Disclaimer: This article is long. I recommend you to code along as we progress. If you are not in front of a development computer, bookmark this URL and come back later.
Is this tutorial for you?
☑️ If you know PHP and wish to start using Laravel, this is for you.
☑️ If you know any PHP framework and wish to try Laravel, this is for you.
🙅 If you already know Laravel (well), this tutorial may not help that much.
Why this tutorial?
The official Laravel documentation is one of the best technical documentation. But, it is not designed to get beginners started with the framework step-by-step. It doesn’t follow the natural way of learning a new thing.
In this tutorial, we will first discuss what needs to be done next, and then see what Laravel offers to achieve that. In some cases, we’ll discuss why something exists.
Important to note that for getting to the depth of a topic/feature, the Laravel documentation is the only resource you’ll need.
Assumptions
- You know about Object-oriented programming (OOP)
- You have an idea about the Model-View-Controller pattern (MVC)
- You are okay with me not offering a designed demo project with this tutorial.
What is the goal?
We’ll start from scratch and code a simple Laravel web app together to learn the building blocks of Laravel and boost your confidence.
As you may have read:
The only way to learn a new programming language is by writing programs in it.
— Dennis Ritchie (creator of the C programming language)
Same way, you will learn a new framework by doing a small test project today.
Keep in mind that we do not plan to use all the features of Laravel in a single project. We will cover all the important features though.
On your mark, Get set, Go!
You should be ready to get in the active mode from this point onwards. No more passive reading. I want you to code along, break things, witness magic, and call yourself a Laravel developer by the end of this journey.
Come on a ride with me. It’ll be fun, I promise!
Computer requirements
The things that you need to make a Laravel web app run:
- Nginx (Or a similar webserver to handle HTTP requests)
- PHP (We’ll use PHP 8.1)
- MySQL (Laravel supports MariaDB, PostgreSQL, SQLite, and SQL Server too)
- A bunch of PHP extensions
- Composer
Depending on your OS, there are a few options available:
Mac
I recommend Valet. It is lightweight and the go-to choice of many devs.
Laravel Sail is a great choice too for Docker fans.
Linux
Laravel Sail is easier for new Linux users.
If you are comfortable with Linux, like me, go with the direct installations.
Windows
I recommend Laragon. It is not from the official Laravel team but works well.
Other good choices are Laravel Sail if you are comfortable with Docker. or Homestead if you have a powerful computer that can run a virtual environment.
A note on Composer
If you haven’t come across Composer before, it’s the dependency manager for PHP. Our project depends on the Laravel framework. And the framework has a lot of other dependencies.
Using the Composer allows us to easily install and update all these direct dependencies and nested dependencies. That results in code reusability which is the reason frameworks can offer such a huge number of features.
Setup the project
Once your computer is prepared to run a Laravel web app, fire your first command to create the project.
composer create-project laravel/laravel my-blog
This command does three things:
- Creates a new directory named
my-blog
- Clones the Laravel skeleton application code into it
- Runs the
composer install command to install the dependencies
As you may have guessed from the project name, we are developing a simple blog as our sample Laravel web app today.
A core PHP (non-framework) project starts from an empty directory, but a Laravel project starts with the skeleton app to get you up and running.
View in the browser
Many developers use Laravel’s local development server to view the web app during development. For that open terminal, cd into the project directory, and fire:
php artisan serve
You will be presented with a URL. Open that and you’ll see Laravel’s default page.
