How to Make Everything shares a brief history of fireworks, and how they work. Then he gathers the ingredients he needs to make them from scratch, including bat droppings. The resulting fireworks made for a pretty quiet Fourth of July, but technically they still worked.
The Fourth of July is a little different today at Travis Air Force Base in Fairfield, Calif. From a report:
Instead of fireworks, 500 Intel Shooting Star drones will take to the sky to perform an aerial routine in honor of the holiday and the base’s 75th anniversary. These are the same drones that preformed at Disney World, the Super Bowl and the Olympics. One person controls the fleet of drones thanks to a sophisticated control platform that pre-plans the route of each drone. Intel engineers told me that the system can control an unlimited amount of drones. In the version I saw, the drones used GPS to stay in place and the drones lacked any collision detection sensors.
In this post we will review the most important Linux settings to adjust for performance tuning and optimization of a MySQL database server. We’ll note how some of the Linux parameter settings used OS tuning may vary according to different system types: physical, virtual or cloud. Other posts have addressed MySQL parameters, like Alexander’s blog MySQL 5.7 Performance Tuning Immediately After Installation. That post remains highly relevant for the latest versions of MySQL, 5.7 and 8.0. Here we will focus more on the Linux operating system parameters that can affect database performance.
Server and Operating System
Here are some Linux parameters that you should check and consider modifying if you need to improve database performance.
The value represents the tendency of the kernel to swap out memory pages. On a database server with ample amounts of RAM, we should keep this value as low as possible. The extra I/O can slow down or even render the service unresponsive. A value of 0 disables swapping completely while 1 causes the kernel to perform the minimum amount of swapping. In most cases the latter setting should be OK:
# Set the swappiness value as root
echo1>/proc/sys/vm/swappiness
# Alternatively, using sysctl
sysctl–wvm.swappiness=1
# Verify the change
cat/proc/sys/vm/swappiness
1
# Alternatively, using sysctl
sysctl vm.swappiness
vm.swappiness=1
The change should be also persisted in /etc/sysctl.conf:
XFS
XFS is a high-performance, journaling file system designed for high scalability. It provides near native I/O performance even when the file system spans multiple storage devices. XFS has features that make it suitable for very large file systems, supporting files up to 8EiB in size. Fast recovery, fast transactions, delayed allocation for reduced fragmentation and near raw I/O performance with DIRECT I/O.
The default options for mkfs.xfs are good for optimal speed, so the simple command:
# Use default mkfs options
mkfs.xfs/dev/target_volume
will provide best performance while ensuring data safety. Regarding mount options, the defaults should fit most cases. On some filesystems you can see a performance increase by adding the noatime mount option to the /etc/fstab. For XFS filesystems the default atime behaviour is relatime, which has almost no overhead compared to noatime and still maintains sane atime values. If you create an XFS file system on a LUN that has a battery backed, non-volatile cache, you can further increase the performance of the filesystem by disabling the write barrier with the mount option nobarrier. This helps you to avoid flushing data more often than necessary. If a BBU (backup battery unit) is not present, however, or you are unsure about it, leave barriers on, otherwise you may jeopardize data consistency. With this options on, an /etc/fstab file should look like the one below:
/dev/sda2/datastore xfs defaults,nobarrier
/dev/sdb2/binlog xfs defaults,nobarrier
ext4
ext4 has been developed as the successor to ext3 with added performance improvements. It is a solid option that will fit most workloads. We should note here that it supports files up to 16TB in size, a smaller limit than xfs. This is something you should consider if extreme table space size/growth is a requirement. Regarding mount options, the same considerations apply. We recommend the defaults for a robust filesystem without risks to data consistency. However, if an enterprise storage controller with a BBU cache is present, the following mount options will provide the best performance:
Note: The data=writeback option results in only metadata being journaled, not actual file data. This has the risk of corrupting recently modified files in the event of a sudden power loss, a risk which is minimised with a presence of a BBU enabled controller. nobh only works with the data=writeback option enabled.
ZFS
ZFS is a filesystem and LVM combined enterprise storage solution with extended protection vs data corruption. There are certainly cases where the rich feature set of ZFS makes it an essential option to consider, most notably when advance volume management is a requirement. ZFS tuning for MySQL can be a complex topic and falls outside the scope of this blog. For further reference, there is a dedicated blog post on the subject by Yves Trudeau:
Most modern Linux distributions come with noop or deadline I/O schedulers by default, both providing better performance than the cfq and anticipatory ones. However it is always a good practice to check the scheduler for each device and if the value shown is different than noop or deadline the policy can change without rebooting the server:
# View the I/O scheduler setting. The value in square brackets shows the running scheduler
cat/sys/block/sdb/queue/scheduler
noop deadline[cfq]
# Change the setting
sudo echonoop>/sys/block/sdb/queue/scheduler
To make the change persistent, you must modify the GRUB configuration file:
AWS Note: There are cases where the I/O scheduler has a value of none, most notably in AWS VM instance types where EBS volumes are exposed as NVMe block devices. This is because the setting has no use in modern PCIe/NVMe devices. The reason is that they have a very large internal queue and they bypass the IO scheduler altogether. The setting in this case is none and it is the optimal in such disks.
