https://lh4.googleusercontent.com/vD-dRHvXKOGoUhzenRC4PFEy0rKu-ajEi-SsFgYkEljZYRsGrQ15J4ly4lzFRKw_9boxt6uFGyp_mD83azXJg_0frzBn9HaYOR8SxTrzNzWXg8opxtV248AfyaBWXh-R9WZ0P0o0
When we browse through a webpage, we see some blue text with an underline underneath. These are called anchor texts. That’s because when you click on these texts, they take you to a new webpage.
The anchor tags, or the <a> tags of HTML, are used to create anchor texts, and the URL of the webpage that is to be opened is specified in the href attribute.
Refer to the below image to understand it better.

In almost all web scraping projects, fetching the URLs from the href attribute is a common task.
In today’s article, let’s learn different ways of fetching the URL from the href attribute using Beautiful Soup.
To fetch the URL, we have to first find all the anchor tags, or hrefs, on the webpage. Then fetch the value of the href attribute.
Two ways to find all the anchor tags or href entries on the webpage are:
soup.find_all()SoupStrainerclass
Once all the href entries are found, we fetch the values using one of the following methods:
tag['href']tag.get('href')
Prerequisite: Install and Import requests and BeautifulSoup
Throughout the article, we will use the requests module to access the webpage and BeautifulSoup for parsing and pulling the data from the HTML file.
To install requests on your system, open your terminal window and enter the below command:
pip install requests
More information here:
To install Beautiful Soup in your system, open your terminal window and enter the below command:
pip install bs4
To install Beautiful Soup, open the terminal window and enter the below command:
import requests from bs4 import BeautifulSoup
More information here:
Find the href entries from a webpage
The href entries are always present within the anchor tag (<a> tag). So, the first task is to find all the <a> tags within the webpage.
Using soup.find_all()
Soup represents the parsed file. The method soup.find_all() gives back all the tags and strings that match the criteria.
Let’s say we want to find all the <a> tags in a document. We can do as shown below.
import requests
from bs4 import BeautifulSoup
url = "https://www.wikipedia.org/"
# retrieve the data from URL
response = requests.get(url)
# parse the contents of the webpage
soup = BeautifulSoup(response.text, 'html.parser')
# filter all the <a> tags from the parsed document
for tag in soup.find_all('a'):
print(tag)
Output:
<a class="link-box" data-slogan="The Free Encyclopedia" href="//en.wikipedia.org/" id="js-link-box-en" title="English â Wikipedia â The Free Encyclopedia"> <strong>English</strong> <small><bdi dir="ltr">6 383 000+</bdi> <span>articles</span></small> </a> . . . <a href="https://creativecommons.org/licenses/by-sa/3.0/">Creative Commons Attribution-ShareAlike License</a> <a href="https://meta.wikimedia.org/wiki/Terms_of_use">Terms of Use</a> <a href="https://meta.wikimedia.org/wiki/Privacy_policy">Privacy Policy</a>
Using SoupStrainer class
We can also use the SoupStrainer class. To use it, we have to first import it into the program using the below command.
from bs4 import SoupStrainer
Now, you can opt to parse only the required attributes using the SoupStrainer class as shown below.
import requests
from bs4 import BeautifulSoup, SoupStrainer
url = "https://www.wikipedia.org/"
# retrieve the data from URL
response = requests.get(url)
# parse-only the <a> tags from the webpage
soup = BeautifulSoup(response.text, 'html.parser', parse_only=SoupStrainer("a"))
for tag in soup:
print(tag)
Output:
<a class="link-box" data-slogan="The Free Encyclopedia" href="//en.wikipedia.org/" id="js-link-box-en" title="English â Wikipedia â The Free Encyclopedia"> <strong>English</strong> <small><bdi dir="ltr">6 383 000+</bdi> <span>articles</span></small> </a> . . . <a href="https://creativecommons.org/licenses/by-sa/3.0/">Creative Commons Attribution-ShareAlike License</a> <a href="https://meta.wikimedia.org/wiki/Terms_of_use">Terms of Use</a> <a href="https://meta.wikimedia.org/wiki/Privacy_policy">Privacy Policy</a>
Fetch the value of href attribute
Once we have fetched the required tags, we can retrieve the value of the href attribute.