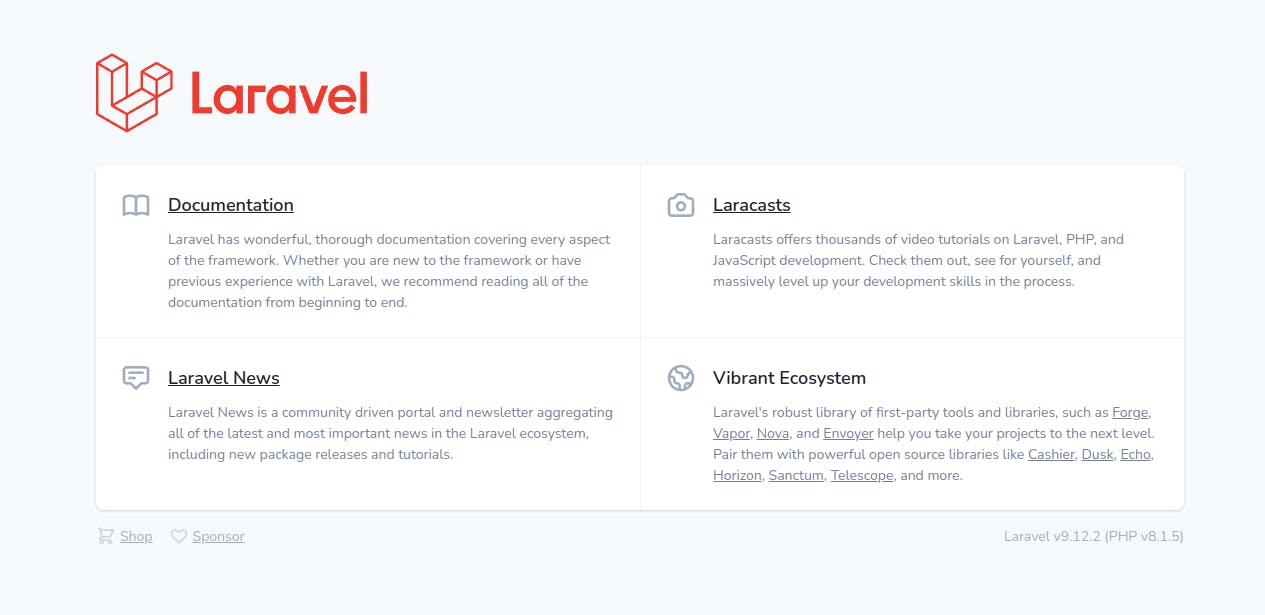
Yay. It’s running. Great start.
I recommend using nginx to manage your local sites. You need to use it for production anyway.
Relax
There are many files and directories in the default Laravel web app structure. Please do not get overwhelmed. They are there for a reason and you do not need to know all of them to get started. We will cover them soon.
Create a database
You may use your favorite GUI tool or log in to the database server via console and create a database. We will need the DB name and user credentials soon.
While a Laravel web app can run even without a DB, why would you use Laravel then?
It’s like going to McDonald’s and ordering only a Coke. Okay, some people do it. 😵💫
Understanding the project configuration
The configuration values of a Laravel project can be managed from various files inside the config directory. Things like database credentials, logging setup, email sending credentials, third-party API credentials, etc.
The config values of your local environment will be different from the ones on the production server. And if multiple team members are working on the project, they may also need to set different config values on their local computers. But, the files are common for all.
Hmmm… How could that be managed then?
Laravel uses PHP dotenv to let you configure project config values specific to your environment. The .env file is used for the same. It is not committed to the version control system (git) and everyone has their local copy of it.
The Laravel skeleton app creates the .env file automatically when you run the composer create-project command. But when you clone an existing project, you need to duplicate it from the .env.example file yourself.
Working with the .env file
While there are many config values you can set in the .env file, we will discuss a few important ones only:
APP_NAME: A sane default. You may wish to change to ‘My Awesome Blog’APP_ENV: Nothing to change. Set this to ‘production’ on the live site.APP_KEY: Used for encryption. Automatically set by the composer create-project command. If you clone an existing project, run the php artisan key:generate command to set it.DB_*: Set respective config values here.
Setting these should get you started. You may update others in the future.
The public directory
Laravel instructs that the public directory must be the entry point for all the HTTP requests to your project. That is for security reasons. Your .env file must not be accessible from the outside.
Please do not try any hack around setting the project root to the public directory. If your host doesn’t allow it, change your host.

You already know a bunch of fundamental Laravel concepts now. Doing well!
Your first database table
Let us start with the articles table. The schema can be:
| id |
integer |
| title |
varchar |
| content |
text |
| is_published |
boolean (default: false) |
| created_at |
datetime |
| updated_at |
datetime |
Challenges
In a non-framework project, we create and manage the tables manually. A few of the issues that we face are:
- It is hard to track exactly when a column was added/updated in a table.
