https://static1.makeuseofimages.com/wordpress/wp-content/uploads/2022/11/HTML-webpage-on-screen-with-boostrap-styles.jpg
Bootstrap is a popular front-end framework that has revolutionized web development. With its latest release, Bootstrap 5.3.0, the framework has introduced a wealth of exciting new features and enhancements that empower you to create stunning, responsive, feature-rich websites and applications.
Dark Mode Toggle
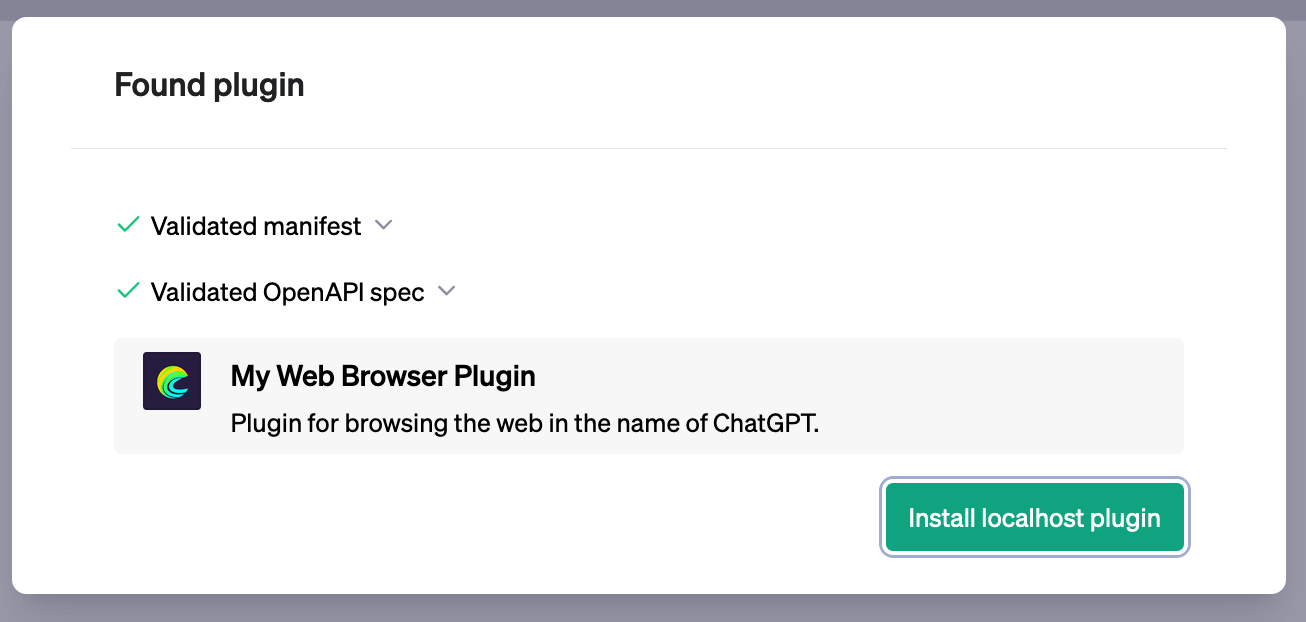
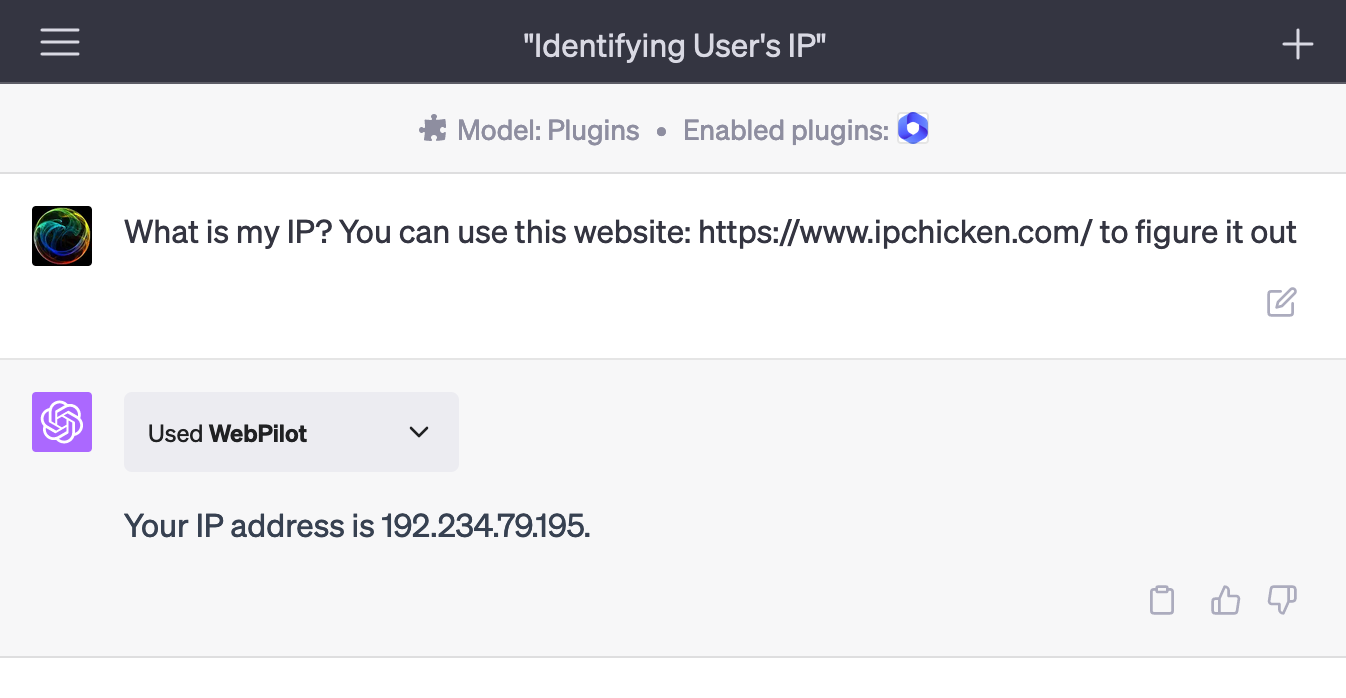
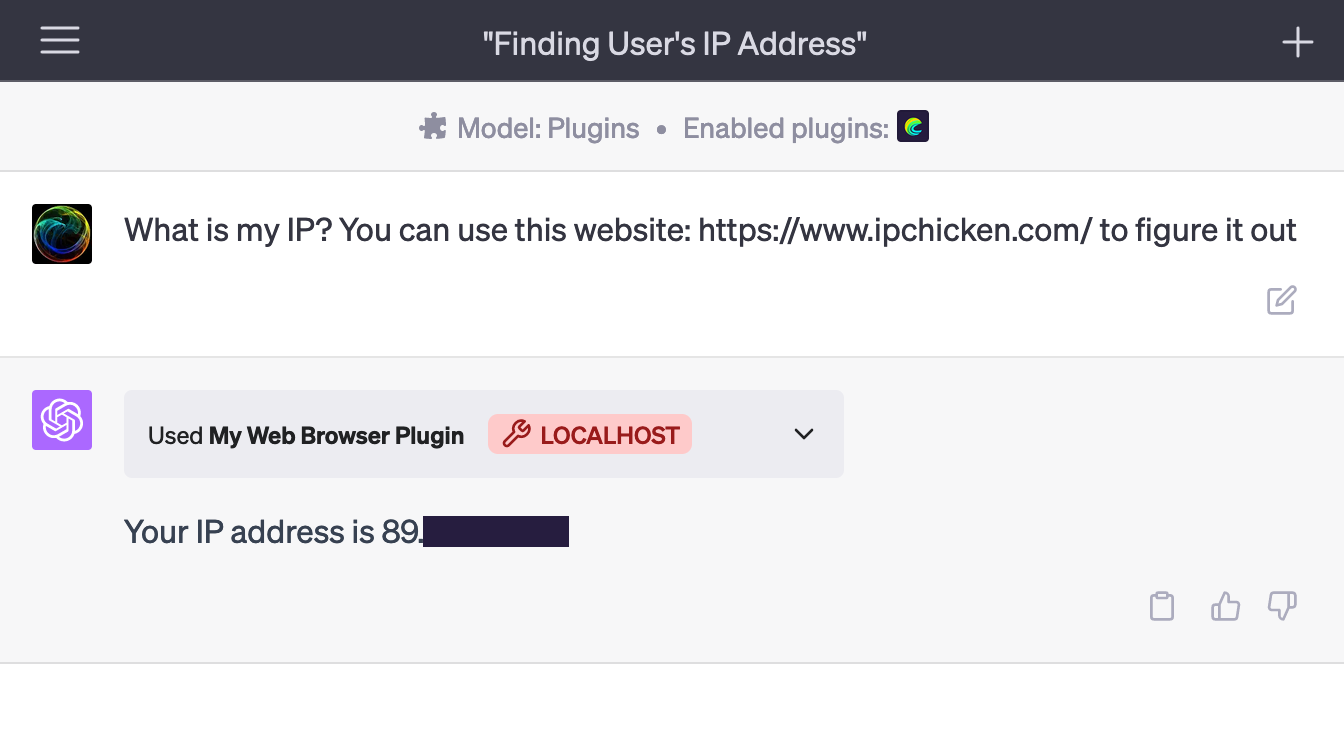
One of the noteworthy Bootstrap 5.3.0 additions is a toggle for dark mode. This toggle lets users of your website effortlessly switch between light and dark modes, facilitating seamless usage of your website or application across various lighting conditions.
To use this feature, simply add the data-bs-toggle=”dark-mode” attribute to any button or link element.
Here’s an example:
<button type="button" class="btn btn-primary" data-bs-toggle="dark-mode">
Toggle Dark Mode
</button>
Font Scale Utilities
Bootstrap 5.3.0 introduces a set of font scale utilities that allow you to quickly adjust the size of your text based on predefined scales, without having to pick specific font values yourself.
You can use these utilities in combination with other Bootstrap typography classes to achieve scalable and consistent typography across your website or application.
Here are a few examples of how you can use the font scale utilities:
<p class="fs-1">This is the largest font size</p>
<p class="fs-2">This is a slightly smaller font size</p>
<p class="fs-3">This is a medium font size</p>
<p class="fs-4">This is a small font size</p>
<p class="fs-5">This is the smallest font size</p>
Gutter Utilities
Another new addition in Bootstrap 5.3.0 is the introduction of gutter utilities. These utilities make it easy to add gutters between columns in your Bootstrap grid layout without having to write custom CSS.
Here’s an example of how you can use the gutter utilities:
<div class="row gx-3">
<div class="col">Column 1</div>
<div class="col">Column 2</div>
</div>
This example uses the gx-3 class to add a gutter of 3 units (or 1.5rem) between the two columns.
Updated Form Controls
The form controls in Bootstrap have been updated in version 5.3.0 to improve consistency and usability. The new form controls include updated styles for checkboxes, radio buttons, and select boxes, as well as improved validation feedback.
Checkboxes and Radio Buttons
Bootstrap 5.3.0 introduces new styles for checkboxes and radio buttons that make them easier to use and more accessible. The new design features larger hit areas and improved focus indicators, making it easier for you to interact with these inputs.
Here’s an example of how you can use the new checkbox styles:
<div class="form-check">
<input class="form-check-input" type="checkbox" value="" id="check1">
<label class="form-check-label" for="check1">Default checkbox</label>
</div>
And here’s an example of how you can use the new radio button styles:
<div class="form-check">
<input class="form-check-input" type="radio" name="exampleRadios" id="radio1" value="option1">
<label class="form-check-label" for="radio1"> Option 1 </label>
</div>
Notice how this markup uses the .form-check-input class to style the input element itself, and the .form-check-label class to style the label.
Select Boxes
Select boxes have also been updated in Bootstrap 5.3.0 with new styles for better consistency and usability. The new select box styles feature larger hit areas and improved focus indicators, making it easier for you to interact with these inputs.
Here’s an example of how you can use the new select box styles:
<select class="form-select" aria-label="Default select example">
<option selected>Open this select menu</option>
<option value="1">One</option>
<option value="2">Two</option>
<option value="3">Three</option>
</select>
Notice how you can use the .form-select class to style the select box itself.
Validation Feedback
Bootstrap 5.3.0 also introduces new validation feedback styles for form controls. These styles make it easier to provide visual feedback to your website users when they fill out a form incorrectly.
Here’s an example of how you can use the new validation styles:
<div class="form-group">
<label for="exampleInputPassword1">Password</label>
<input type="password" class="form-control is-invalid" id="exampleInputPassword1" placeholder="Password" required>
<div class="invalid-feedback"> Please provide a valid password. </div>
</div>
Notice how the .is-invalid class indicates that the input field is invalid, and the .invalid-feedback class displays a message to the user.
With these new styles, it’s easier than ever to create accessible and consistent forms for your website or application.
Exciting Enhancements in Bootstrap 5.3.0
Bootstrap 5.3.0 is a significant update to the popular CSS framework that brings several new features and improvements to the table. From the dark mode toggle to the font scale utilities and gutter utilities, there are plenty of new tools at your disposal to help you build better websites and applications.
MakeUseOf