Neil Postman’s Amusing Ourselves to Death was a 1985 wake-up call we didn’t know we’d need forty years later. Postman (1931-2003), a media theorist and cultural critic, argued that television was not just changing what we watch, but how we think and communicate as a society. While Postman’s focus was on television, his insights have become even more relevant in our current digital age. In an era dominated by social media, smartphones, and an ever-expanding array of digital entertainment options, Postman’s warnings about the impact of media on critical thinking and public discourse have only grown more urgent.
Here are four excerpts that are about television but easily apply to social media today:
Instagram:
“Americans no longer talk to each other, they entertain each other. They do not exchange ideas, they exchange images. They do not argue with propositions; they argue with good looks, celebrities and commercials.”
Twitter:
“We are presented not only with fragmented news but news without context, without consequences, without value, and therefore without essential seriousness; that is to say, news as pure entertainment.”
TikTok:
“Now … this” is commonly used on radio and television newscasts to indicate that what one has just heard or seen has no relevance to what one is about to hear or see, or possibly to anything one is ever likely to hear or see. The phrase is a means of acknowledging the fact that the world as mapped by the speeded-up electronic media has no order or meaning and is not to be taken seriously. There is no murder so brutal, no earthquake so devastating, no political blunder so costly—for that matter, no ball score so tantalizing or weather report so threatening—that it cannot be erased from our minds by a newscaster saying, “Now … this.” The newscaster means that you have thought long enough on the previous matter (approximately forty-five seconds), that you must not be morbidly preoccupied with it (let us say, for ninety seconds), and that you must now give your attention to another fragment of news or a commercial.
YouTube:
Entertainment is the supra-ideology of all discourse on television. No matter what is depicted or from what point of view, the overarching presumption is that it is there for our amusement and pleasure. That is why even on news shows which provide us daily with fragments of tragedy and barbarism, we are urged by the newscasters to “join them tomorrow.” What for? One would think that several minutes of murder and mayhem would suffice as material for a month of sleepless nights.
Many people try to claim that the Founding Fathers couldn’t have conceived of repeating rifles when they drafted the Second Amendment to the Bill of Rights. However, the story of Joseph Belton and his correspondence with the Continental Congress proves otherwise.
If you’d prefer to watch and learn, the video I made here details the entire event. If you’d prefer to read about it, the story unfolds below.
Belton, an inventor and gunsmith from Philadelphia, claimed to have devised a new flintlock musket capable of firing as many as sixteen consecutive shots in as little as twenty seconds. After the gun had fired its consecutive loads, it could then be reloaded individually like all other traditional firearms of that era. He first wrote to Congress about his new invention on April 11, 1777, letting them know he could demonstrate it to them at any time.
Intrigued by Belton’s claim, Congress ordered 100 examples of his “new improved gun.” They authorized him to oversee the construction of new guns, or alteration of existing guns, so that they were capable of discharging eight rounds with one loading and that he “receive a reasonable compensation for his trouble, and be allowed all just and necessary expences [sic].”
On May 7, Belton replied to Congress with his terms regarding what he felt to be “reasonable compensation.” In order to determine his fee, Belton wanted to arm 100 soldiers with his invention and demonstrate the capabilities of such armed men to a panel of four military officers — two of Congress’ choosing and two of Belton’s choosing. The officers then determined how many men they felt Belton’s 100 men were equivalent to when carrying a standard firearm. (For example, 100 specially armed men were equivalent to 200 regularly armed men, or more.)
For his ability to double the manpower, Belton felt that he was entitled to £1,000 for every 100 men he armed from a given state. Belton justified his price by claiming that a state could not raise, equip, and clothe 100 men for £1,000, making his 100 men armed as though they were 200 men a bargain. (For reference, £1,000 in 1777 is the equivalent of £150,000 today. If all 13 states outfitted 100 men, Belton would receive £13,000 — or £1,900,000 today.)
Belton argued that arming 3,000 men or more with his invention created enumerable advantages beyond description on the battlefield, making his compensation “vastly reasonable.” As such, his terms were non-negotiable. If Congress refused or attempted to haggle in any way, he would withdraw his offer completely. (For those doing the math, 3,000 men armed with Belton’s repeater would mean that he’d collect more than £4,500,000 in today’s currency.)
Belton must have realized immediately that his demands were more than outlandish because the next day, on May 8, he wrote a letter to John Hancock lowering his fee to £500 for doubling, £1,500 for tripling, £2,000 for quadrupling, and so forth.
On May 15, Congress read Belton’s letter to the body. They quickly dismissed it because of his “extraordinary allowance.” (No one saw that coming, right?) Congress considered the matter dropped and didn’t reply to Belton, likely assuming he would take their lack of reply as a refusal.
They assumed wrong.
Having heard nothing from Congress for over a month, Belton wrote them again on Saturday, June 14. This time, he claimed he could accurately hit targets with his rifle out to 100 yards and possibly even out to 200 yards. He offered to demonstrate this feat to Congress on the following Monday at 10:00 am in the State House Yard.
The same day Belton wrote this letter, Congress was involved with something that would prove far more important. On June 14, 1777, the Continental Congress approved the design for a national flag.
With Congress engaged in more pressing matters, Belton’s letter went unanswered for almost a month when he decided to write again.
His letter from July 10 was not nearly as polite as his previous ones. This time, he tried to rile members of the body by claiming that Great Britain regularly pays £500 for lesser services. If, he mused, the “little Island” could afford such payments, surely this “extensive continent” could do the same.
He also enclosed a letter signed by General Horatio Gates, Major General Benedict Arnold (before he became a turncoat), well-known scientist David Rittenhouse, and others, all claiming that his invention would be of “great Service, in the Defense of lives, Redoubts, Ships & … even in the Field,” and that they felt Belton was entitled to “a handsome [sic] reward from the Publick [sic].”
Having received the letter immediately, Congress resolved that same day to refer Belton’s petition to the Board of War, made up of five delegates. Among these five delegates were the future second president of the United States, John Adams, and Benjamin Harrison V, father and great-grandfather of the ninth and 23rd presidents of the United States, respectively.
Nine days later, on July 19, Congress got word from the Board of War. Much to Belton’s dismay, they dismissed his petition altogether. At this point, he must have finally gotten the hint that Congress wouldn’t authorize such exorbitant payment for his services. The historic record turns up no more correspondence between Belton and Congress.
Despite the fact that Joseph Belton failed to convince the Continental Congress to outfit colonial soldiers with his repeating rifle, it’s still a very important story. Belton invented his gun in 1777. The Bill of Rights wasn’t ratified until 1791. That means our Founding Fathers not only knew about repeating rifles 14 years before the creation of the Second Amendment, but that they thought highly enough of the idea to pursue further development and implementation of such technology. The fact that it proved to be cost-prohibitive is moot, as it certainly could have been done if Congress and Belton had agreed upon the definition of “reasonable compensation.”
So, the next time someone tells you the Second Amendment was never designed to protect the right to own a repeating rifle or that it was only meant to apply to flintlock firearms, sit them down and tell them the story of Joseph Belton and his repeating flintlock musket.
In the AI world, there’s a buzz in the air about a new AI language model released Tuesday by Meta: Llama 3.1 405B. The reason? It’s potentially the first time anyone can download a GPT-4-class large language model (LLM) for free and run it on their own hardware. You’ll still need some beefy hardware: Meta says it can run on a "single server node," which isn’t desktop PC-grade equipment. But it’s a provocative shot across the bow of "closed" AI model vendors such as OpenAI and Anthropic.
"Llama 3.1 405B is the first openly available model that rivals the top AI models when it comes to state-of-the-art capabilities in general knowledge, steerability, math, tool use, and multilingual translation," says Meta. Company CEO Mark Zuckerberg calls 405B "the first frontier-level open source AI model."
In the AI industry, "frontier model" is a term for an AI system designed to push the boundaries of current capabilities. In this case, Meta is positioning 405B among the likes of the industry’s top AI models, such as OpenAI’s GPT-4o, Claude’s 3.5 Sonnet, and Google Gemini 1.5 Pro.
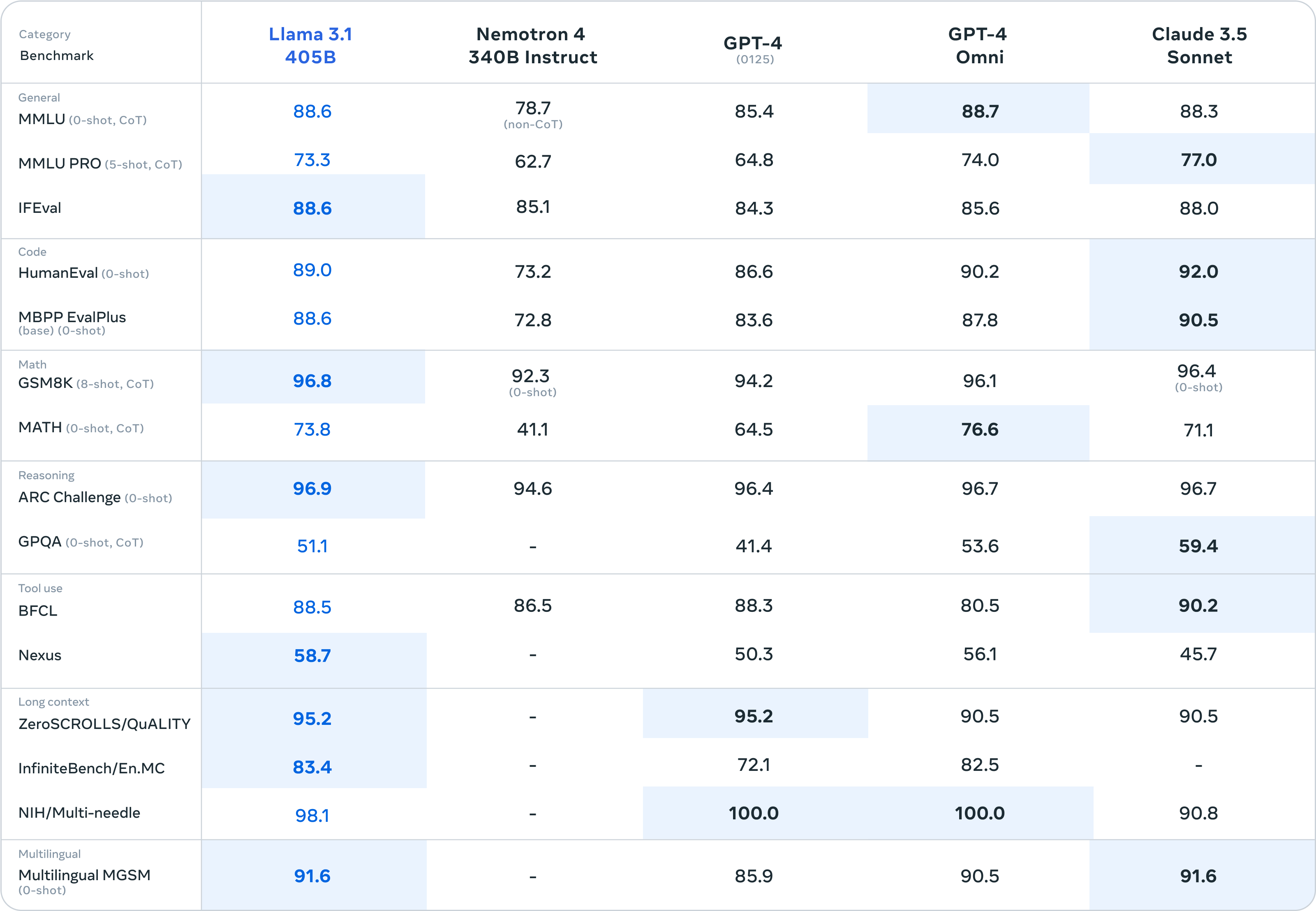
A chart published by Meta suggests that 405B gets very close to matching the performance of GPT-4 Turbo, GPT-4o, and Claude 3.5 Sonnet in benchmarks like MMLU (undergraduate level knowledge), GSM8K (grade school math), and HumanEval (coding).
But as we’ve noted many times since March, these benchmarks aren’t necessarily scientifically sound or translate to the subjective experience of interacting with AI language models. In fact, this traditional slate of AI benchmarks is so generally useless to laypeople that even Meta’s PR department now just posts a few images of charts and doesn’t even try to explain them in any detail.
Enlarge/ A Meta-provided chart that shows Llama 3.1 405B benchmark results versus other major AI models.
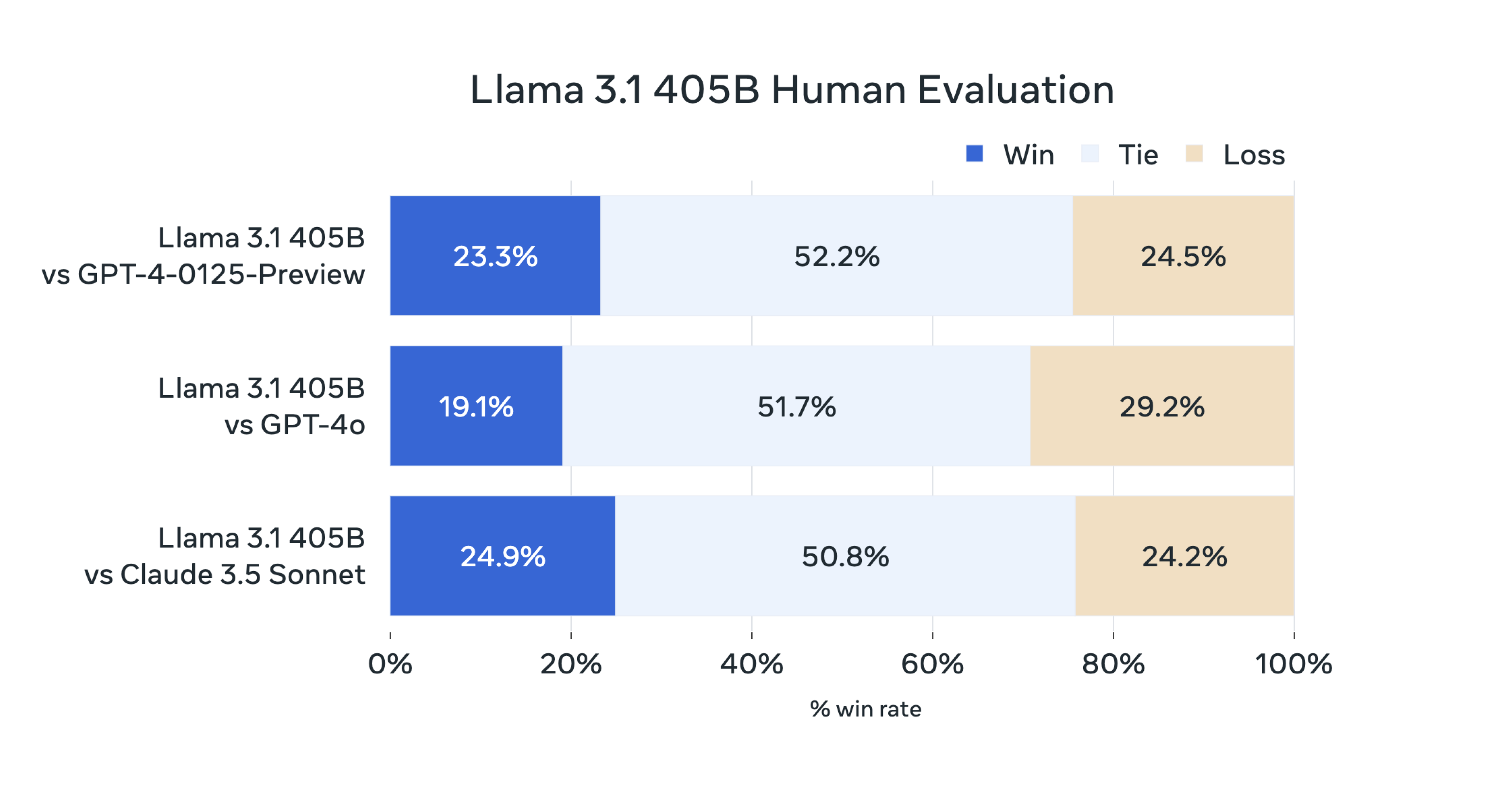
We’ve instead found that measuring the subjective experience of using a conversational AI model (through what might be called "vibemarking") on A/B leaderboards like Chatbot Arena is a better way to judge new LLMs. In the absence of Chatbot Arena data, Meta has provided the results of its own human evaluations of 405B’s outputs that seem to show Meta’s new model holding its own against GPT-4 Turbo and Claude 3.5 Sonnet.
Enlarge/ A Meta-provided chart that shows how humans rated Llama 3.1 405B’s outputs compared to GPT-4 Turbo, GPT-4o, and Claude 3.5 Sonnet in its own studies.
Whatever the benchmarks, early word on the street (after the model leaked on 4chan yesterday) seems to match the claim that 405B is roughly equivalent to GPT-4. It took a lot of expensive computer training time to get there—and money, of which the social media giant has plenty to burn. Meta trained the 405B model on over 15 trillion tokens of training data scraped from the web (then parsed, filtered, and annotated by Llama 2), using more than 16,000 H100 GPUs.
So what’s with the 405B name? In this case, "405B" means 405 billion parameters, and parameters are numerical values that store trained information in a neural network. More parameters translate to a larger neural network powering the AI model, which generally (but not always) means more capability, such as better ability to make contextual connections between concepts. But larger-parameter models have a tradeoff in needing more computing power (AKA "compute") to run.
We’ve been expecting the release of a 400+ billion parameter model of the Llama 3 family since Meta gave word that it was training one in April, and today’s announcement isn’t just about the biggest member of the Llama 3 family: There’s an entire new iteration of improved Llama models with the designation "Llama 3.1." That includes upgraded versions of its smaller 8B and 70B models, which now feature multilingual support and an extended context length of 128,000 tokens (the "context length" is roughly the working memory capacity of the model, and "tokens" are chunks of data used by LLMs to process information).
Meta says that 405B is useful for long-form text summarization, multilingual conversational agents, and coding assistants and for creating synthetic data used to train future AI language models. Notably, that last use-case—allowing developers to use outputs from Llama models to improve other AI models—is now officially supported by Meta’s Llama 3.1 license for the first time.
Abusing the term “open source”
Llama 3.1 405B is an open-weights model, which means anyone can download the trained neural network files and run them or fine-tune them. That directly challenges a business model where companies like OpenAI keep the weights to themselves and instead monetize the model through subscription wrappers like ChatGPT or charge for access by the token through an API.
Fighting the "closed" AI model is a big deal to Mark Zuckerberg, who simultaneously released a 2,300-word manifesto today on why the company believes in open releases of AI models, titled, "Open Source AI Is the Path Forward." More on the terminology in a minute. But briefly, he writes about the need for customizable AI models that offer user control and encourage better data security, higher cost-efficiency, and better future-proofing, as opposed to vendor-locked solutions.
All that sounds reasonable, but undermining your competitors using a model subsidized by a social media war chest is also an efficient way to play spoiler in a market where you might not always win with the most cutting-edge tech. That benefits Meta, Zuckerberg says, because he doesn’t want to get locked into a system where companies like his have to pay a toll to access AI capabilities, drawing comparisons to "taxes" Apple levies on developers through its App Store.
Enlarge/ A screenshot of Mark Zuckerberg’s essay, "Open Source AI Is the Path Forward," published on July 23, 2024.
So about that "open source" term. As we first wrote in an update to our Llama 2 launch article a year ago, "open source" has a very particular meaning that has traditionally been defined by the Open Source Initiative. The AI industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (such as Llama 3.1) or that ship without providing training data. We’ve been calling these releases "open weights" instead.
Unfortunately for terminology sticklers, Zuckerberg has now baked the erroneous "open source" label into the title of his potentially historic aforementioned essay on open AI releases, so fighting for the correct term in AI may be a losing battle. Still, his usage annoys people like independent AI researcher Simon Willison, who likes Zuckerberg’s essay otherwise.
"I see Zuck’s prominent misuse of ‘open source’ as a small-scale act of cultural vandalism," Willison told Ars Technica. "Open source should have an agreed meaning. Abusing the term weakens that meaning which makes the term less generally useful, because if someone says ‘it’s open source,’ that no longer tells me anything useful. I have to then dig in and figure out what they’re actually talking about."
The Llama 3.1 models are available for download through Meta’s own website and on Hugging Face. They both require providing contact information and agreeing to a license and an acceptable use policy, which means that Meta can technically legally pull the rug out from under your use of Llama 3.1 or its outputs at any time.
The HBO Original Series Dune: Prophecy will premiere this November.
Fans of director Denis Villeneuve’s epic two-part film adaptation of Frank Herbert’s Dune have no doubt been curious about the upcoming HBO Max series, Dune: Prophecy. It’s a prequel series inspired by the novel Sisterhood of Dune, written by Brian Herbert and Kevin J. Anderson, exploring the origins of the Bene Gesserit. The studio just dropped a tantalizing teaser rife with political intrigue, ominous warnings, and a bit of hand-to-hand combat.
The series was first announced in 2019, with Villeneuve serving as an executive producer and Alison Schapker (Alias, Fringe, Altered Carbon) serving as showrunner. The first season will consist of six episodes, and it’s unclear how closely the series will adhere to the source material. Per the official premise:
Set 10,000 years before the ascension of Paul Atreides, Dune: Prophecy follows two Harkonnen sisters as they combat forces that threaten the future of humankind, and establish the fabled sect that will become known as the Bene Gesserit.
Emily Watson co-stars as Valya Harkonnen, leader of the Sisterhood, with Olivia Williams playing her sister, Tula Harkonnen. Mark Strong plays Emperor Javicco Corrino, described as "a man from a great line of war-time Emperors, who is called upon to govern the Imperium and manage a fragile peace," while Jodhi May plays Empress Natalya and Sarah-Sofie Boussnina plays Princess Ynez.
The cast also includes Shalom Brune-Franklin as Mikaela, a Fremen woman who serves the royal family; Travis Fimmel as Desmond Hart, described as "a charismatic soldier with an enigmatic past"; Chris Mason as swordsman Keiran Atreides; Josh Heuston as Constantine Corrino, the illegitimate son of Javicco; Edward Davis as rising politician Harrow Harkonnen; Tabu as Sister Francesca, the Emperor’s former lover; Jihae as Reverend Mother Kasha, the Emperor’s Truthsayer; Faoileann Cunningham as Sister Jen, Chloe Lea as Lila, Jade Anouka as Sister Theodosia, and Aoife Hinds as Sister Emeline, all acolytes at the Sisterhood School.
Power = control
A short teaser was shown in May during the Warner Bros. Discovery Upfront presentation in New York City. It was heavy on the exposition, with a voiceover describing the founding of a sisterhood assigned to the Great Houses "to help them sift truth from lies." The result was a "network of influence throughout the Imperium… but power comes with a price." They want to place a Sister on the throne and arrange a marriage to make it possible. Not all the Sisters were on board with the plan, however, with one warning that the Sisterhood was playing god "and we will be judged for it."
