Laravel Mail Export is a simple mailable trait and interface to export emails to a storage disk once sent. This package works by exporting any mail sent as a .eml file to a filesystem disk, which is useful for archival purposes.
Here’s an example from the readme of how to use this package, which includes implementing the ShouldExport interface and use the Exportable trait:
There comes a time in every Christian’s life when he must make an important decision: What kind of firearm should I buy? Well, here’s a guide to help you know which gun is right for you.
Glock: What if you miss on the first shot? What if you miss on the second shot? What if you miss on the next ten shots? Fortunately, you can fit like 1,000 bullets in a Glock. And it’s made of plastic; make sure to recycle it after you’re done. We don’t want a landfill full of Glocks.
Perfect for: People too lazy to reload
Walther PPK: Look at this little gun. And it has such a cute little name. What an adorable thing to put in your purse.
Perfect for: British secret agent or a small American child
Civil War Cannon: Why waste all that time shooting a bunch of little tiny bullets when you can shoot one big bullet the size of a coconut? This is a great option for the gentleman connoisseur of fine-aged weaponry.
Perfect for: Those with mutton-chop facial hair and a love for exploding things
.44 Magnum: Do you feel lucky? Well, do ya, punk? More importantly, do you feel like shooting through a car windshield? The .44 magnum is the most powerful handgun in the world… or it was like back in the ’70s. There are a lot more large, unwieldy guns to pick from now, but this is a classic.
Perfect for: Cops who get the job done even if they don’t follow all the rules
Shotgun: Are you not very good at aiming? Maybe you have bad eyesight. You can’t really see what you want to shoot, but you know you want it dead. Then a shotgun is right for you. It’s great at close range (though the CDC doesn’t recommend shooting people at close range during a pandemic).
Perfect for: Farmers who need to force people to marry their daughters
Plasma Rifle: If aliens invade, you need a plasma rifle, since, as everyone knows, shooting aliens is way cooler with a plasma rifle. You can also use them to light cigars and heat casseroles at potlucks. Very useful.
Perfect for: Space Marines, Ellen Ripley, and people who smoke cigars
1911: An old, old design (the name refers to how it was first made 500 years ago in 1911). This gun is for people who are stuck in the past and don’t care for newfangled things like TikToks and Twitters. No, you shoot those things — you shoot them with your 1911.
Perfect for: Old men who long for the good old days when men were men and there weren’t any of these other fake genders.
Desert Eagle: It’s big. It’s shiny. It’s not really practical for anything. But it’s big. And shiny.
Perfect for: People compensating for something
AR-15: The AR stands for “Assault Rifle” and the 15 stands for how many people you can assault with it at once. Deadlier than the AR-14 (but not quite as deadly as the AR-16), the AR-15 is a fun gun everyone enjoys. I have six because I’m always misplacing them.
Why would anyone spend money to reduce the recoil of an AR-15 rifle? That’s the question some will ask given the fact that a .223/5.56 round doesn’t produce a whole lotta recoil. Fair enough. For most shooters, it won’t make enough of a difference to matter. But if you’re a competitive shooter or are just sensitive to recoil, a recoil-reducing buffer makes sense.
The Miculek Magnetic Buffer System isn’t the first recoil reducer. Buffers using springs or hydraulics have been around for years. But the Miculek is a unique design using magnetic polarity to dampen the recoil impulse.
That means there are no moving parts to make noise or fail. With no springs or hydraulic seals, the Miculek Magnetic Buffer System (MMBS from now on) is damn near foolproof.
Dan Z. for TTAG
When you’re not using it in your rifle, the MMBS can double as a handy fridge magnet. But seriously folks . . .
Dan Z. for TTAG
Here you see the MMBS next to a standard M4 buffer. There are a couple of difference besides the recoil-reducing piston action. First, the MMBS weighs a tad more…3.2 oz versus 2.9 oz according to my kitchen scale. Also, the MMBS doesn’t rattle when you shake it like the standard buffer does.
I talked to the folks at JDAS enterprises who produce the MMBS with Jerry Miculek. They make the comps for Jerry, too, and tell me more Miculek designs are coming in the future.
JDAS said they’ve tested the buffer under more that 100,000 rounds without failure. They hooked it up to an accelerometer to objectively measure recoil and tested it for barrel deflection to see what it does for muzzle rise.
They told me that the MMBS is a significant improvement over a standard buffer and measurably better than either sprung or hydraulic designs.