Ideally different disk volumes should be used for the OS installation, binlog, data and the redo log, if this is possible. The separation of OS and data partitions, not just logically but physically, will improve database performance. The RAID level can also have an impact: RAID-5 should be avoided as the checksum needed to ensure integrity is costly. The best performance without making compromises to redundancy is achieved by the use of an advanced controller with a battery-backed cache unit and preferably RAID-10 volumes spanned across multiple disks.
AWS Note: For further information about EBS volumes and AWS storage optimisation, Amazon has documentation at the following links:
Non-uniform memory access (NUMA) is a memory design where an SMP’s system processor can access its own local memory faster than non-local memory (the one assigned local to other CPUs). This may result in suboptimal database performance and potentially swapping. When the buffer pool memory allocation is larger than size of the RAM available local to the node, and the default memory allocation policy is selected, swapping occurs. A NUMA enabled server will report different node distances between CPU nodes. A uniformed one will report a single distance:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# NUMA system
numactl—hardware
available:4nodes(0–3)
node0cpus:01234567
node0size:65525MB
node0free:296MB
node1cpus:89101112131415
node1size:65536MB
node1free:9538MB
node2cpus:1617181920212223
node2size:65536MB
node2free:12701MB
node3cpus:2425262728293031
node3size:65535MB
node3free:7166MB
node distances:
node0123
0:10202020
1:20102020
2:20201020
3:20202010
# Uniformed system
numactl—hardware
available:1nodes(0)
node0cpus:01234567
node0size:64509MB
node0free:4870MB
node distances:
node0
0:10
In the case of a NUMA system, where numactl shows different distances across nodes, the MySQL variable innodb_numa_interleave should be enabled to ensure memory interleaving. Percona Server provides improved NUMA support by introducing the flush_caches variable. When enabled, it will help with allocation fairness across nodes. To determine whether or not allocation is equal across nodes, you can examine numa_maps for the mysqld process with this script:
# The perl script numa_maps.pl will report memory allocation per CPU node:
# 3595 is the pid of the mysqld process
perl numa_maps.pl</proc/3595/numa_maps
N0:16010293(61.07GB)
N1:10465257(39.92GB)
N2:13036896(49.73GB)
N3:14508505(55.35GB)
active:438(0.00GB)
anon:54018275(206.06GB)
dirty:54018275(206.06GB)
kernelpagesize_kB:4680(0.02GB)
mapmax:787(0.00GB)
mapped:2731(0.01GB)
Conclusion
In this blog post we examined a few important OS related settings and explained how they can be tuned for better database performance.
Spyros earned his stripes after more than 20 years’ experience in the IT and Telco sectors. He has direct in-depth experience of distributed systems, databases, virtualization, and application delivery. He joined Percona in 2017 as a Senior MySQL DBA in the Managed Services team.
There are some skills you hope you never need to use, but having them could be a matter of life and death: welcome to bleeding control.
BleedingControl.org, an group begun by the American College of Surgeons, has successfully campaigned for a national Stop The Bleed Day; the organization believes that many lives could be saved if ordinary citizens had some basic information on how to stop traumatic bleeding in an emergency situation. Reporter and certified EMT Tim Mak rounded up the most critical points on the day dedicated to bleeding awareness in an effort to teach more people how to save lives.
Advertisement
According to Mak, 20 percent of people who die from bleeding could have been saved with this care, and bleeding to death is the top cause of preventable death. Here’s what you need to know.
What To Look For
It is possible to bleed to death from smaller wounds, but people who bleed out often do so because they have cut an artery. You will know an artery has been severed if blood is spurting from the wound and bright red. Also, if blood is pooling, if the injured person is unconscious, or if you’re seeing a partial or full amputation. A person with a severed artery can die in 2-3 minutes.
How To Intervene
Mak provided a step-by-step guide which may seem simple, but in a scenario where someone is massively bleeding, you might be a little panicked. Simple rules help.
Advertisement
First, make sure you’re not stepping into danger. Then, call 911. Even if you’re about to stop the bleeding successfully, you want trained medical professionals to get there ASAP. Then you find the injury and apply pressure to stop the blood loss.
You may not have a tourniquet on hand, but if you do, tie it off between the blood flow and the exit wound, above the injury. If not, or if the wound is too big to be contained by a tourniquet, grab a clean cloth or hemostatic (bleeding control) gauze, if available. Pack the wound and hold it down with steady pressure. You’re trying to close off the artery and keep it closed until help can arrive. Mak advises people apply as much pressure as possible, because even if the injury is severe, the artery is fairly deep inside the body. You need to press hard to reach it and shut it off.
