
RDS is a Database as a Service (DBaaS) that automatically configures and maintains your databases in the AWS cloud. The user has limited power over specific configurations in comparison to running MySQL directly on Elastic Compute Cloud (EC2). But RDS is a convenient service, as long as you can live with the instances and configurations that it offers.
Amazon RDS currently supports various MySQL and MariaDB versions as well as the, MySQL-compatible Amazon Aurora DB engine. It does support replication, but as you may expect from a predefined web console, there are some limitations.

There are some tradeoffs when using RDS. These may not only affect the way you manage and provision your database instances, but also key things like performance, security, and high availability.
In this blog, we will take a look at the differences between using RDS and running MySQL on EC2, with focus on replication. As we will see, to decide between hosting MySQL on an EC2 instance or using Amazon RDS is not an easy task.
RDS Platform Tradeoffs
The biggest size of database that AWS can host depends on your source environment, the allocation of data in your source database, and how busy your system is.
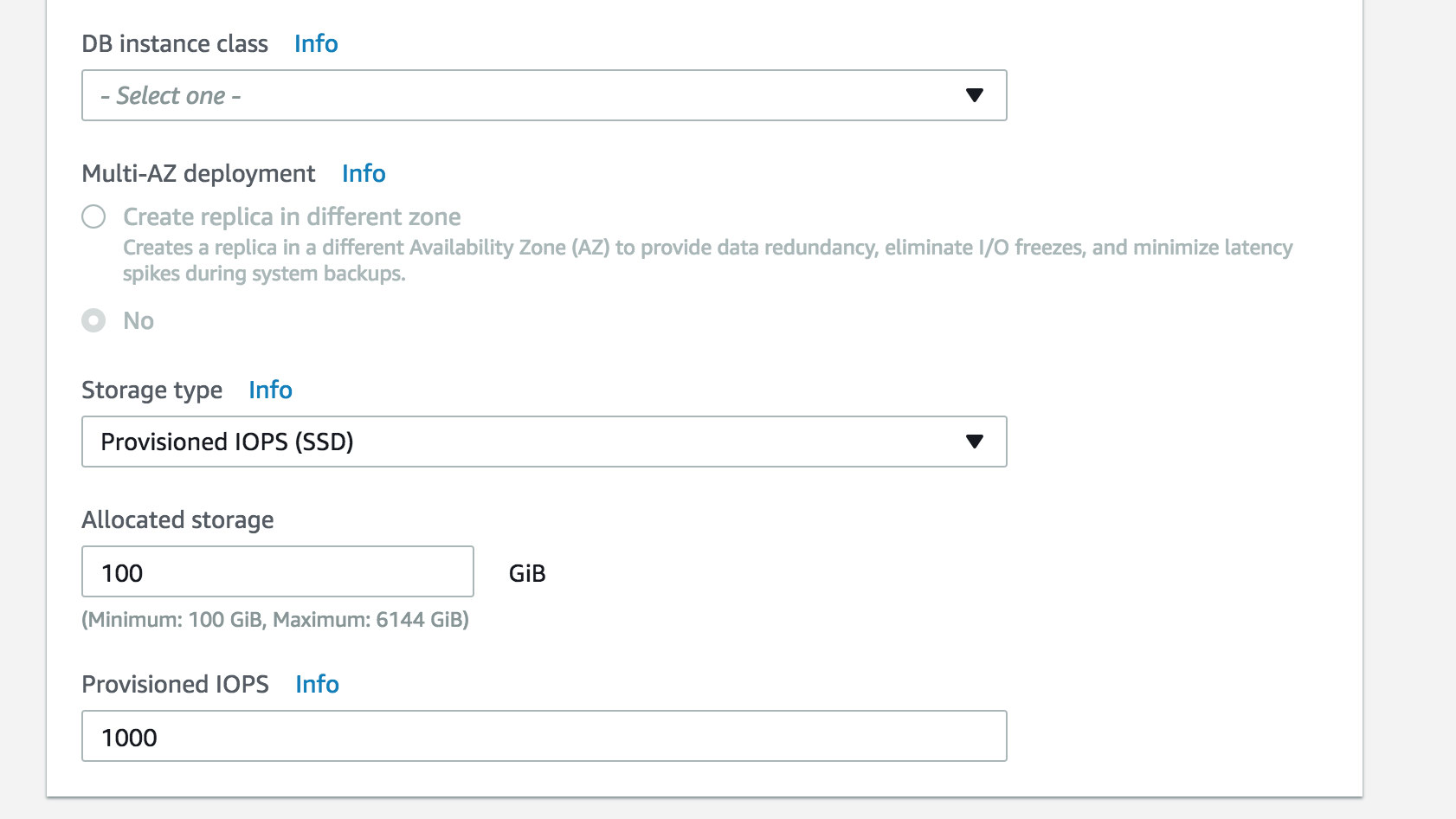
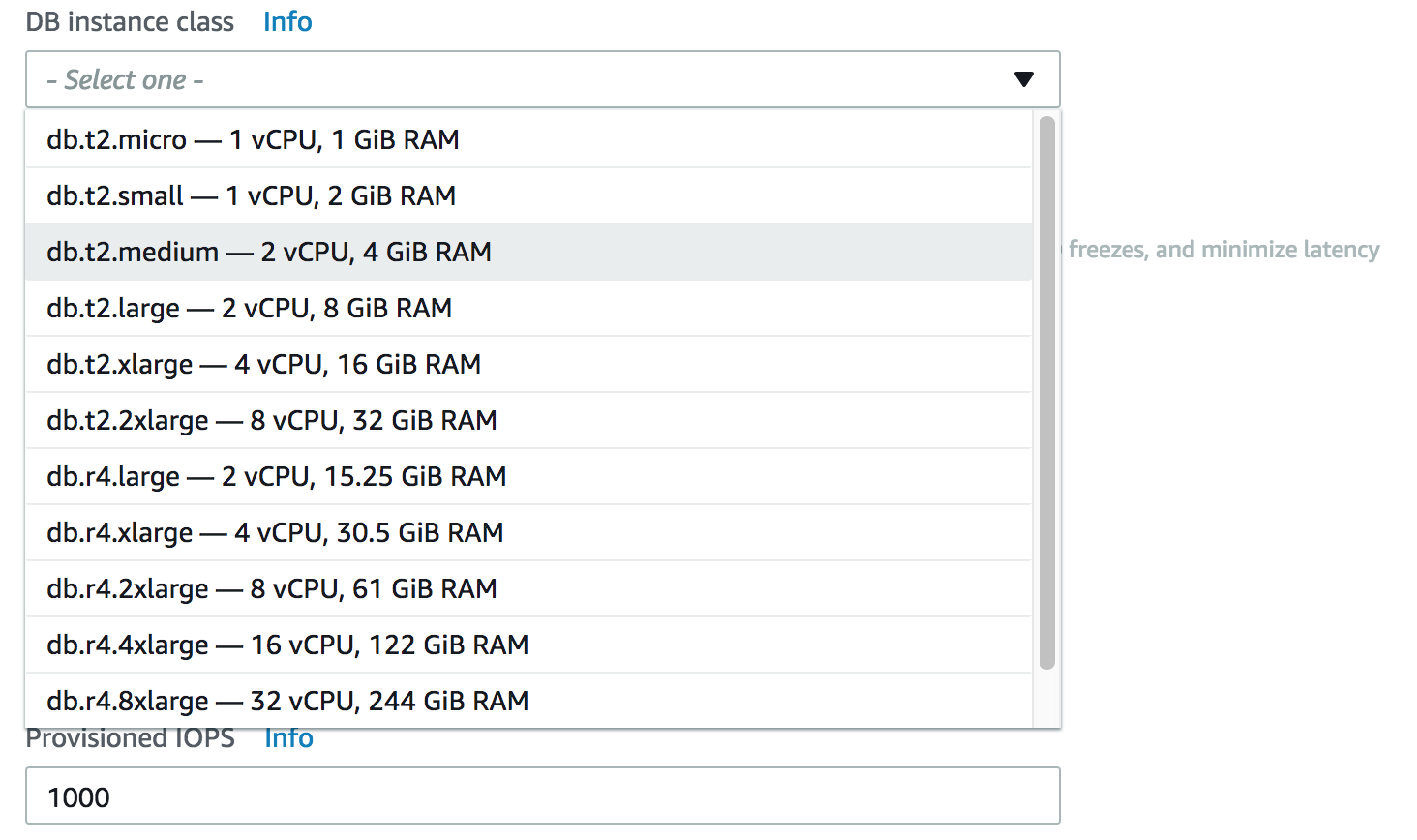
AWS is split into regions. Every AWS account has limits, per region, on the number of AWS resources that can be created. Once a limit for a resource has been reached, additional calls to create that resource will fail.

For Amazon RDS MySQL DB instances, the maximum provisioned storage limit constrains the size of a table to a maximum size of 6 TB when using InnoDB file-per-table tablespaces.
