https://hashnode.com/utility/r?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1642053183825%2FTrLri6Qo6.jpeg%3Fw%3D1200%26h%3D630%26fit%3Dcrop%26crop%3Dentropy%26auto%3Dcompress%2Cformat%26format%3Dwebp%26fm%3Dpng
Introduction
When you are still in that learning phase with any technology, your focus is to make your app work, but I think the exponential progress starts coming when you begin to ask yourself “How can I make this better?”. One simple principle that you can immediately apply to your existing or new codebase for cleaner and more maintainable code is the Separation of Concerns principle.
Most of the server-side codebases I have come across have controllers that contain code specifying the real-world business rules on how data can be created, stored, and changed on the system. If you want to learn how to build controllers that are clean, concise, and easily maintainable, then this series is for you.
What you will learn after reading this article
-
You will have a solid understanding of the Separation of concerns principle
-
You will be able to identify the major steps involved in the lifecycle of a request on the server-side
-
You will understand the role of the controller on the server side. This will ensure that the lines of code present in your controller functions are the ones that absolutely need to be in the controller
Prerequisites
- Understanding of client-server architecture
- Familiarity with model-view-controller architecture
- A basic understanding of Object-Oriented Programming
With all that out of the way, let’s move 🚀
Understanding Separation of concerns
What is a concern?
A concern is a section of a feature or software that handles a particular functionality in the system. A good example of a concern in a well-designed backend system is request validation, which means there is a part of the code that accepts the data coming from the client to make sure all the information is valid or at least in the right format before sending it to the other parts of the system.
What does the term Separation of concerns mean?
Since we know what a concern is, understanding the idea behind the Separation of concerns will not be difficult. Separation of concerns promotes the idea of building software in such a way that our code should be broken down into separate components or layers such that each layer handles a specific concern. An example is a feature that retrieves data from the database and then formats the data based on the client’s request. Placing both logic in the same function is a really bad idea since retrieving data from the database is a specific concern, then formatting the retrieved data is another concern.
Lifecycle of a request on the server
I have worked on building many backend systems that provide services to clients and many of them usually follow a similar pattern with 3 major steps which are mainly.
- Request validation: This refers to the part of your code that ensures that the data sent by a client is in a valid and acceptable format. A simple example is making sure that a value sent from the client as an email is actually a valid email address.
- Business logic execution: This is the section of your codebase that contains the code that enforces real-world business rules. Let’s use an app that allows a customer to transfer money from one account to another. A valid business rule is that you cannot transfer an amount that is greater than your current balance. For this app to work properly, there has to be a section of your code that compares the amount you are trying to transfer and your current balance and makes sure the business rule is obeyed. That is what we refer to as business logic.
- Response formatting and return:This refers to the section of your codebase responsible for making sure the data returned to the client after business logic execution is properly formatted and well presented. eg JSON, XML

I have come across a lot of codebases that perform these three steps using a single function or method, where line 10 to 15 handles request validation, line 16 to 55 handles all the business logic with long if-else statements, loops, etc, then line 56-74 formats the response based on certain conditions, and finally, line 75 returns the data to the client. That’s about 65 lines of code in a single function! That is a ticking time bomb waiting to explode when a new engineer joins the team or when you come back to add more changes to the code.
Understanding the role of the controller in the backend request lifecycle
Imagine we have 3 tasks involving the same feature.
- Fix a bug in request validation
- Change the way data is retrieved from the database (use Eloquent ORM instead of raw queries)
- Add extra meta-data to the response returned to the client
If our controllers are designed in a way where each method contains all these three major steps involved in fulfilling a request on the server-side, then the flow looks something like the image below
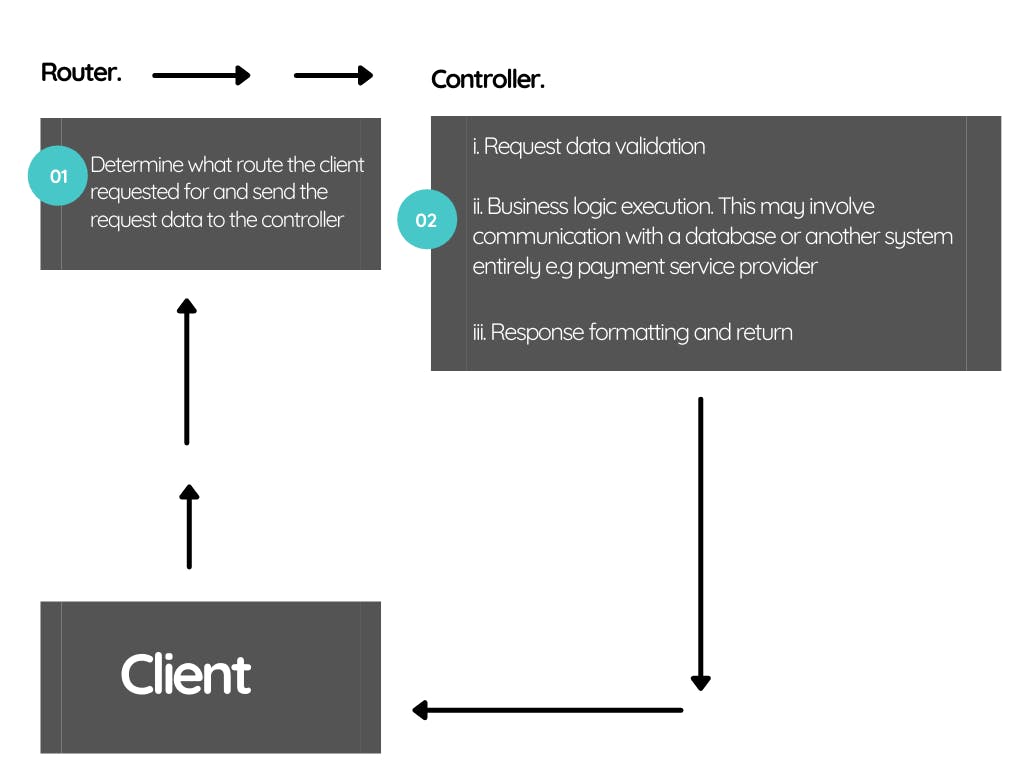
Handling these tasks become a nightmare because everyone in the team will be modifying the same function, and good luck merging all these changes without the need to resolve merge conflicts 🙄.