Advertisement
Finally, if you have the presence of mind to do so, mark the time the tourniquet or pressure was applied. This is useful information for medical professionals, as there are dangers to leaving tourniquets on too long.
These are the basics, but if you want to take a hands on class for free, Bleeding Control offers them all over the country. As Mak wrote, there’s nothing like hands-on training when it’s time to step up.
Have you ever had the need to send anonymous emails to someone? Maybe you’re discreetly declaring your love to someone. Or maybe you’re a journalist and need to secretly communicate with an informant.
There are plenty of legitimate reasons someone may want to send anonymous email. There are free online services on the web that allow you to do this. Or you can use a VPN and an anonymous burner email account (i.e. throwaway).
These days it’s very easy to send emails without having to reveal your true identity. In this article, you’ll learn how to send an anonymous email using the five most effective methods we’ve found.
1. Burner Email Account + VPN
Using a web-based email account like Gmail is a great option. You can sign up for a Gmail account without providing any actual identifying information, and then use that address as a kind of burner email account.
How to Use a Fake IP Address & Mask Yourself Online Sometimes you need to hide your IP address. Online anonymity continues to be important as privacy gets trampled. Here are some ways to cloak your I.P address and mask yourself online. Read More
.
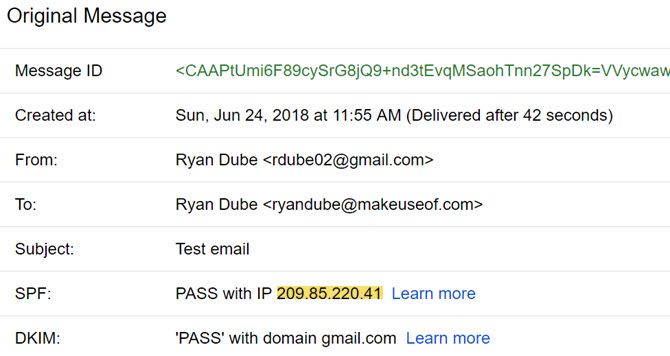
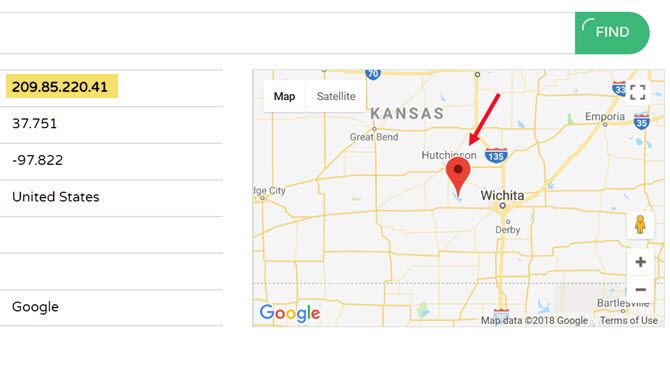
If someone were to trace the IP that show up when you send an email from the online Gmail account, it would only trace to the nearest Google server to you. Which, in my case, is the Wichita, Kansas area.
With that said, your actual IP address is stored on Google’s systems. So, if the government or any other authority ever came knocking and asked for your location, Google could provide it.
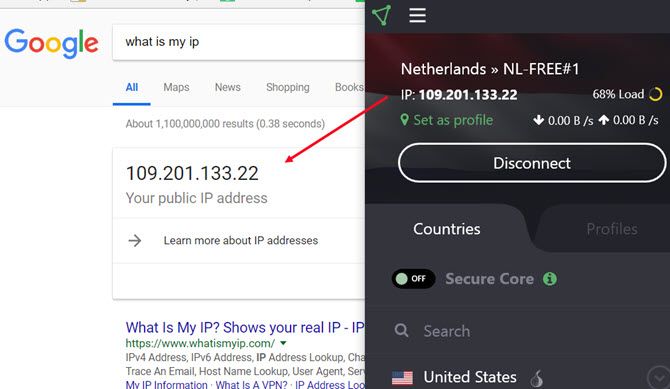
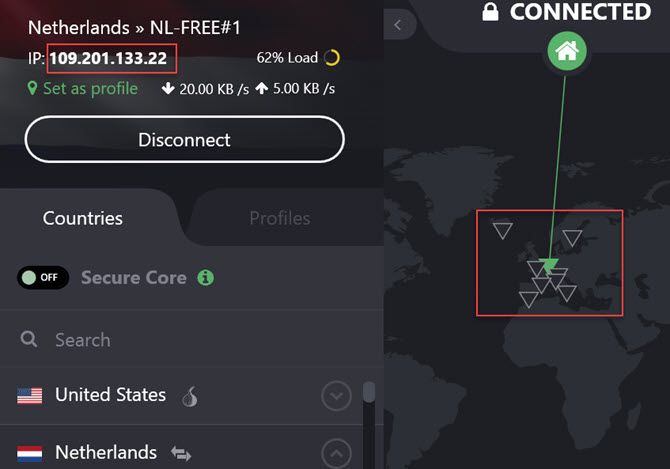
If that’s not enough privacy for you, you can add another layer of anonymity by encrypting your connection with a VPN service. We recommend avoiding free VPN services and instead pay for a reputable one like ExpressVPN or CyberGhost.