All the attributes and their values are stored in the form of a dictionary. Refer to the below:
sample_string="""<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>"""
soup= BeautifulSoup(sample_string,'html.parser')
atag=soup.find_all('a')[0]
print(atag)
print(atag.attrs)
Output:
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
{'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}
Using tag[‘href’]
As seen in the output, the attributes and their values are stored in the form of a dictionary.
To access the value of the href attribute, just say
tag_name['href']
Now, let’s tweak the above program to print the href values.
sample_string="""<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>"""
soup= BeautifulSoup(sample_string,'html.parser')
atag=soup.find_all('a')[0]
print(atag['href'])
Output:
http://example.com/elsie
Using tag.get(‘href’)
Alternatively, we can also use the get() method on the dictionary object to retrieve the value of ‘href’ as shown below.
sample_string = """<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>"""
soup = BeautifulSoup(sample_string,'html.parser')
atag = soup.find_all('a')[0]
print(atag.get('href'))
Output:
http://example.com/elsie
Real-Time Examples
Now that we know how to fetch the value of the href attribute, let’s look at some of the real-time use cases.
Example 1: Fetch all the URLs from the webpage.
Let’s scrape the Wikipedia main page to find all the href entries.
from bs4 import BeautifulSoup
import requests
url = "https://www.wikipedia.org/"
# retrieve the data from URL
response = requests.get(url)
if response.status_code ==200:
soup=BeautifulSoup(response.text, 'html.parser')
for tag in soup.find_all(href=True):
print(tag['href'])
Output:
//cu.wikipedia.org/ //ss.wikipedia.org/ //din.wikipedia.org/ //chr.wikipedia.org/ . . . . //www.wikisource.org/ //species.wikimedia.org/ //meta.wikimedia.org/ https://creativecommons.org/licenses/by-sa/3.0/ https://meta.wikimedia.org/wiki/Terms_of_use https://meta.wikimedia.org/wiki/Privacy_policy
As you can see, all the href entries are printed.
Example 2: Fetch all URLs based on some condition
Let’s say we need to find only the outbound links. From the output, we can notice that most of the inbound links do not have "https://" in the link.
Thus, we can use the regular expression ("^https://") to match the URLs that start with "https://" as shown below.
Also, check to ensure nothing with ‘wikipedia’ in the domain is in the result.
from bs4 import BeautifulSoup
import requests
import re
url = "https://www.wikipedia.org/"
# retrieve the data from URL
response = requests.get(url)
if response.status_code ==200:
soup=BeautifulSoup(response.text, 'html.parser')
for tag in soup.find_all(href=re.compile("^https://")):
if 'wikipedia' in tag['href']:
continue
else:
print(tag['href'])
Output:
https://meta.wikimedia.org/wiki/Special:MyLanguage/List_of_Wikipedias https://donate.wikimedia.org/?utm_medium=portal&utm_campaign=portalFooter&utm_source=portalFooter . . . https://meta.wikimedia.org/wiki/Terms_of_use https://meta.wikimedia.org/wiki/Privacy_policy
Example 3: Fetch the URLs based on the value of different attributes
Consider a file as shown below:
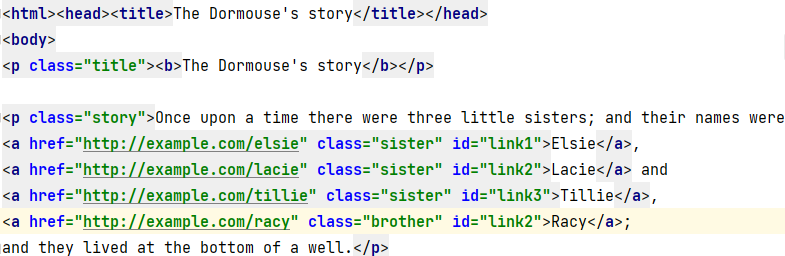
Let’s say we need to fetch the URL from the class=sister and with id=link2. We can do that by specifying the condition as shown below.
from bs4 import BeautifulSoup
#open the html file.
with open("sample.html") as f:
#parse the contents of the html file
soup=BeautifulSoup(f,'html.parser')
# find the tags with matching criteria
for tag in soup.find_all('a',{'href': True, 'class' : 'sister' ,'id' : 'link2' }):
print(tag['href'])
Output:
http://example.com/lacie
Conclusion
That brings us to the end of this tutorial. In this short tutorial, we have learned how to fetch the value of the href attribute within the HTML <a> tag. We hope this article has been informative. Thanks for reading.
Finxter