Dan Z. for TTAG
Since I don’t have access to any of that equipment, the only way to tell if the MMBS does what they say it does is to shoot it.
Installing it takes all of 30 seconds. Just depress the buffer retention pin in your rifle’s lower — be sure to have your thumb over the sprung buffer or it will launch — and remove your standard buffer and spring. Slide the old buffer out of the recoil spring and install the MMBS. Reinstall it in your lower and you’re ready to go.
Dan Z. for TTAG
The strength of the dampening action of the MMBS is selectable with a screw that adjusts how much force is needed to depress the magnetic piston. The farther in your adjust the screw, the more force it takes to compress it. That lets you can tune your rifle as needed.
JDAS recommends tuning with a single round in a magazine. Shoot your rifle and if the action doesn’t lock back on the empty magazine, adjust the buffer with a counter-clockwise half-turn of the adjustment screw to lighten the tension. I didn’t have to do that as my rifle cycled just fine with the MMBS right out of the box.
First I shot two rifles side by side, one with a standard buffer and one with the MMBS. The rifle with the MMBS was slightly softer-shooting than the standard buffer. But while I was shooting the same ammo from each gun, the two rifles weren’t the same (different accessories, different weights, different muzzle devices. It wasn’t really a fair comparison.
Next I shot both with the same rifle, alternating between the two buffers. That’s a little tricky because you have to take the rifle down to replace the buffers between magazines. Still, there is a perceptible reduction in felt recoil when using the MMBS. It’s not a lot and it probably won’t make much of a difference to some shooters. But it’s there.
The MMBS has an MSRP of $119 and sells for $99 retail exclusively through Big Daddy Unlimited. That makes it less expensive than hydraulic buffers. Will it be worth it for you? That depends on how you shoot and how recoil sensitive you are. But if you want to do everything you can to reduce as much of the felt recoil your AR-15 rifle produces, the MMBS is well worth a try.
Used by designers the world over, CAD, or computer-aided design and drafting (CADD), is design and documentation technology that replaces manual drafting (like blueprints, for example) with an automated process.
From architects and engineers through to audiovisual professionals and fashion houses, experts the world over use 2D and 3D CAD programs to draw up visual concepts, create construction documentation, and simulate designs in the real world through realistic renderings of a particular subject matter.
If you’re already a designer, or want to start getting into 2D and 3D design, there is a huge range of software out there that can be used for this purpose. In this article, we’ll explore eightfree Mac applications, so you can get stuck into it sooner, and investigate which one rules the roost.
Most of these apps are free, but we are going to start with a paid, but reasonably priced option.
1. Leopoly
Promising to create new opportunities in 3D printing through fully customizable digital landscapes and 3D modeling, Leopoly is built for both newbies and more advanced users.
Its baseline ShapeLab tool enables users to become creators in minutes, building bespoke models and bringing your vision to life through digital sculpting, painting, and mesh-based technology. Going further, LeoTrainer enables full exploration of intricate processes and models—hence the name—where the training is oriented towards corporate and education worlds to familiarize users with concepts in virtual reality.
Finally, LeoShape is best suited to healthcare, fashion, and heavy-duty industries, promising enhanced modeling capabilities for those training or working in design; a great option for professionals.
In terms of a great beginner’s 2D program, LibreCAD‘s software can help you to create complex drawings, 2D drafts, or projects for laser cutting or engraving purposes. The tool comes with features like a snap-in tool, dimensioning and measurements, and annotations—a bit like a graphics editor such as Microsoft Paint, but with more intricacies.
It’s open-source and available for Mac, Windows, and Linux, and with no subscriptions, licensing costs, or annual fees, it could be the program for you.
LeoCAD is probably the best CAD software for educational purposes, as it allows users to create virtual designs, shapes, and models using LEGOs, which is ideal for kids who want to get a head start with 3D modeling. With a combination of basic and advanced tools, its open-source nature means that anyone and everyone can contribute, and even add new features.
Blender has emerged as one of the best, most versatile CAD programs in the world in recent years. While it is very complex in nature, the possibilities are virtually endless with Blender. Open-source and completely free, its creation suite "supports the entirety of the 3D pipeline—modeling, rigging, animation, simulation, rendering, compositing and motion tracking, video editing, and 2D animation pipeline." Quite frankly, it’s a jack-of-all-trades for everything and everything 2D or 3D.
Users have been enthusiastic about the wide range of possibilities with Blender, and if you’re looking for a more advanced program to help you develop your CAD skills, this might be the one!