Once connected, you can then use Gmail through the encrypted VPN.
Now, when you go to your Gmail account and send an email, the originating IP will still show up as one of Google’s servers, but there will be two differences.
First, the Google server won’t likely be located anywhere near your actual location. Second, if Google is ever asked to provide your actual IP, they’ll only be able to provide the erroneous IP address hosted by the VPN service.
What Can You Learn From An Email Header (Metadata)? Did you ever get an e-mail and really wondered where it came from? Who sent it? How could they have known who you are? Surprisingly a lot of that information can be from from the… Read More
, it’ll show your VPN’s IP address located some place far away. It’s a quick and easy way to send anonymous emails with very little effort.
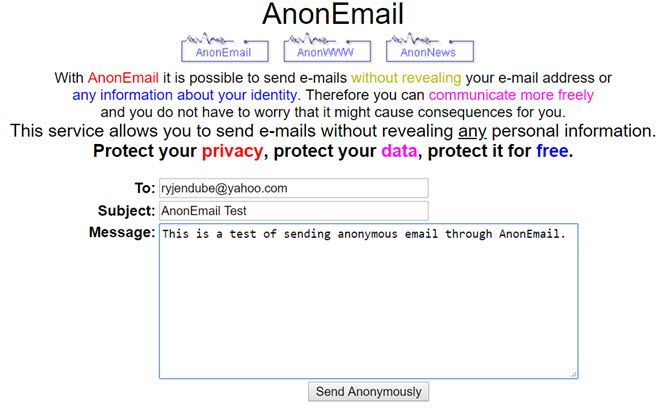
AnonEmail is a service by AnonyMouse. It allows you to send anonymous emails by resending your email several times through random nodes, thus making it impossible to trace back.
In AnonEmail, you can fill in your recipient, the subject, and a short plain-text message. Contrary to many other services AnonEmail does not (seem to) log your IP. However, we urge you not to use it for anything illegal!
As an extra security measure, AnonEmail will wait for an unknown period of time before sending your email along. Why? So no one will be able to prove your “guilt” based on time/location, or make geographic presumptions based on timezones.
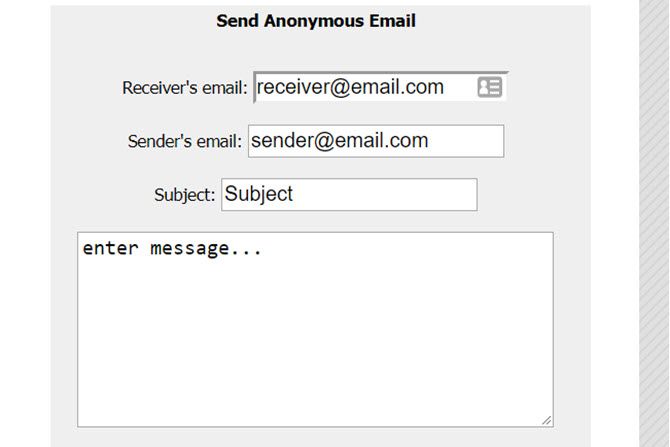
Like the name implies, this is another web-based, anonymous email tool. Although it lacks the complete anonymity of AnonEmail, it’s the simplest option to use.
7 Completely Free VPN Services to Protect Your Privacy If you’re looking for a free VPN, the choices are currently limited, with many services switching to a paid model. These free virtual private networks can be used to avoid region blocking and more. Read More
if you want to fully cover your tracks.
Also, neither Send Anonymous Mail nor AnonEmail allow the recipient to reply to your email, so these solutions are only best if you want to send a one-way anonymous email message.
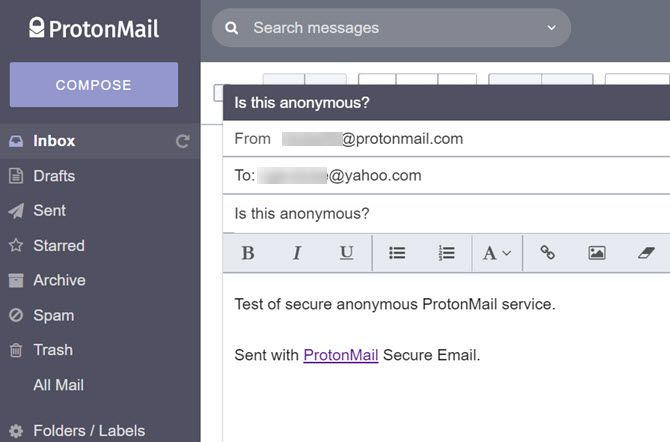
I’ve personally used ProtonMail when communicating with a journalist living in China. The journalist was using a VPN to access his ProtonMail account, providing several levels of security from prying government eyes. Not only was his originating IP address located outside of China, but all communications using ProtonMail are encrypted.