- You must make necessary DB schema changes to the production site manually during deployments.
- If multiple team members are working on the project, each one has to manually perform schema updates to their local database to keep the project working.
With Laravel and other backend frameworks, Migrations solve these issues. Did you ask how? Read on.
Database migrations
Migrations are nothing but PHP files that define the schema using pre-defined syntax. The Laravel framework provides a command to ‘migrate’ the database i.e. apply the latest schema changes.
Let us not stress over the theory much. It will make sense once you practically make one. Please open the terminal (you should be inside the project directory) and fire the following command.
php artisan make:migration create_articles_table
The framework should have created a brand new file inside the database/migrations directory with some default content. The name of the file would be in the format of DATE_TIME_create_articles_table.php.
Please open the file in your favorite text editor/IDE (mine is VS Code). And make changes in the up() method to make it look like the following:
Schema::create('articles', function (Blueprint $table) {
$table->id();
$table->string('title');
$table->text('content');
$table->boolean('is_published')->default(false);
$table->timestamps();
});
The code should speak for itself. That is the beauty of Laravel.
Table generation in a snap
Ready to witness magic?
Run the following command to migrate the database:
php artisan migrate
The articles table will appear in your database now. Yeah, you saw it right. And the same command can be run on production and by the team members to create the table. They do not need to ask you for the table name or column details. We have all been there.
Tables can be created, updated, and removed with artisan commands in Laravel. You’ll never need to manually manage the tables in your database.
Fun fact: You can run the php artisan migrate command any number of times without affecting your DB.
Note: You’d find that many other tables were also generated. That is because Laravel comes with a few migration files out of the box. We won’t get into the details but you can update/remove them as needed in your actual projects.
Eloquent ORM
I am excited to share one of the most loved Laravel weapons with you: Eloquent

If you’re new to the term ‘ORM’, it’s a technique where each database table is represented as a PHP class, and each table record is represented as an object of that class.
If you haven’t experienced the power of objects before, fasten your seatbelt. It’ll be an incredible ride with Eloquent.
Please fire the following command now:
php artisan make:model Article
A new file called Article.php should have been created inside the app/Models directory. It’s a blank class with one trait which we can skip for the time being.
Tip: You can create the model and migration files by firing a single command: php artisan make:model Article --migration
All the database interaction is generally done using Eloquent models in Laravel web apps. There is no need to play directly with the database tables in most cases.
Convention over configuration
Laravel, like many other frameworks, follows some conventions. You may not find the complete list of conventions but following the code examples as per the official documentation goes a long way.
Our model name is Article. And Eloquent will assume the table name to be the plural (and snake cased) version of it i.e. articles. We can still specify the table name if the convention can’t be followed in some exceptional cases.
Similar conventions are followed for the primary key (id) and the timestamps (created_at and updated_at) as most of the tables need them. You need to specify them inside the Eloquent model only if they are different from the default values. Again, no need to write that boilerplate code in most cases. 🤗
All clear till now? Good.. Next plan is to add articles and then list them.
Routes
The endpoints (or URLs) in a core PHP project are decided by files. If the user opens ‘domain.com/about.php’ in the browser, the about.php file gets executed.
But for Laravel web apps, the HTTP server (nginx/apache) is instructed to serve all requests to public/index.php. That file boots the framework and looks at the routes to check whether there is a respective endpoint defined for the requested URL.
There are numerous benefits to this route pattern compared to the traditional way. One of the main benefits is control. Just like they keep only one main entrance gate for buildings for better security, the route pattern allows us to control the HTTP traffic at any moment in time.
Your first route
We have the articles table but no articles yet. Let’s add some. Please open the routes/web.php file in the text editor and add:
use App\Http\Controllers\ArticleController;
Route::get('/articles/create', [ArticleController::class, 'create']);
You just defined a new route where the endpoint is /articles/create. When the user opens that URL in the browser, the create() method of the ArticleController will be used to handle the request.
I have already assumed that you know a bit about the MVC architecture so let’s jump straight into the code.
The controllers
You can either create a controller class in the app/Http/Controllers directory manually or use this command:
php artisan make:controller ArticleController
The controller code is a one-liner for this endpoint. All we need to do is display the add article page to the user.