So, what exactly should the controller do?
The controller should serve as a delegator, meaning that the controller accepts a request with the associated data from the client, then the controller should assign the different tasks involved in fulfilling the client’s request to different parts of the codebase, then finally, the controller sends a proper response (success or failure) to the client depending on the result of the executed code.
I have illustrated this using the image below.
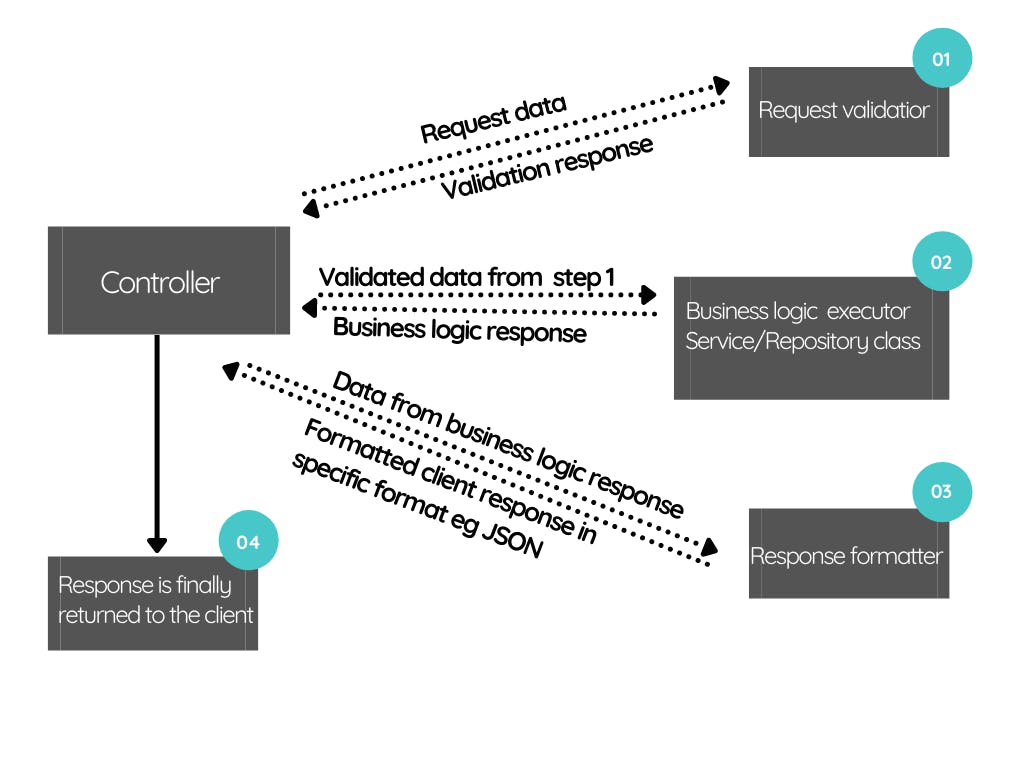
If our controllers are built this way, making changes will be incredibly easy, bugs will be easy to trace and the responsibility of each class and other classes it depends on to fulfill its tasks will be immediately visible even to someone looking at the code for the first time.
There is more juicy stuff to come 😋
Like I said at the beginning of the article, this is going to be a series because there is a lot of information to digest and I want to make sure you can remember a lot after reading each article. I want to separate the concerns you know 😂, so that this article does not become massive like the controllers we will be refactoring starting from the next part. If you didn’t get that joke, then maybe next time.
In the next article, Part 2. We will be refactoring a controller function with a specific focus on the Request validation concern. We will build a Request validator class and abstract all the logic involved in validating the client’s request away from the controller. I will be using Laravel in the rest of the series.
Quick Recap
- Separation of concerns is simply a concept that promotes the idea that you should always look at your code to identify the different functionalities involved, and think of how you can break down the code into smaller components for clarity, easy debugging, and maintenance among other benefits.
- All the logic involved in fulfilling a client’s request on the server-side should not be in a single location, like a controller.
- The controllers should serve as classes that delegate tasks to other parts of the codebase and get’s back a response from those other parts. Depending on the response received by the controller, the controller decides if the response to send back to the client should be a success or failure response.
- More code might be involved when trying to break down a feature into smaller components but remember, it pays off in the long run.
It’s a wrap 🎉
I sincerely hope that you have learned something, no matter how small, after reading this. If you did, kindly drop a thumbs up.
Thanks for sticking with me till the end. If you have any suggestions or feedback, kindly drop them in the comment section. Enjoy the rest of your day…bye 😊.
Laravel News Links