InnoDB file-per-table feature is something that you should consider even if you are not looking to migrate a big database into the cloud. You may notice that some existing DB instances have a lower limit. For example, MySQL DB instances created prior to April 2014 have a file and table size limit of 2 TB. This 2-TB file size limit also applies to DB instances or Read Replicas created from DB snapshots taken before April 2014.
One of the key differences which affects the way you set up and maintain database replication is the lack of SUPER user. To address this limitation, Amazon introduced stored procedures that take care of various DBA tasks. Below are the key procedures to manage MySQL RDS replication.
Skip replication error:
CALL mysql.rds_skip_repl_error;Stop replication:
CALL mysql.rds_stop_replication;Start replication
CALL mysql.rds_start_replication;Configures an RDS instance as a Read Replica of a MySQL instance running outside of AWS.
CALL mysql.rds_set_external_master;Reconfigures a MySQL instance to no longer be a Read Replica of a MySQL instance running outside of AWS.
CALL mysql.rds_reset_external_master;Imports a certificate. This is needed to enable SSL communication and encrypted replication.
CALL mysql.rds_import_binlog_ssl_material;Removes a certificate.
CALL mysql.rds_remove_binlog_ssl_material;Changes the replication master log position to the start of the next binary log on the master.
CALL mysql.rds_next_master_log;While stored procedures take care of a number of tasks, it is a bit of a learning curve. Lack of SUPER privilege can also create problems in using external replication monitoring.
Amazon RDS does not currently support the following:
- Global Transaction IDs
- Transportable Table Space
- Authentication Plugin
- Password Strength Plugin
- Replication Filters
- Semi-synchronous Replication
Last but not least – access to the shell. Amazon RDS does not allow direct host access to a DB instance via Telnet, Secure Shell (SSH), or Windows Remote Desktop Connection (RDP). You can still use the client on an application host to connect to the DB via standard tools like mysql client.
There are other limitations, as described in the RDS documentation.
High availability with MySQL on EC2

There are options to operate MySQL directly on EC2, and thereby retain control of one’s high availability options. When going down this route, it is important to understand how to leverage the different AWS features that are at your disposal. Make sure you check out our ‘DIY Cloud Database’ white paper.
To automate deployment and management/maintenance tasks (while retaining control), it is possible to use ClusterControl. Just like with RDS, you have the convenience of deploying a database setup in a few minutes via a GUI. Adding nodes, scheduling backups, performing failovers, and so on, can also be conveniently done via the GUI.
Deployment
ClusterControl can automate deployment of different high availability database setups – from master-slave replication to multi-master clusters. All the main MySQL flavours are supported – Oracle MySQL, MariaDB and Percona Server. Some initial setup of VPC/security group is required, and these are well described in the DIY Cloud Database whitepaper. Note that similar concepts apply, whether it is AWS or Google Cloud or Azure
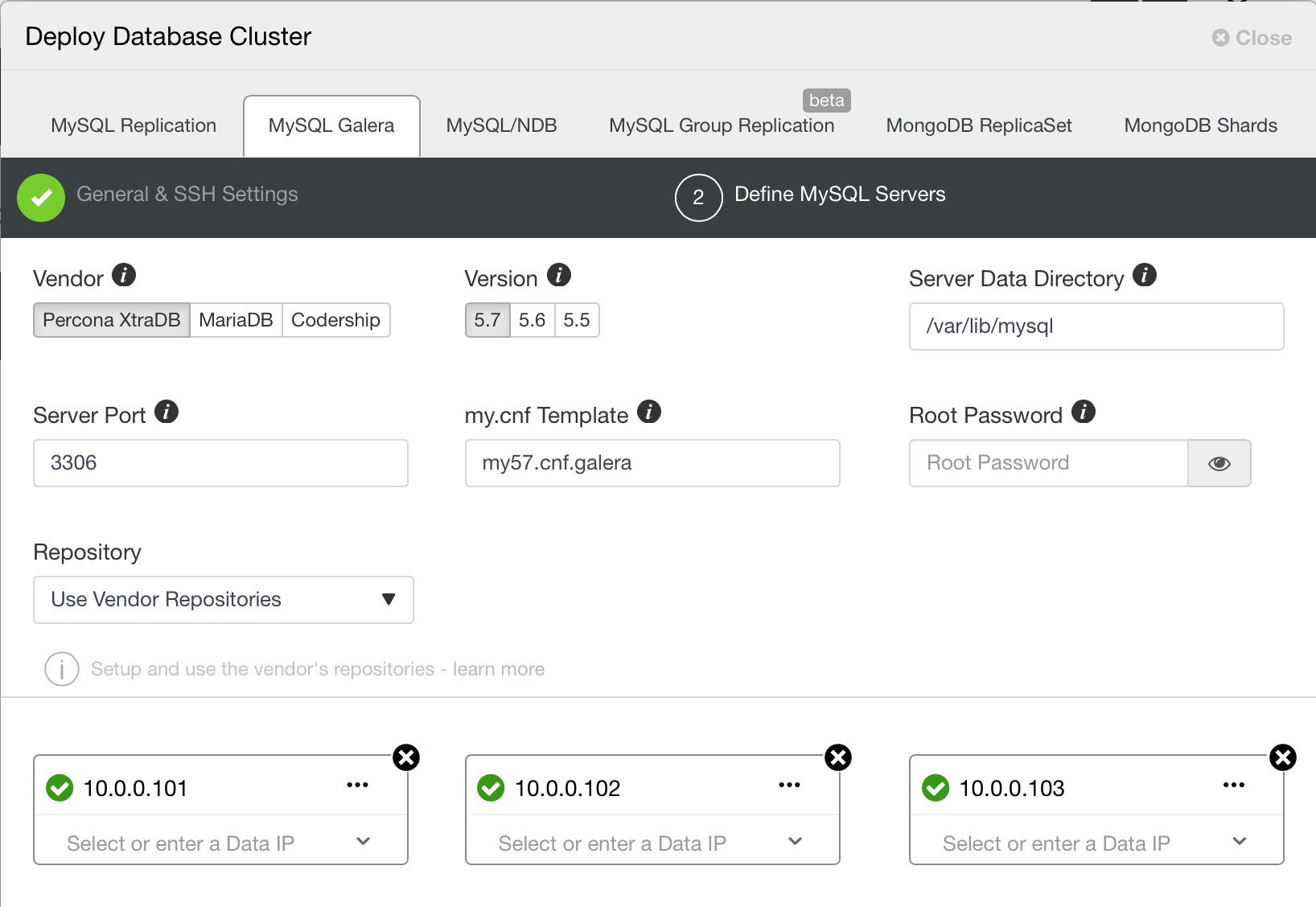
Galera Cluster is a good alternative to consider when deploying a highly available MySQL service. It has established itself as a credible replacement for traditional MySQL master-slave architectures, although it is not a drop-in replacement. Most applications can still be adapted to run on it. It is possible to define different segments for databases that span across multiple AWS regions.
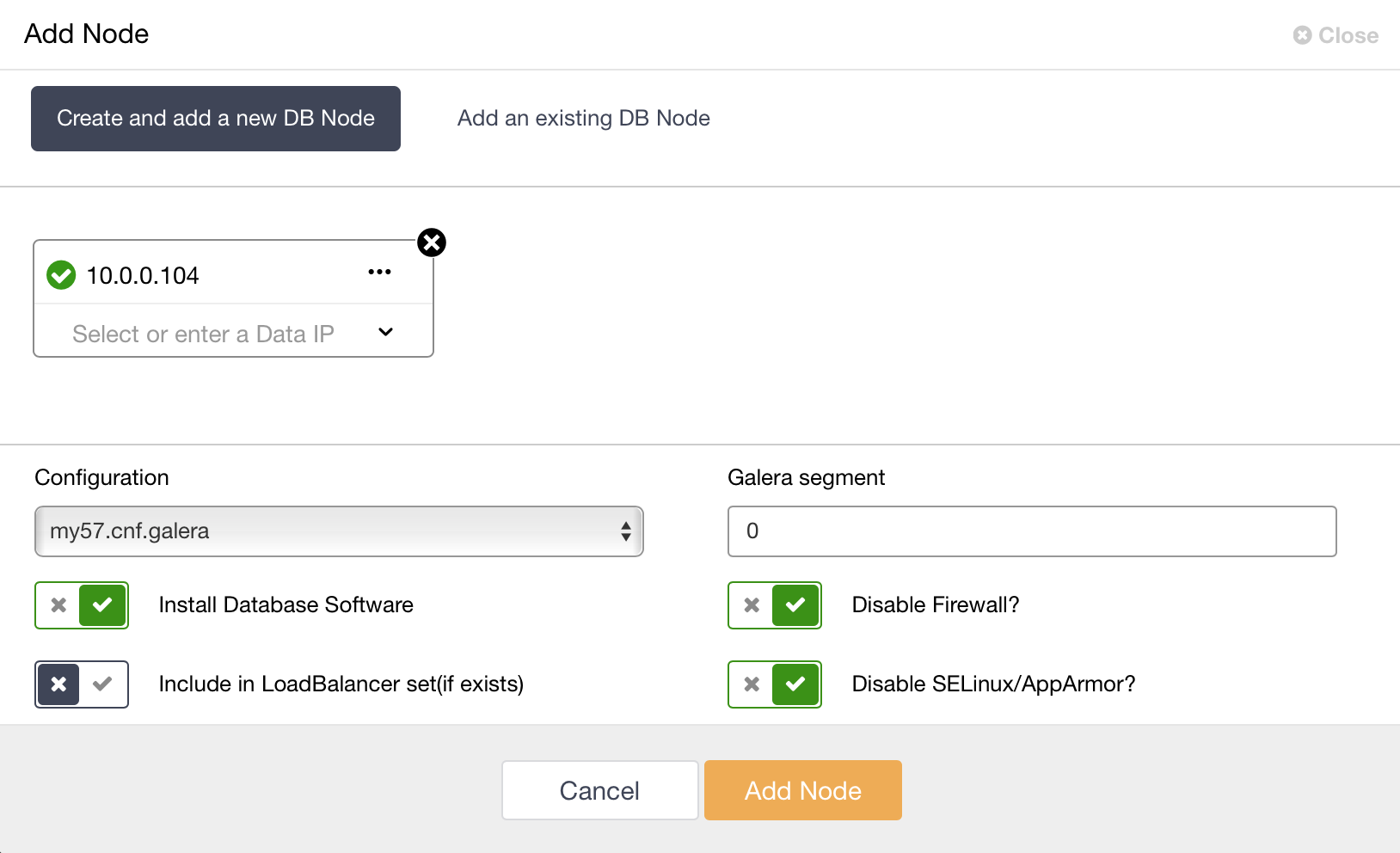
It is possible to setup ‘hybrid replication’ by combining synchronous replication within a Galera Cluster and asynchronous replication between the cluster and one or more slaves. Options like delaying the slave gives an additional level of protection to the data.
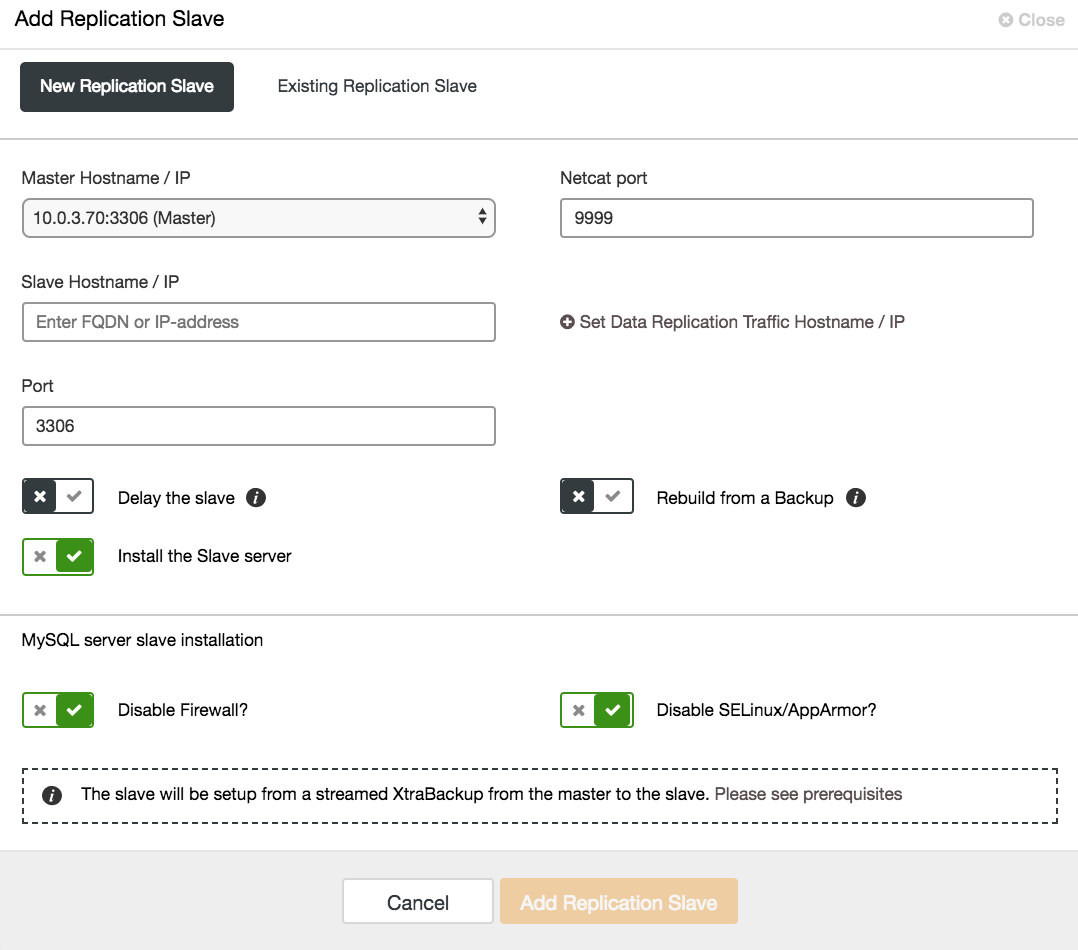
Proxy layer
To achieve high availability, deploying a highly available setup is not enough. The applications have to somehow know which nodes are working and which ones are not. Changes in topology, e.g. moving a master to another host, also need to be propagated somehow so as to avoid errors in the application layer. ClusterControl supports deployments of proxies like HAProxy, MaxScale, and ProxySQL. For HAProxy and ProxySQL, there are additional options to deploy redundant instances with Keepalived and VirtualIP.
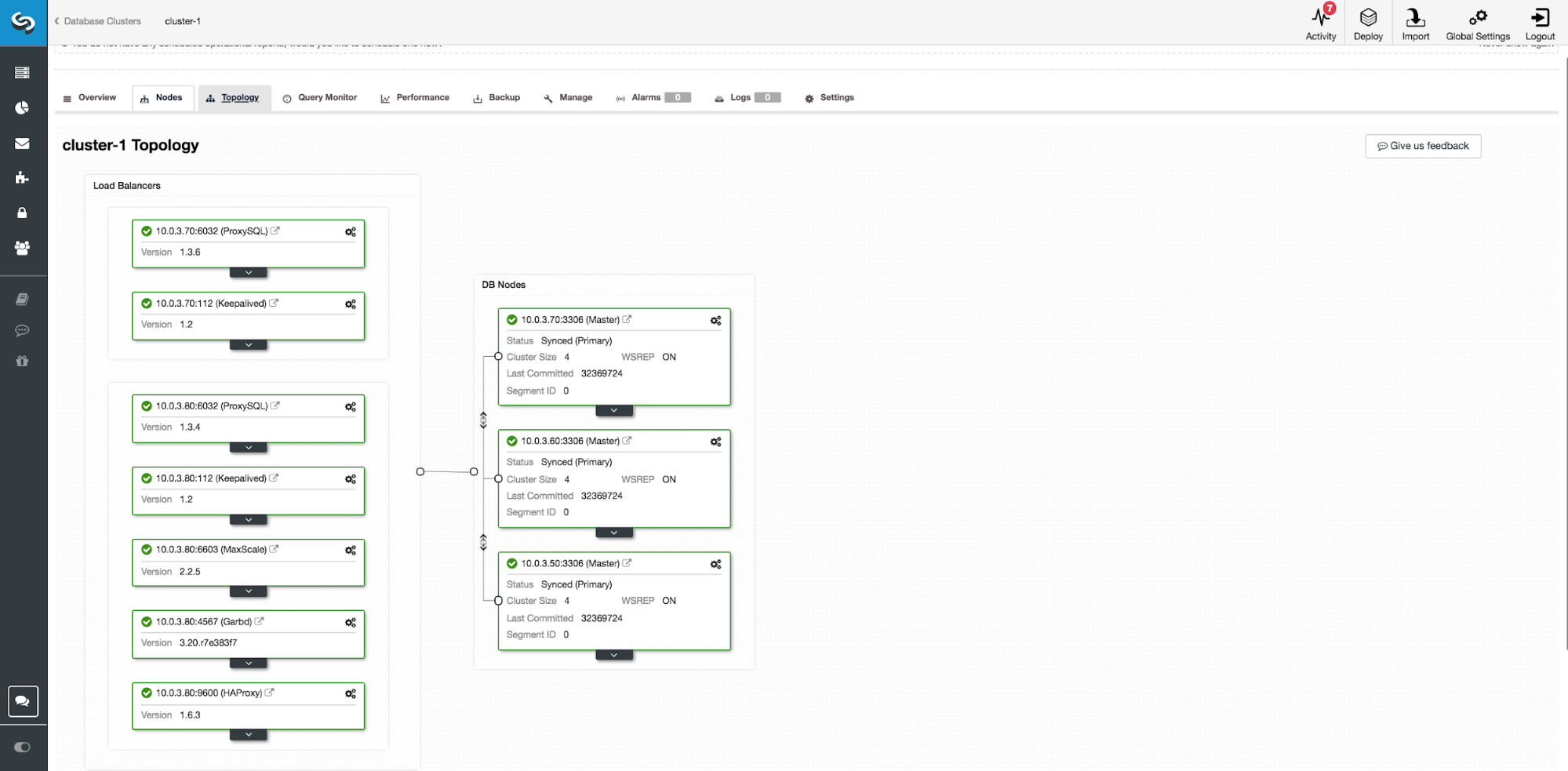
Cross-region replica
Amazon RDS provides read replica services. Cross-region replicas give you the ability to scale reads, as AWS has its services in a number of datacenters around the world. All read replicas are accessible and can be used for reading in a maximum number of five regions. These nodes are independent and can be used in your upgrade path, or can be promoted to standalone databases.
In addition to that, Amazon offers Multi-AZ deployments based on DRBD, synchronous disk replication. How is it different from Read Replicas? The main difference is that only the database engine on the primary instance is active, which leads to other architectural variations.
As opposed to read replicas, database engine version upgrades happen on the primary. Another difference is that AWS RDS will failover automatically with DRBD, while read replicas (using asynchronous replication) will require manual operations from you.
Multi-AZ failover on RDS uses a DNS change to point to the standby instance, according to Amazon this should happen within 60-120 seconds during the failover. Because the standby uses the same storage data as the primary, there will probably be transaction/log recovery. Bigger databases may spend a significant amount of time on InnoDB recovery, so please consider that in your DR plan and RTO calculation.
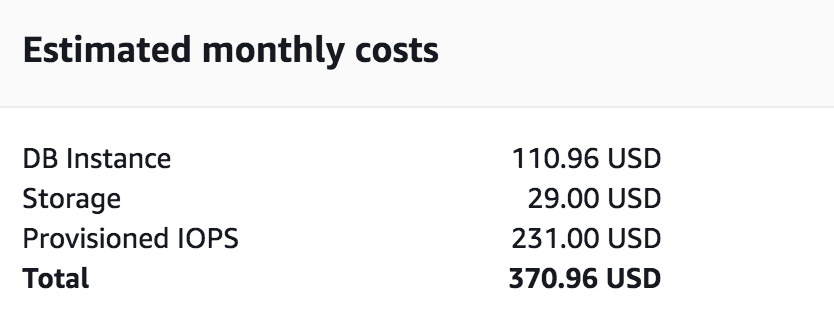
Of course, this goes with additional cost. Let’s take a look at some basic example. The cost of db.t2.medium host with 2vCPU, 4GB ram is 185.98 USD per month, the price will double when you enable Multizone (MZ) replica to 370.98 UDB. The price will vary by region but it will double in MZ.
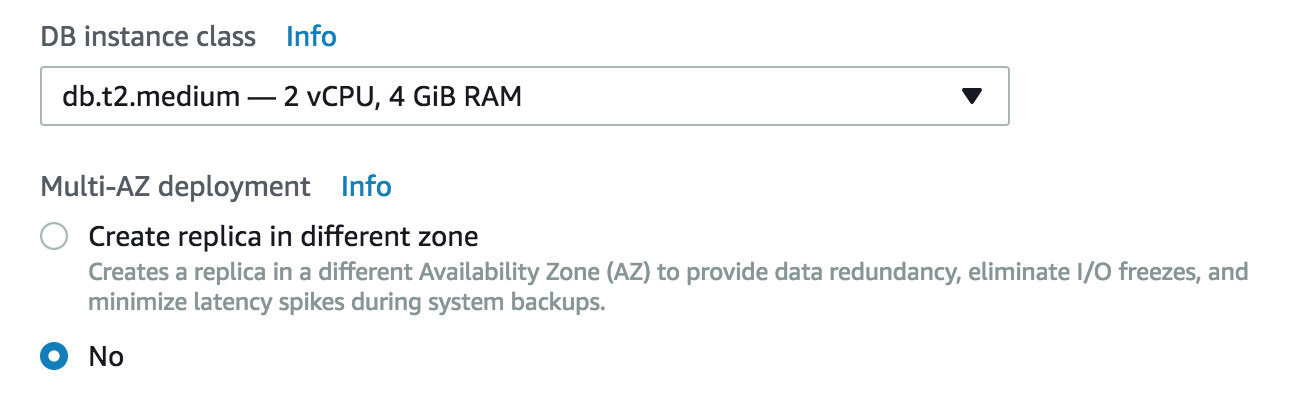
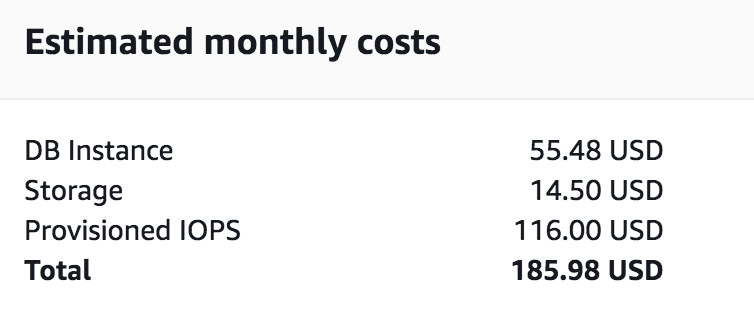
In order to achieve the same with EC2, you can deploy your virtual machines in different regions. Each AWS Region is completely independent. The setting of AWS Region can be changed in the console, by setting the EC2_REGION environment variable, or it can be overridden by using the –region parameter with the AWS Command Line Interface. When your set of servers are ready, you can use ClusterControl to deploy and monitor your replication. You can also manually set up replication through the console using standard commands.
Cross technology replication
It is possible to setup replication between an Amazon RDS MySQL or MariaDB DB instance and a MySQL or MariaDB instance that is external to Amazon RDS. This is done using standard replication method in mysql, through binary logs. To enable binary logs, you need to modify the my.cnf configuration. Without access to the shell, this task became impossible in RDS. It’s done in a not so obvious way. You have two options. One is to enable backups – set automated backups on your Amazon RDS DB instance with retention to higher than 0. Or enable replication to a prebuilt slave server. Both tasks will enable binary logs which you can later on use for your replication.