<?php
namespace App\Http\Controllers;
class ArticleController extends Controller
{
public function create()
{
return view('articles.create');
}
}
Simple enough, we let the view file deliver the page.
The add article page view
The view files of Laravel are powered by the Blade templating engine. The extension of the view files is .blade.php and you can write HTML, PHP, and blade-syntax code to them.
Getting into the details of Blade is out of the scope of this article. For now, we will write simple HTML to keep things moving. As mentioned, we will also stay away from the designing part.
Please create a new file named created.blade.php in the resources/views/articles directory and add the following code:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Add Article</title>
</head>
<body>
<form action="/articles" method="POST">
@csrf
<input type="text" name="title" placeholder="Title">
<textarea name="content" placeholder="Content"></textarea>
<input type="checkbox" name="is_published" value="1"> Publish?
<input type="submit" value="Add">
</form>
</body>
</html>
If the CSRF thing is new for you, the CSRF protection page inside the Laravel documentation does a great job explaining it.
The respective POST route
Route::post('/articles', [ArticleController::class, 'store']);
This route will handle the HTML form submission.
We are following the resource controller convention here. It is not compulsory but most people do follow it.
Congrats! You’re more than halfway there and believe me, it’s easier from here.
You’ll fall in love with the Validation features of Laravel. It is so easy to validate input data that you would want to do it.
Let’s see how:
use Illuminate\Http\Request;
public function store(Request $request)
{
$validated = $request->validate([
'title' => ['required', 'string', 'max:255', 'unique:articles'],
'content' => ['required', 'string'],
'is_published' => ['sometimes', 'boolean'],
]);
}
We are adding the store() method to the controller and validating the following rules with just four lines of code:
- The ‘title’ and ‘content’ input fields must be provided, must be string, and cannot be empty.
- A maximum of 255 characters can be passed for the ‘title’ input.
- The ‘title’ cannot be the same as the title of any other existing articles (Yes, it fires a DB query).
- The ‘is_published’ input may be passed (only if checked) and the value has to be a boolean when passed.
It still blows my mind 🤯 how can it be so easy to validate the inputs of a request.
Laravel offers an optional Form Request feature to move the validation (and authorization) code out of the controller to a separate class.
Display validation errors
The surprise is not over yet. If the validation fails, Laravel redirects the user back to the previous page and sets the validation errors in the session automatically. You can loop through them and display them on the page as per your design.
Generally, the code to display the validation errors is put in the layout files for reusability. But for now, you can put it in the create.blade.php file.
<body>
@if ($errors->any())
<ul>
@foreach ($errors->all() as $error)
<li></li>
@endforeach
</ul>
@endif
// ...
This piece of code uses Blade directives @if and @foreach to display the validation errors in a list.
If you were to do the same code without Blade directives, it would look like:
<body>
<?php if ($errors->any()) { ?>
<ul>
<?php foreach ($errors->all() as $error) { ?>
<li><?php echo $error; ?></li>
<?php } ?>
</ul>
<?php } ?>
// ...
Feel the difference? You get it!
Save article details to the database
Open the controller again and append the following code to the store() method.
use App\Models\Article;
public function store(Request $request)
{
Article::create($validated);
}
That’s it! Did you expect the article saving code to be 10 lines long? 😃
This single line will add the new article with the submitted form details in the table. impressive! I know how you feel.
I invite you to go ahead and submit that form now.
Do not worry if you face an error like the following. Ours is a developer’s life.

Mass assignment
The create() method of the Eloquent model accepts an array where keys are the column names and values are, well, the values.
In our example, we are passing the array of validated inputs to the create() method. But many developers use all of the inputs from the POST request which results in a security vulnerability ⚠️. Users can submit the form with some extra columns which are not supposed to be controlled by them (like id, timestamps, etc.)
Laravel Eloquent enables mass assignment protection out-of-the-box to prevent that. It cares for you.
And you need to specifically inform Eloquent about how you wanna deal with mass assignments. Please open the model file and append the following line:
protected $fillable = ['title', 'content', 'is_published'];
Cross your fingers again, open the browser, and submit that form. With luck, the article should successfully be stored in the database table now. Bingo!