This latest teaser opens with an admonition to acolytes of the Sisterhood: "You wish to serve the Great Houses and shape the flow of power; you must first exert power over yourself." The emperor seems to be easily wooed by the "sorceresses," much to his empress’s chagrin, but the more influence the Sisterhood wields, the more enemies it gains. Desmond Hart also has his suspicions about the Sisterhood, probably with good reason. "Our hands are poised on the levers of power but yet our grasp on it is still fragile," Valya tells her sister Tula, assuring her that "I am trying to protect the Imperium"—and "sacrifices must be made."
https://www.percona.com/blog/wp-content/uploads/2024/06/Improving-MySQL-Query-Performance-200×112.jpgMySQL is certainly a powerful open source database management system, but even the most robust engine struggles when queries take an eternity to execute. For DBAs and developers, improving MySQL query performance is an ongoing goal. Efficient query performance is crucial for ensuring the smooth operation and optimal user experience of applications powered by MySQL […]Percona Database Performance Blog
Since Alaska has so little darkness on July 4th, they’ve got an alternative for fireworks. For over 20 years, Glacier View, Alaska, has hosted an event where they toss junk cars off a 300-foot cliff while onlookers enjoy the chaos and destruction. 1320video attended this year’s festivities to give us an insider’s look at the event, including POV and aerial footage.
Not to be outdone by How Ridiculous and their soccer balls, the dudes from Dude Perfect booked a flight with the U.S. Air Force, filled a C-17 cargo plane with 1000 basketballs, and dropped them all to see if they could score a basket or two. Before shooting hoops, they played the world’s largest game of darts and the opposite of miniature golf.
Amazon Web Services is the latest entrant to the generative AI game with the announcement of App Studio, a groundbreaking tool capable of building complex software applications from simple written prompts. TechCrunch’s Ron Miller reports: "App Studio is for technical folks who have technical expertise but are not professional developers, and we’re enabling them to build enterprise-grade apps," Sriram Devanathan, GM of Amazon Q Apps and AWS App Studio, told TechCrunch. Amazon defines enterprise apps as having multiple UI pages with the ability to pull from multiple data sources, perform complex operations like joins and filters, and embed business logic in them. It is aimed at IT professionals, data engineers and enterprise architects, even product managers who might lack coding skills but have the requisite company knowledge to understand what kinds of internal software applications they might need. The company is hoping to enable these employees to build applications by describing the application they need and the data sources they wish to use.
Examples of the types of applications include an inventory-tracking system or claims approval process. The user starts by entering the name of an application, calling the data sources and then describing the application they want to build. The system comes with some sample prompts to help, but users can enter an ad hoc description if they wish. It then builds a list of requirements for the application and what it will do, based on the description. The user can refine these requirements by interacting with the generative AI. In that way, it’s not unlike a lot of no-code tools that preceded it, but Devanathan says it is different. […] Once the application is complete, it goes through a mini DevOps pipeline where it can be tested before going into production. In terms of identity, security and governance, and other requirements any enterprise would have for applications being deployed, the administrator can link to existing systems when setting up the App Studio. When it gets deployed, AWS handles all of that on the back end for the customer, based on the information entered by the admin.



 MySQL is certainly a powerful open source database management system, but even the most robust engine struggles when queries take an eternity to execute. For DBAs and developers, improving MySQL query performance is an ongoing goal. Efficient query performance is crucial for ensuring the smooth operation and optimal user experience of applications powered by MySQL […]Percona Database Performance Blog
MySQL is certainly a powerful open source database management system, but even the most robust engine struggles when queries take an eternity to execute. For DBAs and developers, improving MySQL query performance is an ongoing goal. Efficient query performance is crucial for ensuring the smooth operation and optimal user experience of applications powered by MySQL […]Percona Database Performance Blog

