ve covered the basics of Scout and shown you the main areas of the system that you would typically use day in, day out, let’s now switch our attention to some of the more advanced features which put Scout ahead of the crowd in the APM space.
Whether you are using Sentry, Honeybadger, Bugsnag, or Rollbar for your error monitoring, then we have you covered! Scout integrates seamlessly with these popular services, allowing you to have all your monitoring in one place, on the main overview page.

The setup process is similar regardless of which of these services you use, and all it involves is adding the API token on the settings screen of Scout.
Why does this performance issue only happen at 2:00AM on Tuesday night from a Brazlian IP address? These kinds of difficult (but common) performance issues can be tackled with one of the most powerful features of Scout: the trace explorer being used in conjunction with user defined custom context.
Used defined custom context allows you to tell us what you need to see. And it is well worth investing the relatively small amount of time it will take you to set up to be granted monitoring superpowers! By default the only context fields you will see are URI and Hostname, as you can see below, but these can be customized to anything that you want.

The trace explorer’s multi-filter charts (shown above) allow you to examine endpoints that match criteria that you have defined, and then you can see all the traces that match these filters in the Transaction Traces part of the screen. For example, perhaps you want to see the web requests of a certain user, or of all users on a certain plan size, or from a certain part of the world. These sorts of operations are easy to do in the trace explorer with custom context, and they help you to get to the bottom of those hard-to-diagnose, time-consuming performance issues.
Did this performance issue that you are seeing suddenly start happening after the last deploy? What is the user experience like during the time that you deploy? These are the types of questions that can be answered with our deploy tracking feature, which will place a rocket symbol on the main overview chart to indicate when a deployment occurred.

Deploy tracking also allows you to see details such as how many commits were involved in the deploy and which branch the commits came from. We can glean all this information when you add the SHA or your deployment to the SCOUT_REVISON_SHA environmental variable.
Like all good monitoring solutions, Scout provides you with a sophisticated alerting system which can be configured to send certain people alerts when endpoint response times or memory usage metrics go over a certain threshold. These alerts will appear as warning symbols on the main overview chart, and notifications will be sent out.

By default, the alerting system will send notifications to users in notification groups via email, but it can also be configured to work with third party services such as Slack, VictorOps, PagerDuty etc. with our webhook feature.
Are you using libraries outside of Laravel that we don’t currently instrument? If so, then first of all let our support team know and we’ll try and get support added for you. And in the meantime you can add some custom instrumentation yourself, it’s really easy to get started, and it will ensure that you have full visibility of your whole application.
As you can see Scout APM brings a very mature APM monitoring solution to the PHP and Laravel communities. Our clutter-free UI and deep instrumentation help you get right to the heart of your performance issues quickly, whilst remaining affordable due to our flexible transaction-based pricing structure.
Laravel News
https://gunfreezone.net/wp-content/uploads/2022/02/Screenshot_20220219-104756_Chrome.jpg


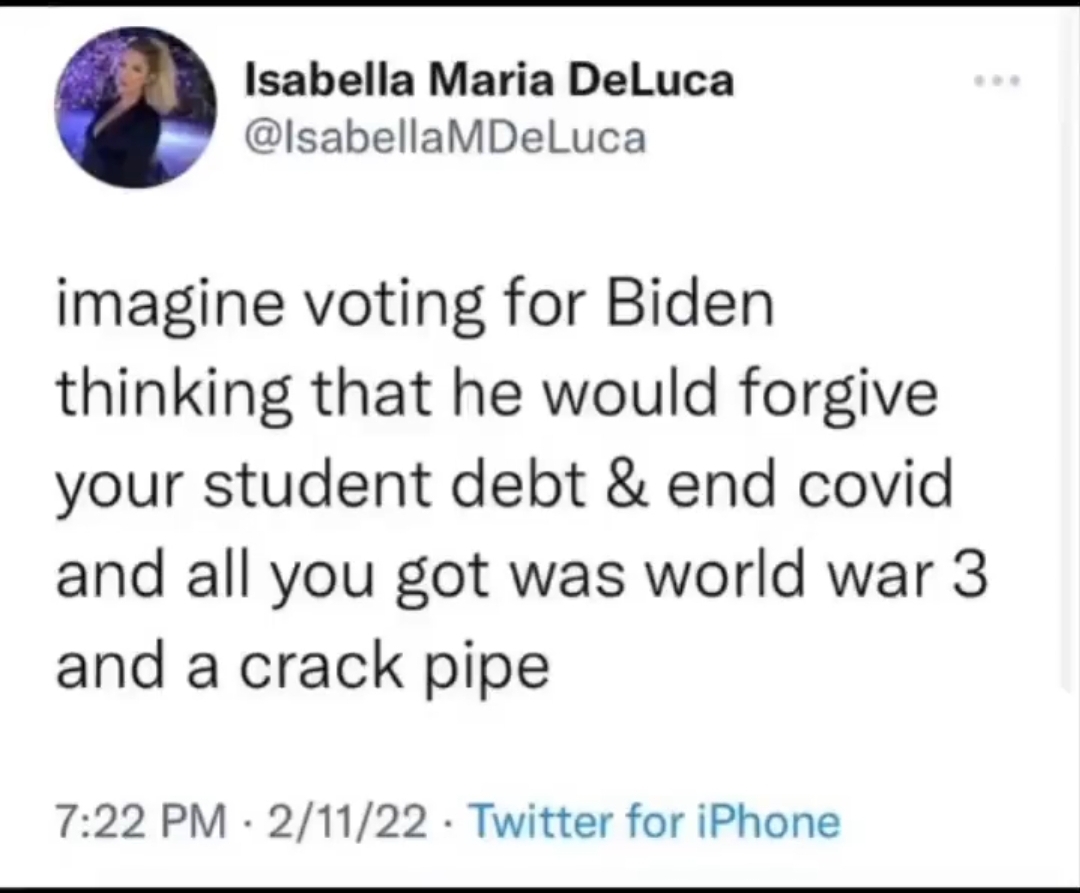





Gun Free Zone
https://gunfreezone.net/wp-content/uploads/2022/02/you-are-our-russians-2.jpg


