https://ronaldbradford.com/images/blog/mysql-26-7-early-access.png
MySQL has dropped its newest release
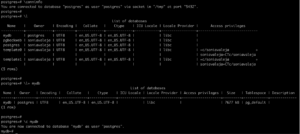
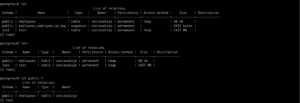
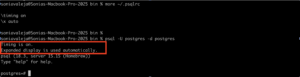
, categorized as “Early Access” and available at https://labs.mysql.com/
.
While this post is not going to go into depth, I wanted to at least validate the management changes you verify between normal MySQL upgrades.
The new release version is `26.7`, the first version with a date-based release number convention. While this is numerically increased, the first problem I found was a character ordering problem not found in prior scripts. This is because 2 is before 9, historically for any version, the versions listed alphabetically would always list older before newer. MySQL isn’t the only product that uses this naming convention, or the first to switch from one to the other, however some random MySQL script on some customer installation is going to have some small issue and there will be the unnecessary followup flamewar. See later as to why I mentioned this.
Docker Containers Setup
Preamble
TMP_DIR=${TMP_DIR:-/tmp}
TEST_CASE="first-look"
rm ${TMP_DIR}/${TEST_CASE}.*
Install MySQL 9.7
The following will install the current MySQL 9.7 docker version.
REGISTRY_NAME="container-registry.oracle.com/mysql/community-server:9.7"
CONTAINER_NAME="mysql097"
docker pull ${REGISTRY_NAME}
MYSQL_PASSWD="M#$(date | md5sum - | cut -c-20)"
OUTPUT=$(docker run -d --name ${CONTAINER_NAME} \
--platform linux/amd64 \
-e MYSQL_ROOT_PASSWORD=${MYSQL_PASSWD} \
${REGISTRY_NAME})
echo $?
echo $OUTPUT
# Not completely accurate
# docker logs ${CONTAINER_NAME} | grep "ready for connections"
sleep 5
docker exec -it ${CONTAINER_NAME} mysql -uroot -p${MYSQL_PASSWD} -sN -e "SELECT VERSION()" | grep -v "can be insecure"
docker stop ${CONTAINER_NAME} && docker rm ${CONTAINER_NAME}
Install MySQL 26.7 EA
In a separate terminal window run.
# See https://labs.mysql.com/ to obtain valid and current direct download links
wget https://downloads.mysql.com/snapshots/pb/mysql-26.7.0-labs-release/mysql-community-server-26.7.0-labs-docker-el9-x86_64.tar.gz
docker load -i mysql-community-server-26.7.0-labs-docker-el9-x86_64.tar.gz
REGISTRY_NAME="localhost/mysql/community-server:26.7.0"
CONTAINER_NAME="mysql267"
...
New Variables
The 26.7 Release Notes
are not accompanied by a current reference Manual (e.g. 9.7
) so this default checking gives a first approximate look.
What it doesn’t find is for example the setup for a replica, or different distros, or following the installation of any components in which there is noted new work.
# Run for both containers
$ docker exec -it ${CONTAINER_NAME} mysql -uroot -p${MYSQL_PASSWD} -s -e "SELECT VERSION(); SELECT VARIABLE_NAME FROM performance_schema.global_variables ORDER BY 1" > ${TMP_DIR}/${TEST_CASE}.variables.${CONTAINER_NAME}.txt
$ diff -y --suppress-common-lines ${TMP_DIR}/${TEST_CASE}.variables.*.txt
9.7.1 | 26.7.0-er
> admin_force_pqc
> admin_tls_kex
> admin_use_pqc_sign
> force_pqc
> innodb_autoinc_preallocate
> mysqlx_force_pqc
> mysqlx_tls_kex
> mysqlx_use_pqc_sign
> replication_force_pqc
> replication_tls_kex
> replication_use_pqc_sign
> tls_kex
> use_pqc_sign
One of my primary goals in further evaluation is the Post-quantum cryptography support with OpenSSL 3.5. You can find some intro information in my post Q Day Is Coming: A Plain-English Guide to Post-Quantum Cryptography
. Almost all these variables align with this functionality. The kex variables is the standard abbreviation for key exchange. The pqc variables are related to the negotiation of a PQC (or Hybrid) group. As you can see in the next section, all pqc related variables are OFF.