Redirect and notification
You would want to give feedback to the user with a notification after the successful creation of a new article.
Laravel makes it a cinch. Open the store() method of the controller again:
return back()->with('message', 'Article added successfully.');
This is what makes developers fall in love with Laravel. It feels like you’re reading plain English.
The user gets redirected back and a flash session variable is set. A flash session variable is available for one request only and that is what we want.
Again, the handling of notifications is generally done in the layout files using some Javascript plugins. For now, you may put the following code in the create.blade.php for the demo.
<body>
@if (session('message'))
<div>
</div>
@endif
// ...
Add one more article using the form and you would be greeted with a success message this time.
List of articles
I assume you would have added some articles while testing the add article functionality. Let’s list them on the page now. First, please add a new route:
Route::get('/articles', [ArticleController::class, 'index']);
You read it right. We are using the same URL but the HTTP method is different. When the user opens the ‘/articles’ page in the browser (a GET request), the controller’s index() method will be called. But the store() method is used when the form is submitted to add a new article (a POST request).
The controller code
Here’s how you fetch records from the database and pass them to the view file.
public function index()
{
$articles = Article::all();
return view('articles.index', compact('articles'));
}
I am sure you are not surprised this time. You already know the power of Laravel Eloquent now.
The $articles variable is an instance of Collection (not an array) and we will briefly cover that soon.
Simple table to display articles
Please create another file named index.blade.php in the resources/views/articles directory. I will cover just the body tag:
<body>
<table border="1">
<thead>
<tr>
<th>Title</th>
<th>Content</th>
<th>Published</th>
</tr>
</thead>
<tbody>
@foreach ($articles as $article)
<tr>
<td></td>
<td></td>
<td></td>
</tr>
@endforeach
</tbody>
</table>
</body>
The code is straight forward and you may now view the articles you have added on the /articles page now.
The limit string helper is provided by Laravel.
Tip: It is better to display paginated records (articles) when there are hundreds of them. Laravel has got your back for that too.
Pat your back. You did a great job. You can call yourself a Laravel developer now.
Limiting the scope of this article
Okay, everything comes to an end. So is this tutorial.
Implementing the authentication feature to this project is one of the things I wished to include in this article but it is already too long.
And before discussing authentication, we have to learn about password hashing, middleware, and sessions in Laravel.
Another topic I wanted to touch on is Eloquent relationships. This feature is so powerful you’d never want to go back to the old days.
Goes without saying that tests are a must for your production-level projects. And Laravel supports you with testing too.
In short, we have barely scratched the surface here. Drop a comment if you want me to write on the subject more. We can continue this example project and make a series of articles.
Meanwhile, let me share some other Laravel goodies you may wanna explore.
Extras
Collections: Arrays with superpowers. Offers various methods to transform your arrays into almost any format.
Mails: I have never sent an email to a real person from the development site thanks to Laravel. Which I had done multiple times before it.
Queues: Delegating tasks to the background processes gives a huge performance boost. Laravel Horizon + Redis combo provides scalability with simplicity.
Logging: Enabled by default. All the app errors are logged inside the storage/logs directory. Helps with debugging a lot.
File Storage: Managing user-uploaded files doesn’t have to be complex. This feature is built on top of the stable and mature Flysystem PHP package.
Factories and Seeders: Quick generation of dummy data of your tables for demo and tests.
Artisan commands: You’ve already used some. There are many more in the basket. And you can create custom ones too. Quite helpful when combined with the scheduler.
Task scheduling: I bet you’d agree that setting up cronjobs the right way is hard. Not in Laravel. You’ve to see it to believe it.
And many more…
What next?
There are a thousand and seventy more things we can do for this project. If you are interested, here are a few options:
- Add register/login functionality
- Let the user enter markdown for content for better formatting
- Generate slug for the articles automatically
- Allow users to edit/delete articles
- Let users attach multiple tags to the articles

Okay, stop.
You have created a small project in Laravel and learned the basics. Time to celebrate. 🥳
I hope you enjoyed the journey as much as I did. Feel free to ask any questions below.
And If you know someone who might be interested in learning Laravel, share this article with them right away.
Bye.