With an interface that is clearly borrowing from AutoCAD—the "industry-standard" for CAD design software—DesignSpark contains the usual features and is an excellent free alternative to AutoCAD. Users of programs like this would normally be attempting large-scale or intricate builds, like homes for example.
While core features are free, functions like bulk importing and exporting, and advanced rendering, need to be purchased, so that is a limitation. Interestingly, DesignSpark allows you to have designs printed in-house, and sent to you wherever you are.
Breaking from the other applications above, Houdini is procedural software that is designed around a node-based workflow. Similar to parametric modeling—which is what Blender uses, this allows you to alter models and objects by changing individual parameters or nodes. Similarly again to Blender, it includes intricate particle effects, which would allow users to create anything from an Alaskan winter terrain to a mock up of interstellar space. For this reason, it is also a popular tool for animation and game development.
Although a free version of Houdini (Apprentice) is available with all the same features as the freemium product, it has some limitations, such as a render size of just 1280×720 pixels, and every rendered image will feature a small Houdini logo.
Download:Houdini (Free, premium version available)
7. FreeCAD
While FreeCAD appears unassuming in name, it is a robust piece of software made to design real-life objects in 3D. Again utilizing parametric modeling, you can easily modify 3D designs and tailor them to a variety of settings or environments. It is modular in nature, allowing plugins to be attached to the application, and also offers handy features oriented towards robotics and mechanical machining like CNC.
It’s open-source and extremely powerful, so pace yourself in terms of becoming familiar with the program. Digging deeper will unleash a universe’s worth of potential for CAD enthusiasts.
CAD software can help you design, create, and produce 2D and 3D objects, worlds, and more
This article has given you a small selection of free but powerful CAD applications, ranging from beginner ability to advanced users or professionals. For those looking to get into design, or build on their professional design skills, these apps could be perfect for you.
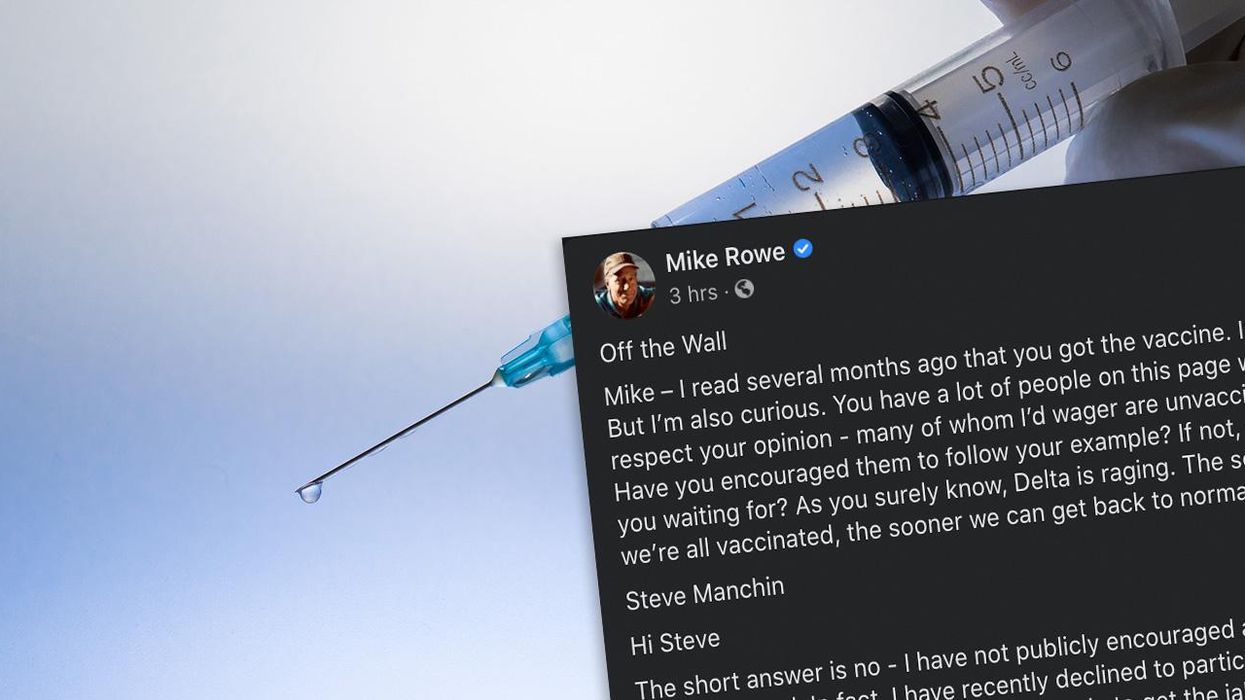
The Holy Vaccinated Saints are some of the most insufferable nimrods out there. I know we make fun of "Karens" but we need to expand and come up with some kind of denigrating moniker for the lot of them. One such pro-vaccine nimrod wrote into Mike Rowe, encouraging Mike to use the power of his influence to spread the Gospel according to Fauci. My words, "Steve" isn’t near clever enough to think up something half-way original. Not his fault, he was born a sheep. Anyway, Mike Rowe didn’t take the guilt bait, and instead of saying "no thanks, to each their own" he wrote a brilliant, spicy essay that every politico and their minions pushing the pokey should read and absorb. They won’t, but a girl can dream.