Gun Free Zone
https://www.percona.com/blog/wp-content/uploads/2022/02/MySQL-Restore-Backup-Comparison.png
A little bit ago, I released a blog post comparing the backup performance of different MySQL tools such as mysqldump, the MySQL Shell feature called Instance Dump, mysqlpump, mydumper, and Percona XtraBackup. You can find the first analysis here:
However, we know the backups are just the first part of the story. What about the restore time? And which tool performs better for the complete operation (backup+restore)?
Let’s see the results and the conclusion in the following sections.
I ran the benchmark on an m5dn.8xlarge instance, with 128GB RAM, 32 vCPU, and two io1 disks of 600GB (one for backup and the other one for MySQL data) with 5000 provisioned IOPS. The MySQL version was 8.0.26 and configured with 89Gb of the buffer pool, 20Gb of redo log, and a sample database of 96 GB (more details below).
When we sum the backup time and the restore time, we can observe the results in the chart below:
And if we analyze the chart without mysqldump to have a better idea of how the other tools performed:
The backup size created by each tool:
Note that the backup size of XtraBackup (without compression) is the size of the datadir without the binary logs. Next, we can see the backup time:
And the restore time:
When we sum backup and restore times, we observe that the fastest tool is Percona XtraBackup. The main point of XtraBackup is not even the speed but its capacity to perform PITR backups. Also, the tool supports compression and encryption.
We can also observe that mydumper/myloader and MySQL Shell utilities produce good results in both phases. The difference from Xtrabackup is that both tools perform logical backups, which means that these tools connect to MySQL and extract the data to dump files. Because they have to extract data from MySQL, these tools are more sensitive for the MySQL configuration and backup/restore parametrization. For example, MyDumper/MyLoader has some extra options that can improve the backup and restore performance, such as --rows, --chunk-filesize, and --innodb-optimize-keys.
Note that XtraBackup, MyDumper, and mysqldump support stream restore, reducing overall timing to perform the backup and restore operation.
The tool that has the most inconsistent behavior is mysqlpump where the tool can make speedy backups, but the restore performance is terrible since it is single-threaded the same way as mysqldump.
Based on the tests, we can observe that compression, TLS, socket, or TCP/IP do not significantly impact the time needed to perform the whole operation. Because there is no significant impact, tools that can perform compression and use TLS like MySQL Shell, mydumper/myloader, and XtraBackup have a good advantage since their backups are safer and use less disk space (less disk space = fewer costs). The trade-off between the features of these tools and the time spent to backup and restore the database is something that all DBAs should evaluate.
And to answer some questions/comments about this topic:
The difference you see between MySQL Shell and mydumper can be explained by the use of SSL in one and clear transfer in the other. Encryption has a cost, unfortunately.
A: Indeed, SSL has a cost. However, when we put the security benefits of the SSL and consider the whole process, it is a small cost (in the same way as compression).
Does XtraBackup support ZSTD?
A: At this moment, no. However, there is a feature request for this (you can follow the JIRA ticket to receive updates about it):
https://jira.percona.com/browse/PXB-2669
Is there any difference substituting mysqldump | gzip with a different compression tool?
A: The difference is neglectable piping with gzip or sending the uncompressed dump to the disk. The mysqldump tool is the most inefficient option due to its single-thread nature, severely impacting performance. Because of its single-thread nature, the tool cannot extract maximum performance from hardware resources (in particular I/O).
How is the performance impact on MySQL when running the backups?
A: Unfortunately, I did not measure this. Based on my experience, there is a dedicated replica server for backup most of the time. If the MySQL community is interested in this test, I can write another post about this (leave in the comments your opinion).
It is possible to squeeze more juice from MySQL in the restore phase. We can take some actions like disabling the binary log and making asynchronous writes. You can check the advice (pros and cons) in these two blog posts:
https://www.percona.com/blog/2020/05/14/tuning-mysql-innodb-flushing-for-a-write-intensive-workload/
https://www.percona.com/blog/2014/05/23/improve-innodb-performance-write-bound-loads/
To conclude, this blog post is intended to give an overall idea of how these tools perform. I tried to stick with the default options of each tool (except the number of threads) to keep the test as fair as possible. Also, time is not the only thing that companies consider to adopt a backup method (security, encryption, and data protection are very important). In my daily tasks, I use mydumper/myloader and XtraBackup because I’m more familiar with the commands, and I have used them for a long time. However, I would advise keeping an eye on the MySQL Shell utilities since it is becoming a fascinating tool to perform many tasks (backup and restore have excellent results).
These are the specs of the benchmark:
Finally, you can reach us through the social networks, our forum, or access our material using the links presented below:
Planet MySQL
A question from the audience about caching the paginated data, I’m sharing my opinion in this video. What would you add?Laravel News Links