PS – I would be very happy if you could push your code to a repository and share the link with me.






















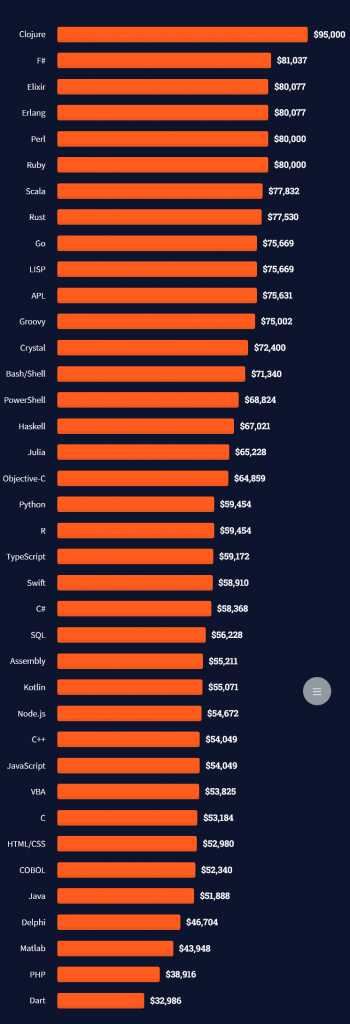
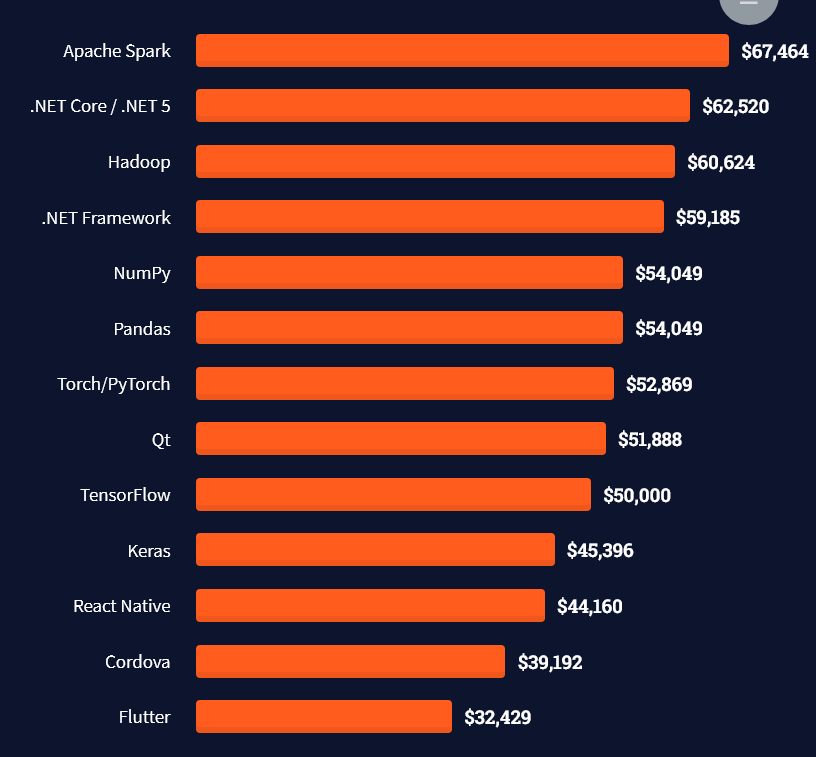
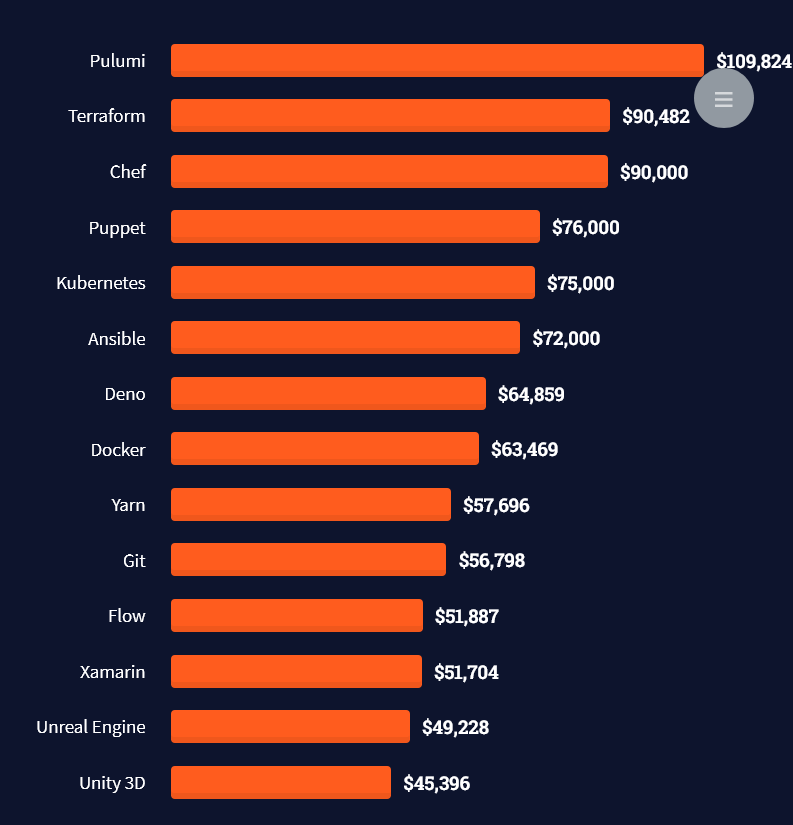
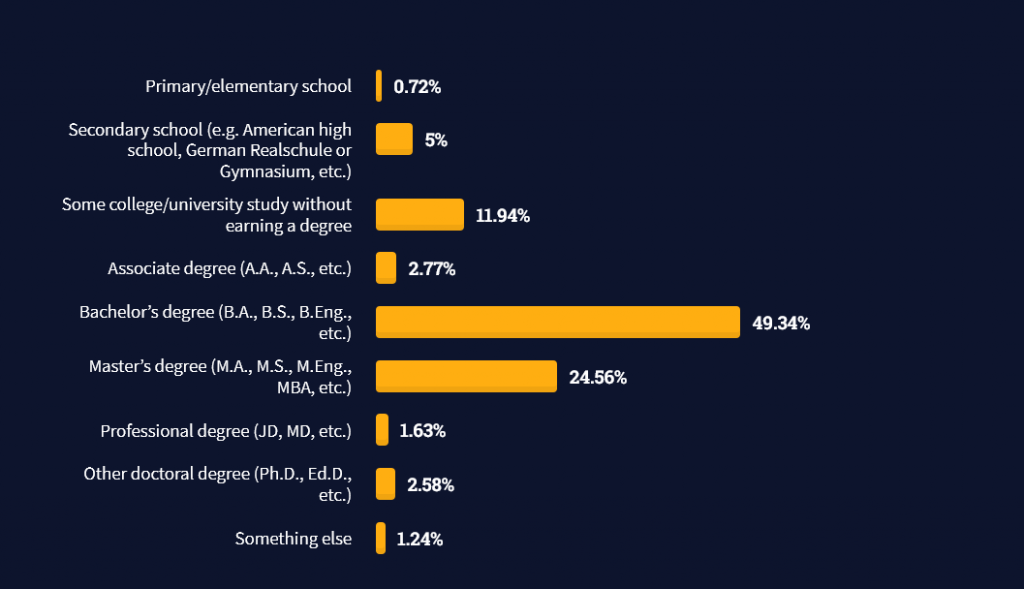
 Question: How much does a Database Engineer in the US make per year?
Question: How much does a Database Engineer in the US make per year?
 Note: This is the most comprehensive salary meta-study of database engineer income in the world, to the best of my knowledge!
Note: This is the most comprehensive salary meta-study of database engineer income in the world, to the best of my knowledge!
 Note: Do you want to create your own thriving coding business online? Feel free to check out our
Note: Do you want to create your own thriving coding business online? Feel free to check out our 


 Tip: An excellent start to turbo-charge your freelancing career (earning more in less time) is our
Tip: An excellent start to turbo-charge your freelancing career (earning more in less time) is our