Some features of ProtonMail include:
End-to-End Encryption: Messages are not only encrypted when they’re sent from ProtonMail servers, but all stored messages are encrypted as well. Without access to the appropriate ProtonMail account, no one can access your messages.
Private User Data: ProtonMail’s encryption process, which uses an encryption key on your own client computer, mean even the system administrators at ProtonMail can’t access your messages. On the downside, this means they can’t recover your account for you. On the upside, it means they can’t provide messages to any governing authority either.
, you can be sure there are no “back doors” available for anyone to access your emails. That includes both system administrators or hackers.
If you have a need for regular two-way encrypted emails, you may want to consider signing up for a ProtonMail account and just using it as your regular email service.
Start Sending Anonymous Emails Your Way
As you can see, there are a lot of ways to send anonymous email. You can use a local solution with a VPN and either an email client or through a throwaway online email account. You could use a secure, encrypted email service like ProtonMail. Or you could just use one of the free websites that let you send one-way, fully-anonymous messages.
The choice really depends on why you’re sending the message and what level of security and anonymity you need.
The Best VPN Services We’ve compiled a list of what we consider to be the best Virtual Private Network (VPN) service providers, grouped by premium, free, and torrent-friendly. Read More
The Best Computer Security and Antivirus Tools Need a security solution for your PC? Concerned about malware, ransomware, viruses, and intruders through your firewalls? Want to back up vital data? Just confused about it all? Here’s everything you need to know. Read More
If you’ve done some beginner programming, or even started to look at different languages, you’ve probably come across the phrase “object-oriented programming” (or “OOP”).
There are all sorts of technical explanations as to what it is, but today we’re going to take a look at defining object-oriented programming in a simple way.
Before We Start: Procedural Languages
To understand what an object-oriented programming language is, you need to understand what it replaced. Early programming languages were procedural—so-called because the programmer would define a very specific set of procedures that the computer would undertake.
In the earliest days, procedures were written on punch cards. Those steps took in data, performed a sequence of actions on that data, then output new data.
Procedural languages worked well for a time (and some are still in use). But when you want to program something beyond a basic sequence of steps, procedural languages can become difficult to manage. That’s where object-oriented programming comes in.
The Object of Object-Oriented Programming
So then, what is object-oriented programming?
The first object-oriented language (generally agreed to be Simula) introduced the idea of objects. Objects are collections of information that are treated as a singular entity.
We’ll dive deeper into what that actually means in a second with an example, but first we have to talk about classes. Classes are sort of like pre-objects. They contain a list of attributes that, when defined, become an object.
Let’s take the example of programming a chess game. We might have a class called Piece. Within Piece, we have a list of attributes:
Color
Height
Shape
Movement allowed
An object simply defines one particular instance of a thing belonging to that class.
So we could have an object called WhiteQueen. That object would have definitions for all four attributes (white, tall, cylindrical with crenellations, any number of spaces in any direction). It might also have methods or functions.
What makes this so much better than the procedural approach?
In short, object-oriented programming languages (like Java) makes it easier to organize data and code in a way that’s more versatile for larger project.
To discuss it in a bit more detail, we’ll talk about the four basics of object-oriented programming.
Object-Oriented Programming: Abstraction
Just because you want to use something doesn’t mean you need to know how it works. An espresso machine, for example, is complex. But you don’t need to know how it works. You just need to know that when you hit “On,” you’re going to get espresso.
The same is true of objects in object-oriented programming. In our chess example, we may have a move() method. That method could require a lot of data and other methods. It might need the initial position and final position variables. It could use another method for determining whether it’s captured a piece.
But you don’t need to know that. All you need to know is that when you tell the piece to move, it moves. That’s abstraction.
Object-Oriented Programming: Encapsulation
Encapsulation is one of the ways that object-oriented programming creates abstraction. Each object is a collection of data that’s treated as a single entity. And within those objects are data—both variables and methods.
The variables within an object are generally kept private, which means other objects and methods can’t access them. Objects can only be affected by using their methods.
A Bishop object might contain several pieces of information. For example, it could have a variable called “position.” That variable is necessary to use the move() method. And, of course, it has a color.
By making the position variable private and the move() method public, a programmer protects the move variable from being affected by anything else. And if the color is a private variable, there’s no way for another object to change it unless there’s a method that allows the change. (Which you probably wouldn’t have, as the color of the piece should remain constant.)