Based on this information, without looking into source, the force_pqc, tls_kex and use_pqc_sign would be the required three variables to enable post quantum key exchange.
Variable Values
$ docker exec -it ${CONTAINER_NAME} mysql -uroot -p${MYSQL_PASSWD} -s -e "SELECT VERSION(); SELECT VARIABLE_NAME, VARIABLE_VALUE FROM performance_schema.global_variables ORDER BY 1" > ${TMP_DIR}/${TEST_CASE}.var-value.${CONTAINER_NAME}.txt
$ diff -y --suppress-common-lines ${TMP_DIR}/${TEST_CASE}.var-value.*.txt | grep ">" | cut -d'>' -f2-
admin_force_pqc OFF
admin_tls_kex
admin_use_pqc_sign OFF
force_pqc OFF
innodb_autoinc_preallocate 50
mysqlx_force_pqc OFF
mysqlx_tls_kex
mysqlx_use_pqc_sign OFF
replication_force_pqc OFF
replication_tls_kex
replication_use_pqc_sign OFF
tls_kex
There would appear to be no changes to default values for existing variables, however this is just the sandbox docker installation.
Alphabetical and Chronological
I mentioned earlier about chronological and alphabetical issues. This is what I mean. My line of code was to diff mysql97 and mysql267 where previously these would wash out alphabetically, but this does not happen now (i.e. historically it would be mysql8, mysql84, mysql97). mysql267 preceeds mysql97, and hence why the container for simplicity of commands is called mysql097.
$ diff -y --suppress-common-lines ${TMP_DIR}/${TEST_CASE}.variables.*.txt
26.7.0-er | 9.7.1
admin_force_pqc <
admin_tls_kex <
admin_use_pqc_sign <
force_pqc <
innodb_autoinc_preallocate <
mysqlx_force_pqc <
mysqlx_tls_kex <
mysqlx_use_pqc_sign <
replication_force_pqc <
replication_tls_kex <
replication_use_pqc_sign <
tls_kex <
use_pqc_sign <
New Status Variables
$ docker exec -it ${CONTAINER_NAME} mysql -uroot -p${MYSQL_PASSWD} -s -e "SELECT VERSION(); SELECT VARIABLE_NAME FROM performance_schema.global_status ORDER BY 1" > ${TMP_DIR}/${TEST_CASE}.status.${CONTAINER_NAME}.txt
$ diff -y --suppress-common-lines ${TMP_DIR}/${TEST_CASE}.status.*.txt
9.7.1 | 26.7.0-er
> Mysqlx_force_pqc
> Mysqlx_tls_kex
> Mysqlx_use_pqc_sign
There would appear to be three new status variables related only to the mysqlx access of the post quantum support. Nothing for admin or replication, however again this is a primary and not a replica.
Status Values
Looking at values on two different systems is more complicated for many factors, however a quick scan reveals no obvious changes in volumes or measure.
$ diff -y --suppress-common-lines ${TMP_DIR}/${TEST_CASE}.status-value.*.txt
9.7.1 | 26.7.0-er
Bytes_received 2115 | Bytes_received 3343
Bytes_sent 52456 | Bytes_sent 90408
Caching_sha2_password_rsa_public_key -----BEGIN PUBLIC KEY | Caching_sha2_password_rsa_public_key -----BEGIN PUBLIC KEY
Connections 14 | Connections 17
Error_log_buffered_bytes 1224 | Error_log_buffered_bytes 1752
Error_log_buffered_events 10 | Error_log_buffered_events 12
Error_log_latest_write 1784693965980559 | Error_log_latest_write 1784693440620348
Handler_commit 592 | Handler_commit 596
Handler_external_lock 6477 | Handler_external_lock 6489
Handler_read_key 1752 | Handler_read_key 1756
Handler_read_next 4160 | Handler_read_next 4166
Handler_read_rnd_next 1768 | Handler_read_rnd_next 3087
Innodb_buffer_pool_bytes_data 19775488 | Innodb_buffer_pool_bytes_data 19906560