You’d need to click the "See More" link to read the full post, and you absolutely should, it’s Mike Rowe at his best. But a few of you might be on a social media hiatus or you, blessedly, told Facebook to go pound sand. I approve. If that be the case, here is my favorite chunk from Mike’s post:
"The fact is, millions of reasonable Americans have every right to feel confused and skeptical. Those people you refer to, Steve – the ones now telling us that we can "get back to normal just as soon as everyone is vaccinated" – those are the same people who said, "two weeks to flatten the curve!" Those are the same people who told us that masks were "useless" before they told us they were "critical." Those are the same people who told us that a return to normalcy would occur just as soon as "the most vulnerable" among us were vaccinated. Then, just as soon as "half the population" was vaccinated. Then, just as soon as we achieved "herd immunity." Those are the same people who told us they wouldn’t trust ANY vaccine developed under the last administration. Now, those very same people are belittling the skeptics!
If this were a Peanuts cartoon, those people would be Lucy, pulling away the football at the last moment while a nation full of Charlie Browns land flat on their collective back, over and over and over again. Those people you refer to – elected officials, journalists, and most disturbingly, more than a few medical experts – have moved the goalposts time and time again, while ignoring the same rules and restrictions they demand we all live by. They’re always certain, usually wrong, incapable of shame, and utterly void of humility. Is it any wonder millions find them unpersuasive?"
Mike is, as usual, right about this. A lot of us are skeptical. Speaking for myself, I cannot nor will I trust anyone in government to make my decisions. I make my decisions, and I make my own decisions better than an elected official and better than a butt-kissing sycophant who elected those assholes. I pride myself on critical thinking skills that I saw few people exercising at the start of the pandemic way back in February of 2020. What I did see was herd mentality in full swing. Plenty of right-leaning leaders went right along with it, too.
It’s good to be skeptical. It’s good to hit pause. Sometimes going with the herd is the right move. Sometimes it’s not. But that’s where thinking comes into play rather than just feeling and reacting to those feelings. Or in the case of much of the COVID panic, reacting to what others are feeling and saying so forcefully.
It’s your body and your choice. Remember that line? If you decide the vaccine is right for you, no one is stopping you. But some people have decided it’s not right for them. It isn’t up to you or anyone else to force them to do something they do not want to do to their body. Hard stop.
I have to add this last part, because it resonated with me:
At this point, I’m afraid the the government has but one course of sensible action – get the FDA on board, stat, and then, provide an honest, daily breakdown of just how quickly the virus is spreading among the unvaccinated, versus the vaccinated. No more threats, no more judgments, no more politics, no more celebrity-driven PSA’s, no more ham-fisted attempts at public shaming. Just a steady flow of verifiable data that definitively proves that the vast, undeniable, overwhelming majority of people who get this disease are unvaccinated. In other words, give us the facts, admit your mistakes, try on a bit of humility, and stop treating the unvaccinated like the enemy.
This is the gold: "no more ham-fisted attempts at public shaming" and "stop treating the unvaccinated like the enemy."
I’m tired of the vaccinated treating the unvaccinated like second class citizens. Or third class. Vermin, maybe. It’s gone on long enough and it’s gross. Hopefully those of us in the conservative crowd have been consistent in saying you need to do what you need to do, and so long as others are not negatively affected, fine. But man, the vaccinated people are teetering on the edge of becoming just as if not more obnoxious than the BAKE ME A CAKE, BIGOT Gaystapo soldiers.
Thanks for the wisdom, Mike. Hopefully it’ll resonate with the obnoxious vaccinated populace.