These variables and methods are kept within the Bishop object. Because they’re encapsulated, a programmer could make a change to the structure or contents of the object without worrying about the public interface.
Object-Oriented Programming: Inheritance
In addition to classes, object-oriented programming languages also have sub-classes. These contain all of the attributes from the parent class, but they can also contain other attributes.
In our chess game, the pawn pieces need a method that can turn them into other pieces if they make it to the end of the board. We’ll call it the transformPiece() method.
Not every piece needs the transformPiece() method. So we wouldn’t want to put it in the Piece class. Instead, we can create a sub-class called Pawn. Because it’s a sub-class, it inherits all of the attributes from Piece. So an instance of the sub-class Pawn includes a color, height, shape, and movement allowed.
But it also includes the transformPiece() method. Now we never have to worry about accidentally using that function on a rook. Here’s a technical explanation:
Polymorphism is a result of inheritance. Fully understanding polymorphism takes some programming knowledge, so we’re just going to stick with the basics here. In short, polymorphism allows programmers to use methods of the same name, but with different objects.
For example, our Piece class might have a move() method that moves a piece one space in any direction. That works for the king piece, but not for anything else. To fix this problem, we can define new move() method in the Rook sub-class that defines movement as an unlimited number of spaces forward, backward, left, or right.
Now, when a programmer invokes the move() method and uses a piece as the argument, the program will know exactly how the piece should move. This saves a ton of time over trying to figure out which of many different methods you should use.
Object-Oriented Programming in a Nutshell
If your head is spinning a bit after those last four definitions, don’t worry too much. Here are the main things you need to remember:
Object-oriented programming collects information into single entities called objects.
Each object is a single instance of a class.
Abstraction hides the inner workings of an object when it’s not necessary to see them.
Encapsulation stores related variables and methods within objects and protects them.
Inheritance allows sub-classes to use attributes from parent classes.
Polymorphism allows objects and methods to deal with multiple different situations with a single interface.
If you can remember those points, you’ll have a good handle on what object-oriented programming is. The four basics of object-oriented programming, as I mentioned, can be a little difficult to get a handle on. But once you start programming, they’ll become more clear.
Looking for the Best Programming Languages? Start Here! Whether you’re completely new to programming languages or looking to jump into a new kind of programming, one of the most important questions to ask is: “Which programming language is right for me?” Read More
, you’ll start to learn how it puts OOP principles into practice.
Troubleshooting crashes is never a fun task, especially if MySQL does not report the cause of the crash. For example, when MySQL runs out of memory. Peter Zaitsev wrote a blog post in 2012: Troubleshooting MySQL Memory Usage with a lots of useful tips. With the new versions of MySQL (5.7+) and performance_schema we have the ability to troubleshoot MySQL memory allocation much more easily.
In this blog post I will show you how to use it.
First of all, there are 3 major cases when MySQL will crash due to running out of memory:
MySQL tries to allocate more memory than available because we specifically told it to do so. For example: you did not set innodb_buffer_pool_size correctly. This is very easy to fix
There is some other process(es) on the server that allocates RAM. It can be the application (java, python, php), web server or even the backup (i.e. mysqldump). When the source of the problem is identified, it is straightforward to fix.
Memory leaks in MySQL. This is a worst case scenario, and we need to troubleshoot.
Where to start troubleshooting MySQL memory leaks
Here is what we can start with (assuming it is a Linux server):
Part 1: Linux OS and config check
Identify the crash by checking mysql error log and Linux log file (i.e. /var/log/messages or /var/log/syslog). You may see an entry saying that OOM Killer killed MySQL. Whenever MySQL has been killed by OOM “dmesg” also shows details about the circumstances surrounding it.
Check the available RAM:
free -g
cat /proc/meminfo
Check what applications are using RAM: “top” or “htop” (see the resident vs virtual memory)
Check mysql configuration: check /etc/my.cnf or in general /etc/my* (including /etc/mysql/* and other files). MySQL may be running with the different my.cnf (run
ps ax| grep mysql
)
Run
vmstat 5 5
to see if the system is reading/writing via virtual memory and if it is swapping
For non-production environments we can use other tools (like Valgrind, gdb, etc) to examine MySQL usage
Part 2: Checks inside MySQL
Now we can check things inside MySQL to look for potential MySQL memory leaks.