Innodb_buffer_pool_load_status Buffer pool(s) load completed | Innodb_buffer_pool_load_status Buffer pool(s) load completed
Innodb_buffer_pool_pages_data 1207 | Innodb_buffer_pool_pages_data 1215
Innodb_buffer_pool_pages_flushed 199 | Innodb_buffer_pool_pages_flushed 198
Innodb_buffer_pool_pages_free 6985 | Innodb_buffer_pool_pages_free 6977
Innodb_buffer_pool_read_requests 16159 | Innodb_buffer_pool_read_requests 16200
Innodb_buffer_pool_reads 1063 | Innodb_buffer_pool_reads 1070
Innodb_buffer_pool_write_requests 1971 | Innodb_buffer_pool_write_requests 1993
Innodb_data_fsyncs 75 | Innodb_data_fsyncs 69
Innodb_data_read 17485312 | Innodb_data_read 17691136
Innodb_data_reads 1089 | Innodb_data_reads 1098
Innodb_data_writes 258 | Innodb_data_writes 253
Innodb_data_written 3336704 | Innodb_data_written 3312640
Innodb_dblwr_pages_written 58 | Innodb_dblwr_pages_written 57
Innodb_dblwr_writes 4 | Innodb_dblwr_writes 3
Innodb_log_write_requests 841 | Innodb_log_write_requests 840
Innodb_log_writes 20 | Innodb_log_writes 18
Innodb_os_log_fsyncs 16 | Innodb_os_log_fsyncs 12
Innodb_os_log_written 53760 | Innodb_os_log_written 52736
Innodb_pages_created 145 | Innodb_pages_created 146
Innodb_pages_read 1062 | Innodb_pages_read 1069
Innodb_pages_written 199 | Innodb_pages_written 198
Innodb_redo_log_checkpoint_lsn 29775665 | Innodb_redo_log_checkpoint_lsn 30006513
Innodb_redo_log_current_lsn 29775665 | Innodb_redo_log_current_lsn 30006513
Innodb_redo_log_flushed_to_disk_lsn 29775665 | Innodb_redo_log_flushed_to_disk_lsn 30006513
Innodb_redo_log_uuid 1560291093 | Innodb_redo_log_uuid 2583501521
Innodb_system_rows_read 4888 | Innodb_system_rows_read 4894
Max_used_connections_time 2026-07-22 04:19:37 | Max_used_connections_time 2026-07-22 04:10:50
> Mysqlx_force_pqc OFF
Mysqlx_ssl_server_not_after Jul 19 04:19:20 2036 GMT | Mysqlx_ssl_server_not_after Jul 19 04:10:35 2036 GMT
Mysqlx_ssl_server_not_before Jul 22 04:19:20 2026 GMT | Mysqlx_ssl_server_not_before Jul 22 04:10:35 2026 GMT
> Mysqlx_tls_kex
> Mysqlx_use_pqc_sign OFF
Open_tables 74 | Open_tables 63
Opened_tables 155 | Opened_tables 144
option_tracker_usage:Traditional Optimizer 15 | option_tracker_usage:Traditional Optimizer 23
Performance_schema_session_connect_attrs_longest_seen 112 | Performance_schema_session_connect_attrs_longest_seen 116
Queries 28 | Queries 44
Questions 27 | Questions 43
Rsa_public_key -----BEGIN PUBLIC KEY-----\nMIIBIjANBgkqhkiG9 | Rsa_public_key -----BEGIN PUBLIC KEY-----\nMIIBIjANBgkqhkiG9
Select_scan 4 | Select_scan 6
Sort_rows 1604 | Sort_rows 2921
Sort_scan 3 | Sort_scan 5
Ssl_server_not_after Jul 19 04:19:20 2036 GMT | Ssl_server_not_after Jul 19 04:10:35 2036 GMT
Ssl_server_not_before Jul 22 04:19:20 2026 GMT | Ssl_server_not_before Jul 22 04:10:35 2026 GMT
Table_locks_immediate 4 | Table_locks_immediate 6
Table_open_cache_hits 3084 | Table_open_cache_hits 3101
Table_open_cache_misses 155 | Table_open_cache_misses 144
Tls_library_version OpenSSL 3.5.1 1 Jul 2025 | Tls_library_version OpenSSL 3.5.5 27 Jan 2026
Uptime 7128 | Uptime 7658
Uptime_since_flush_status 7128 | Uptime_since_flush_status 7658
This is not an exhaustive comparison, however there appears to be no new table objects. There are 3 new replication applier related columns which align with the release notes.