Maintain the binlogs in your master instance until you have verified that they have been applied on the replica. This maintenance ensures that you can restore your master instance in the event of a failure.
Another roadblock can be permissions. The permissions required to start replication on an Amazon RDS DB instance are restricted and not available to your Amazon RDS master user. Because of this, you must use the Amazon RDS mysql.rds_set_external_master and mysql.rds_start_replication commands to set up replication between your live database and your Amazon RDS database.
Monitor failover events for the Amazon RDS instance that is your replica. If a failover occurs, then the DB instance that is your replica might be recreated on a new host with a different network address. For information on how to monitor failover events, see Using Amazon RDS Event Notification.
In the below example, we will see how to enable replication from RDS to an external DB located on an EC2 instance.
You should have binary logs enabled, we use an RDS slave here.
Specify the number of hours to retain binary logs.
mysql -h RDS_MASTER -u<username> -u<password>
call mysql.rds_set_configuration('binlog retention hours', 7);On RDS MASTER, create replication user with the following commands:
CREATE USER 'repl'@'ec2DBslave' IDENTIFIED BY 's3cr3tp4SSw0rd';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'ec2DBslave';On RDS SLAVE, run the commands:
mysql -u<username> -u<password> -h RDS_SLAVE
call mysql.rds_stop_replication;
SHOW SLAVE STATUS; Exec_Master_Log_Pos, Relay_Master_Log_File.On RDS SLAVE, run mysqldump with the following format:
mysqldump -u<username> -u<password> -h RDS_SLAVE --routines --triggers --single-transaction --databases DB1 DB2 DB3 > mysqldump.sqlImport the DB dump to external database:
mysql -u<username> -u<password> -h ec2DBslave
tee import_database.log;
source mysqldump.sql;CHANGE MASTER TO
MASTER_HOST='RDS_MASTER',
MASTER_USER='repl',
MASTER_PASSWORD='s3cr3tp4SSw0rd',
MASTER_LOG_FILE='<Relay_Master_Log_File>',
MASTER_LOG_POS=<Exec_Master_Log_Pos>;Create a replication filter to ignore tables created by AWS only on RDS
CHANGE REPLICATION FILTER REPLICATE_WILD_IGNORE_TABLE = ('mysql.rds\_%');Start replication
START SLAVE;Verify replication status
SHOW SLAVE STATUS;That’s it for now. Managing MySQL on AWS is a big topic. Do let us know your thoughts in the comments section below.
via Planet MySQL
Comparing RDS vs EC2 for Managing MySQL or MariaDB on AWS