MySQL allocates memory in tons of places. Especially:
Table cache
Performance_schema (run:
show engine performance_schema status
and look at the last line). That may be the cause for the systems with small amount of RAM, i.e. 1G or less
InnoDB (run
show engine innodb status
and check the buffer pool section, memory allocated for buffer_pool and related caches)
Temporary tables in RAM (find all in-memory tables by running:
select * from information_schema.tables where engine='MEMORY'
)
Prepared statements, when it is not deallocated (check the number of prepared commands via deallocate command by running show global status like ‘
Com_prepare_sql';show global status like 'Com_dealloc_sql'
)
The good news is: starting with MySQL 5.7 we have memory allocation in performance_schema. Here is how we can use it
First, we need to enable collecting memory metrics. Run:
UPDATE setup_instruments SET ENABLED = 'YES'
WHERE NAME LIKE 'memory/%';
Run the report from sys schema:
select event_name, current_alloc, high_alloc
from sys.memory_global_by_current_bytes
where current_count > 0;
Usually this will give you the place in code when memory is allocated. It is usually self-explanatory. In some cases we can search for bugs or we might need to check the MySQL source code.
The largest chunk of RAM is usually the buffer pool but ~3G in stored procedures seems to be too high.
According to the MySQL source code documentation, sp_head represents one instance of a stored program which might be of any type (stored procedure, function, trigger, event). In the above case we have a potential memory leak.
In addition we can get a total report for each higher level event if we want to see from the birds eye what is eating memory:
mysql> select substring_index(
-> substring_index(event_name, '/', 2),
-> '/',
-> -1
-> ) as event_type,
-> round(sum(CURRENT_NUMBER_OF_BYTES_USED)/1024/1024, 2) as MB_CURRENTLY_USED
-> from performance_schema.memory_summary_global_by_event_name
-> group by event_type
-> having MB_CURRENTLY_USED>0;
+--------------------+-------------------+
| event_type | MB_CURRENTLY_USED |
+--------------------+-------------------+
| innodb | 0.61 |
| memory | 0.21 |
| performance_schema | 106.26 |
| sql | 0.79 |
+--------------------+-------------------+
4 rows in set (0.00 sec)
I hope those simple steps can help troubleshoot MySQL crashes due to running out of memory.
Troubleshooting crashes is never a fun task, especially if MySQL does not report the cause of the crash. For example, when MySQL runs out of memory. Peter Zaitsev wrote a blog post in 2012: Troubleshooting MySQL Memory Usage with a lots of useful tips. With the new versions of MySQL (5.7+) and performance_schema we have the ability to troubleshoot MySQL memory allocation much more easily.
In this blog post I will show you how to use it.
First of all, there are 3 major cases when MySQL will crash due to running out of memory:
MySQL tries to allocate more memory than available because we specifically told it to do so. For example: you did not set innodb_buffer_pool_size correctly. This is very easy to fix
There is some other process(es) on the server that allocates RAM. It can be the application (java, python, php), web server or even the backup (i.e. mysqldump). When the source of the problem is identified, it is straightforward to fix.
Memory leaks in MySQL. This is a worst case scenario, and we need to troubleshoot.
Where to start troubleshooting MySQL memory leaks
Here is what we can start with (assuming it is a Linux server):
Part 1: Linux OS and config check
Identify the crash by checking mysql error log and Linux log file (i.e. /var/log/messages or /var/log/syslog). You may see an entry saying that OOM Killer killed MySQL. Whenever MySQL has been killed by OOM “dmesg” also shows details about the circumstances surrounding it.
Check the available RAM:
free–g
cat/proc/meminfo
Check what applications are using RAM: “top” or “htop” (see the resident vs virtual memory)
Check mysql configuration: check /etc/my.cnf or in general /etc/my* (including /etc/mysql/* and other files). MySQL may be running with the different my.cnf (run psax|grepmysql )
Run vmstat55 to see if the system is reading/writing via virtual memory and if it is swapping
For non-production environments we can use other tools (like Valgrind, gdb, etc) to examine MySQL usage
Part 2: Checks inside MySQL
Now we can check things inside MySQL to look for potential MySQL memory leaks.
MySQL allocates memory in tons of places. Especially:
Table cache
Performance_schema (run: show engine performance_schema status and look at the last line). That may be the cause for the systems with small amount of RAM, i.e. 1G or less
InnoDB (run show engine innodb status and check the buffer pool section, memory allocated for buffer_pool and related caches)
Temporary tables in RAM (find all in-memory tables by running: select*from information_schema.tableswhere engine=‘MEMORY’ )
Prepared statements, when it is not deallocated (check the number of prepared commands via deallocate command by running show global status like ‘ Com_prepare_sql‘;show global status like ‘Com_dealloc_sql’ )
The good news is: starting with MySQL 5.7 we have memory allocation in performance_schema. Here is how we can use it
First, we need to enable collecting memory metrics. Run:
UPDATEsetup_instrumentsSETENABLED=‘YES’
WHERENAMELIKE‘memory/%’;
Run the report from sys schema:
selectevent_name,current_alloc,high_alloc
fromsys.memory_global_by_current_bytes
wherecurrent_count>0;
Usually this will give you the place in code when memory is allocated. It is usually self-explanatory. In some cases we can search for bugs or we might need to check the MySQL source code.
The largest chunk of RAM is usually the buffer pool but ~3G in stored procedures seems to be too high.
