Managing the logs in a centralized repository is one of the most common best practices in the DevOps world. Application logs, system logs, error logs, and any databases logs also will be pushed into your centralized repository. You can use ELK stack or Splunk to visualize the logs to get better insights about it. But as a SQL guy, I wanted to solve this problem with Bigdata ecosystem(use SQL). As a part of that process, we can relationalize unstructured data in AWS Athena with the help of GrokSerDe.
Here S3 is my centralized repository. I know it will not scale like ElasticSearch, but why should I miss this Fun. For this use case, Im going to rationalize the SQL Server Error log in AWS Athena. Let’s take a look at the SQL server’s error log pattern.
2019-09-21 12:53:17.57 Server UTC adjustment: 0:00
2019-09-21 12:53:17.57 Server (c) Microsoft Corporation.
2019-09-21 12:53:17.57 Server All rights reserved.
2019-09-21 12:53:17.57 Server Server process ID is 4152.
Its looks like
yyyy-mm-dd space hh:mm:ss:ms space User space message
But sometimes, it has many lines like below.
2019-09-21 12:53:17.57 Server Microsoft SQL Server 2017 (RTM) - 14.0.1000.169 (X64)
Aug 22 2017 17:04:49
Copyright (C) 2017 Microsoft Corporation
Enterprise Edition: Core-based Licensing (64-bit) on Windows Server 2016 Datacenter 10.0 <X64> (Build 14393: ) (Hypervisor)
2019-09-21 12:53:17.57 Server UTC adjustment: 0:00
2019-09-21 12:53:17.57 Server (c) Microsoft Corporation.
If you see the 2nd, 3rd line we have the only message. And we know these all are just for information purpose, we’ll not get any useful information with that. Also as a part of Data cleansing, we should clean up some unwanted lines to make this relationalize.
I can consider the below format for my relationalize structure.
- Year – Integer
- Month – Integer
- Day – Integer
- Hour – Integer
- Minute – Integer
- Second – Integer
- User – String
- Message – String
We can convert this into a Grok pattern for this.
%{YEAR:year}-%{MONTHNUM:month}-%{MONTHDAY:day}\\s*%{TIME:time} %{LOG_LEVEL:user}\\s*( )*%{GREEDYDATA:message}
Create the table in Athena:
CREATE EXTERNAL TABLE `sql_errorlog`(
`year` string ,
`month` string ,
`day` string ,
`time` string ,
`user` string ,
`message` string )
ROW FORMAT SERDE
'com.amazonaws.glue.serde.GrokSerDe'
WITH SERDEPROPERTIES (
'input.format'='%{YEAR:year}-%{MONTHNUM:month}-%{MONTHDAY:day}\\s*%{TIME:time} %{LOG_LEVEL:user}\\s*( )*%{GREEDYDATA:message}',
'input.grokCustomPatterns'='LOG_LEVEL \[a-zA-Z0-9\]*')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://bhuvi-datalake/sql-error-log/'
The table got created. I used a custom pattern for pulling the user column.
Query the data:
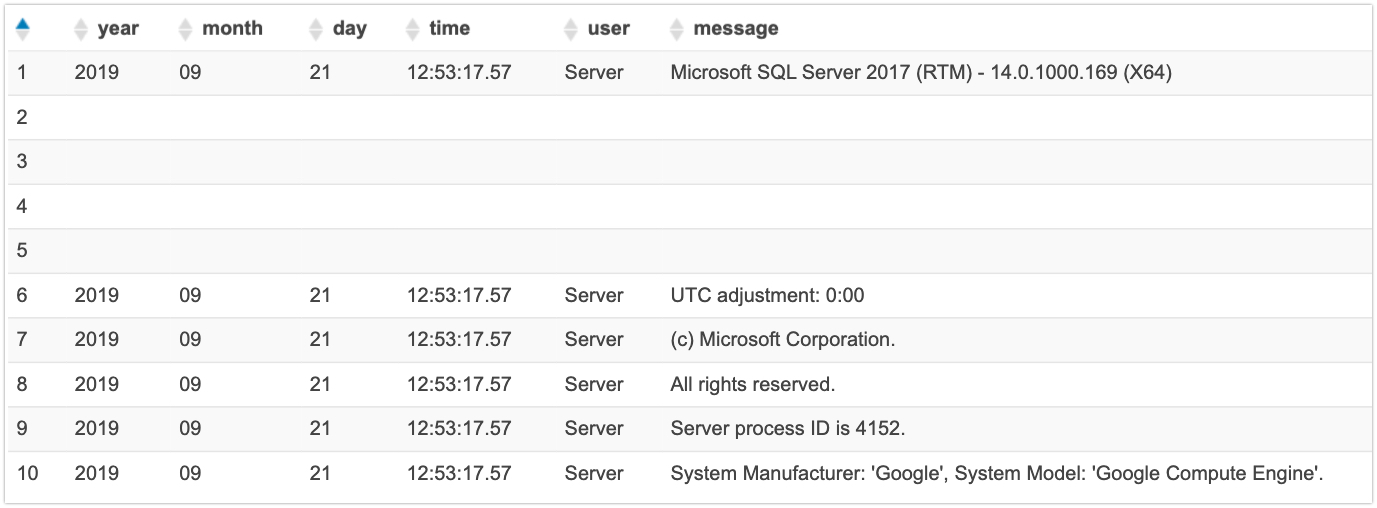
SELECT *
FROM "default"."sql_errorlog" limit 10;
SELECT *
FROM "default"."sql_errorlog"
WHERE message LIKE '%shutdown%';

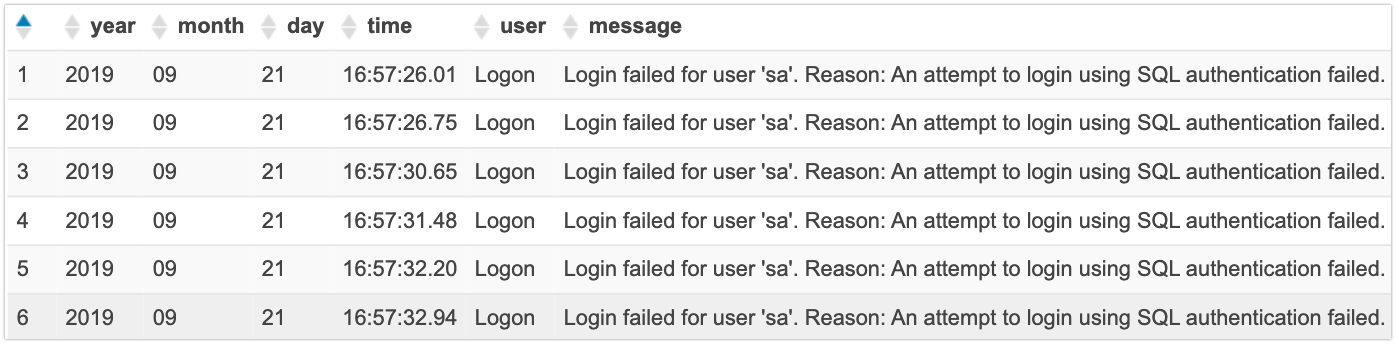
SELECT *
FROM "default"."sql_errorlog"
WHERE message LIKE '%Login failed%'
SELECT concat ('Server started at: ',year,'-',month,'-',day,' ',time) AS StartupTime
FROM "default"."sql_errorlog"
WHERE message LIKE '%Server process ID is%';

This is just a beginner guide, you can play around with windows logs, linux syslog, if you are a DBA then you may like to use this for MySQL, PostgreSQL, MongoDB logs.
BONUS: Regex Serde
If you are a developer, then regex might be easy for you. You can create a table with Regex Serde. Thanks to LeftJoin Who helped to write this Regex
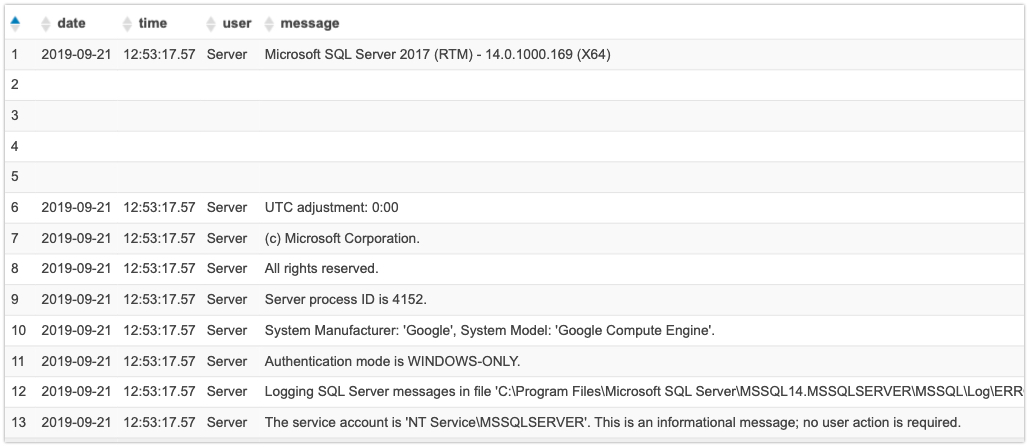
CREATE EXTERNAL TABLE `bhuvi`(
`date` string ,
`time` string ,
`user` string ,
`message` string )
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'input.regex'='(.*\\-.*\\-.*)\\s+(\\d+:\\d+:\\d+.\\d+)\\s+(\\S+)\\s+(.*?)$')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://bhuvi-datalake/bhuvi-1/'
References:
via Planet MySQL
Relationalize Unstructured Data In AWS Athena with GrokSerDe