$ docker exec -it ${CONTAINER_NAME} mysql -uroot -p${MYSQL_PASSWD} -s -e "SELECT VERSION(); SELECT TABLE_SCHEMA, TABLE_NAME FROM information_schema.tables ORDER BY 1,2" > ${TMP_DIR}/${TEST_CASE}.tables.${CONTAINER_NAME}.txt
$ diff -y --suppress-common-lines ${TMP_DIR}/${TEST_CASE}.tables.txt
docker exec -it ${CONTAINER_NAME} mysql -uroot -p${MYSQL_PASSWD} -s -e "SELECT VERSION(); SELECT TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME, ORDINAL_POSITION FROM information_schema.columns ORDER BY 1,2,4" > ${TMP_DIR}/${TEST_CASE}.columns.${CONTAINER_NAME}.txt
$ diff -y -W 400 --suppress-common-lines ${TMP_DIR}/${TEST_CASE}.columns.*.txt
9.7.1 | 26.7.0-er
> mysql slave_relay_log_info Applier_version 16
> mysql slave_relay_log_info Applier_worker_count 17
> mysql slave_relay_log_info Applier_event_memory_limit 18
> performance_schema replication_applier_configuration APPLIER_VERSION 8
> performance_schema replication_applier_configuration APPLIER_WORKER_COUNT 9
> performance_schema replication_applier_configuration APPLIER_EVENT_MEMORY_LIMIT 10
Plugins
There are no additional plugins found by comparing via SHOW PLUGINS, however the release notes reference the previously enterprise feature of Thread Pool Plugin now in MySQL Community Server. There are no installed components by default in the docker mode for either version.
Thread Pool
The use of the Thread Pool plugin requires a MySQL configuration modification for the mysqld process, which requires a restart.
$ OUTPUT=$(docker run -d --name ${CONTAINER_NAME} \
--platform linux/amd64 \
-e MYSQL_ROOT_PASSWORD=${MYSQL_PASSWD} \
${REGISTRY_NAME} \
--plugin-load-add=thread_pool.so)
Thread Pool Logs
Following the installation instructions for the Thread Pool
for MySQL Enterprise you can see this plugin in 26.7.
$ docker logs ${CONTAINER_NAME}
...
2026-07-22T06:58:28.845787Z 0 [System] [MY-013852] [Server] Thread pool plugin started successfully with parameters: thread_pool_size = 1, thread_pool_algorithm = High Concurrency Algorithm, thread_pool_stall_limit = 6, thread_pool_prio_kickup_timer = 1000, thread_pool_max_unused_threads = 32, thread_pool_max_active_query_threads = 0, thread_pool_dedicated_listeners = 0, thread_pool_max_transactions_limit = 32, thread_pool_transaction_delay = 0, thread_pool_query_threads_per_group = 2, thread_pool_connection_report_interval = 120, thread_pool_longrun_trx_limit = 2000 ; 2000
Thread Pool Plugins
There are now 4 additional plugins in 26.7 with the thread pool plugin enabled.
mysql> SHOW PLUGINS;
+----------------------------------+----------+--------------------+----------------+-------------+
| Name | Status | Type | Library | License |
+----------------------------------+----------+--------------------+----------------+-------------+
...
| thread_pool | ACTIVE | DAEMON | thread_pool.so | PROPRIETARY |
| TP_THREAD_STATE | ACTIVE | INFORMATION SCHEMA | thread_pool.so | PROPRIETARY |
| TP_THREAD_GROUP_STATE | ACTIVE | INFORMATION SCHEMA | thread_pool.so | PROPRIETARY |
| TP_THREAD_GROUP_STATS | ACTIVE | INFORMATION SCHEMA | thread_pool.so | PROPRIETARY |
+----------------------------------+----------+--------------------+----------------+-------------+
50 rows in set (0.023 sec)
Thread Pool Tables
Note, the Enterprise 9.7 documentation lists only 3 matching tables, tp_connections appears to be new.
mysql> SELECT TABLE_NAME
-> FROM INFORMATION_SCHEMA.TABLES
-> WHERE TABLE_SCHEMA = 'performance_schema'
-> AND TABLE_NAME LIKE 'tp%';
+-----------------------+
| TABLE_NAME |
+-----------------------+
| tp_connections |
| tp_thread_group_state |
| tp_thread_group_stats |
| tp_thread_state |
+-----------------------+
4 rows in set (0.075 sec)
Conclusion
This is a quick validation I can install and validate a running MySQL 26.7 sandbox. I will be following up in future posts with additional findings.
Planet for the MySQL Community