According to the MySQL source code documentation, sp_head represents one instance of a stored program which might be of any type (stored procedure, function, trigger, event). In the above case we have a potential memory leak.
In addition we can get a total report for each higher level event if we want to see from the birds eye what is eating memory:
Alexander joined Percona in 2013. Alexander worked with MySQL since 2000 as DBA and Application Developer. Before joining Percona he was doing MySQL consulting as a principal consultant for over 7 years (started with MySQL AB in 2006, then Sun Microsystems and then Oracle). He helped many customers design large, scalable and highly available MySQL systems and optimize MySQL performance. Alexander also helped customers design Big Data stores with Apache Hadoop and related technologies.
A data privacy bill in California is just a signature away from becoming law over the strenuous objections of many tech companies that rely on surreptitious data collection for their livelihood. The California Consumer Privacy Act of 2018 has passed through the state legislative organs and will now head to the desk of Governor Jerry Brown to be enacted.
Update: The Governor has signed it and the bill will take effect at the end of next year:
The law puts in place a variety of powerful protections against consumers having their data collected and sold without their knowledge. You can read the full bill here, but the basic improvements are as follows:
Businesses must disclose what information it collects, what business purpose it does so for and any third parties it shares that data with.
Businesses would be required to comply with official consumer requests to delete that data.
Consumers can opt out of their data being sold, and businesses can’t retaliate by changing the price or level of service.
Businesses can, however, offer “financial incentives” for being allowed to collect data.
California authorities are empowered to fine companies for violations.
As you can imagine, that puts something of a damper on the businesses of Facebook and Google in particular, and indeed those companies have aligned with others in opposition to the law, either individually or via trade organizations.
Naturally, internet providers like AT&T and Verizon, which have for years made money from sharing the data of their customers with third parties, are also opposed.
It’s the kind of law one feels one could almost get behind without reading it, since it makes all the right people angry.
The bill heading to the governor’s desk is actually a slightly hasty alternative to one proposed by moneyed activist Alastair Mactaggart, who organized a ballot initiative to put it up for a vote in November. But he promised to withdraw the measure if legislators put together their own version by today — which they have done.
Mactaggart’s proposal would have been even more restrictive, so lawmakers were put in a bind. The vote isn’t a sure thing. But if they waited and the measure passed, they would look weak and be forced into creating a law not of their own devising. But if they did something now, they could exert more control and look responsive ahead of the midterms.
It may only be a state law, but California is of course a highly influential and populous state, not to mention the one where a great deal of tech companies are based. So the effect of this law will have more than merely a local effect. After the Broadband Privacy Rule got nixed consumers found themselves in a bind, and now net neutrality has been negated as well — but states are picking up where the feds let it drop and may prove to be a powerful deterrent to the types of behaviors enabled in this regulatory vacuum. That is, if their own legislators don’t sabotage themselves.
If the law passes the governor’s desk, the law still won’t take effect until January 1, 2020, giving companies time enough to both fight it and prepare for it.
The much-anticipated Sets feature has been pulled from the newest Windows 10 Redstone 5 build and there’s no word when it will return. As groovyPost reports, "The Sets feature is a tabbed-windows experience that lets you group together different apps on your desktop." It’s like having different tabs open in your browser, but for apps and File Explorer. From the report: Details on why it was removed and when it will come back have been vague. Microsoft made the announcement about Sets in [yesterday’s] blog post about preview build 17704: "Thank you for your continued support of testing Sets. We continue to receive valuable feedback from you as we develop this feature helping to ensure we deliver the best possible experience once it’s ready for release. Starting with this build, we’re taking Sets offline to continue making it great. Based on your feedback, some of the things we’re focusing on include improvements to the visual design and continuing to better integrate Office and Microsoft Edge into Sets to enhance workflow. If you have been testing Sets, you will no longer see it as of today’s build, however, Sets will return in a future WIP flight. Thanks again for your feedback."


 In this post we will review the most important Linux settings to adjust for performance tuning and optimization of a MySQL database server. We’ll note how some of the Linux parameter settings used OS tuning may vary according to different system types: physical, virtual or cloud. Other posts have addressed MySQL parameters, like Alexander’s blog
In this post we will review the most important Linux settings to adjust for performance tuning and optimization of a MySQL database server. We’ll note how some of the Linux parameter settings used OS tuning may vary according to different system types: physical, virtual or cloud. Other posts have addressed MySQL parameters, like Alexander’s blog 




 Troubleshooting crashes is never a fun task, especially if MySQL does not report the cause of the crash. For example, when MySQL runs out of memory. Peter Zaitsev wrote a blog post in 2012:
Troubleshooting crashes is never a fun task, especially if MySQL does not report the cause of the crash. For example, when MySQL runs out of memory. Peter Zaitsev wrote a blog post in 2012: