https://media.notthebee.com/articles/6420172e0beb96420172e0beba.jpg
Watch til the end…
Not the Bee
Just another WordPress site
https://media.notthebee.com/articles/6420172e0beb96420172e0beba.jpg
Watch til the end…
Not the Bee
https://photos5.appleinsider.com/gallery/53110-106413-hard-drive-illustration-xl.jpg
Modern Mac storage uses chips, but we still think of spinning disks when it comes to drives. [Unsplash/Patrick Lindenberg]

AppleInsider may earn an affiliate commission on purchases made through links on our site.
If you’re feeling the pinch of limited storage capacity on your Mac, these disk space analyzer apps could help you see how it has been consumed, and potentially free some space up too.
There are numerous macOS apps that allow you to peek into the contents of your Mac’s storage devices. Disk space analyzer apps let you inspect the storage devices connected to your Mac, and take a look at what they contain.
Some of these utilities are simple viewers, which display drive contents as pie charts, graphics, or maps. Others allow you to clean and move files off your devices when they’re no longer needed.
There are several disk scanner utilities for macOS that can grant you to gain quick insight into your drives – far too many to cover here. The most popular disk viewers for macOS include:
Some also provide cleanup/removal abilities.
Only two of the above apps don’t yet have native Apple Silicon binary support: Disk Diag and Disk Analyzer Pro. However, note that in many cases Intel apps running in Apple’s Rosetta 2 emulation layer on M1 and M2 Macs have better performance than if they run natively on Intel Macs.
As usual, you can check for native Apple Silicon versions of any app by selecting it in the Finder and pressing Command-I (Get Info) on the keyboard.
Disk Xray by Naarak Studio is a simple disk space analyzer and cleaner which can also find duplicate files. The streamlined interface consists of a Scanner window with buttons for scanning, duplicates, and cleanup.
To scan, you first click the small folder button at the top of the window to select a folder or an entire disk volume to scan, then click the Play button. Disk Xray is incredibly fast – scanning large volumes in under a second or two.
Once the scan completes, volume or folder contents are displayed at the bottom of the window, broken down by total, general file types, and subfolders.
Displayed data shows the size of each item, and how much of the total volume space it occupies by percentage. For folders, the number of subitems is also displayed.
Clicking one of the small buttons on the left allows you to delete, open, inspect, and get info on each item. Clicking Delete provides a warning, and if you confirm it, the item or items are deleted from the volume.
The only downside to Disk Xray is that you must rescan for each of the three options: scanning, duplicates, and cleanup. But this is a minor annoyance and the app’s speed more than makes up for the inconvenience.
Disk Xray costs $15, with a 14-day free trial available to try it out.
DaisyDisk by Software Ambience Corp is one of the oldest and best disk space analyzers for macOS.
On startup, a list of attached volumes is displayed in a single window. Clicking “Scan” starts scanning a volume, and when the scan is done, a detailed graph showing disk space usage is displayed.
On the right is a list of folders on the volume, and across the top, the current folder’s path on disk. Clicking an item on the right dives into that folder, updating the graph with fluid animation.
You can select any item on the right and drag it to the Collector at the bottom, removing it from the list.
Once you’ve collected all items you wish to remove, clicking the Delete button starts a countdown – giving you time to cancel if you wish. If you don’t cancel, the collected items are deleted from the volume.
This tool is inexpensive and a joy to use – a must-have for your desktop.
DaisyDisk costs $10, but is available with a free trial.
GrandPerspective from Eriban Software is a unique and simple volume treemap generator.
The generator shows every file on a volume in a single window containing blocks representing each file or folder. File sizes are indicated by the size of each block in the diagram – with larger blocks indicating larger items.
Using the toolbar along the top, or by right-clicking, you can zoom in and out, delete, open, Quick Look, and reveal items’ locations in the Finder. You can also copy an item’s full path on the disk.
There’s also a Get Info window that allows you to show .pkg contents in the map. The same window lets you change its colors, though some of the pallets are a bit garish.
OmniDiskSweeperfrom The OMNI Group is almost as old as the Mac itself and is a disk space analyzer that displays a volume’s items in descending size order for easy removal of large files and folders.
On launch, OmniDiskSweeper displays a simple list of attached volumes, and disk space info for each. Selecting a volume and clicking “Sweep Selected Drive” displays items on that volume in a NeXT-style file browser window.
You can select and view subfolders, including contents of macOS app and .pkg bundles and their contents. You can delete any part of any folder or bundle on the disk by selecting items, and clicking the Trash button.
OmniDiskSweeper may seem a bit simplistic, but keep in mind it’s free, and it was created back when the Mac and its OS and filesystem were much smaller and simpler.
OMNI Group has probably kept it around for historical reasons. There are also older versions available for all versions of macOS back to 10.4 Tiger.
OmniDiskSweeper is free to download, though it’s not the only software the developer produces.
They also make a mean Gantt chart project management app called OMNIPlan ($199, $399 Pro, $20/mo subscription, 14-day free trial).
Disk Drill by CleverFiles for macOS, iOS, and Android is a disk space analyzer that allows you to scan devices and volumes, and view and remove files and folders. You can also search for deleted files and folders, attempt recovery of lost partitions, and use a host of other features.
Due to lack of disclosure by Apple, Disk Drill can’t run all features on APFS volumes, but it supports macOS Extended (HFS), and Windows FAT32 and NTFS volume formats.
With Disk Drill you can scan both devices and volumes, including RAID devices. There are also S.M.A.R.T monitoring tools, data protection, bit-level backups, trash recovery, a cleaner, duplicate finder, data shredder, free space eraser, and macOS boot drive creator.
The UI is simple enough – with a window displaying each connected device and all its partitions. You can run most operations at both the device and volume level, and there are quick and deep scan levels which trade-off scan speed for completeness.
For a limited time, if you buy the Mac version of Disk Drill, you get the Windows version free.
Disk Diag from Rocky Sand Studios is a disk space analyzer and cleaner app with features for finding large files, scanning and removing unused System, User, Developer, duplicate files, and unused applications.
There’s a simple OneClick mode and more advanced modes that allow you to view and remove individual files, folders, and apps.
There’s also a feature to scan for unused .dmg disk image files and an overall summary dashboard view. The dashboard view also displays current memory and CPU usage.
Disk Diag also adds a macOS menubar option for quick access, which you can disable.
Disk Space Analyzer from Nektony is a full-featured and aptly named disk space analyzer that also uses sunburst graphs similar to DaisyDisk to display disk storage and contents.
Features include scanning, display, large and unused file search and removal, and copying/moving features.
Nektony also offers a simple macOS menubar product called Funter (free), which allows you to view and clean up both your drives and your Mac’s memory.
Disk Space Analyzer costs $5 per month or $10 per year, and is also offered with a free trial.
Disk Analyzer Pro from Systweak Software is a full-featured disk space analyzer and scanner with a dashboard interface. A simple pie chart with a legend shows disk usage and occupancy by file type/size.
It allows you to search a volume for files and folders by size and type, and to move, delete, and compress files with the single click of a toolbar button.
You can also view all files of a given type instantly in a new window simply by double-clicking on its category in the pie chart legend – a very cool feature.
Additional features include scanning/viewing by subfolders, and the ability to view both the top 100 files by size and date.
Disk Analyzer Pro costs $10 from the Mac App Store.
There’s also a Windows version available.
An easy way to view disk usage in macOS is to select “About this Mac” from the Apple menu in the Finder. This opens a device info window for the Mac.
If you then click the More Info” button, you’ll be taken to the System Settings->General->About pane, which has a “Storage” section at the bottom.
Clicking the “Storage Settings” button takes you to an overview pane that shows disk usage for both the internal drive and each category of files stored on your Mac.
If you click the “All Volumes” button, a list of all attached disk volumes, their capacities, and usage graphs are displayed.
Using any of these apps will help you monitor your storage devices, better understand what’s on them, and make it easier to increase free space by removing unwanted and unused files and apps from your drives.
However, depending on your preferences, you may want to try out a third-party disk space analyzer that can provide more granular data for you to use.
AppleInsider News
https://repository-images.githubusercontent.com/603931433/db3698eb-9e1d-4bfd-a369-4050628b5cc1
![]()
![]()
Note if you are front-end developer and what to make queries in an API that uses this package head to queries section
Laravel Purity is an elegant and efficient filtering and sorting package for Laravel, designed to simplify complex data filtering and sorting logic for eloquent queries. By simply adding filter() to your Eloquent query, you can add the ability for frontend users to apply filters based on url query string parameters like a breeze.
Features :
Laravel Purity is not only developer-friendly but also front-end developer-friendly. Frontend developers can effortlessly use filtering and sorting of the APIs by using the popular JavaScript qs package.
The way this package handles filters is inspired by strapi’s filter and sort functionality.

Install the package via composer by this command:
composer require abbasudo/laravel-purity
Get configs (configs/purity.php) file to customize package’s behavior by this command:
php artisan vendor:publish --tag=purity
Add Filterable trait to your model to get filters functionalities.
use Abbasudo\Purity\Traits\Filterable;
class Post extends Model
{
use Filterable;
//
}
Now add filter() to your model eloquent query in the controller.
use App\Models\Post;
class PostController extends Controller
{
public function index()
{
return Post::filter()->get();
}
}
By default, it gives access to all filters available. here is the list of available filters. if you want to explicitly specify which filters to use in this call head to restrict filters section.
Add Sortable trait to your model to get sorts functionalities.
use Abbasudo\Purity\Traits\Sortable;
class Post extends Model
{
use Sortable;
//
}
Now add sort() to your eloquent query in the controller.
use App\Models\Post;
class PostController extends Controller
{
public function index()
{
return Post::sort()->get();
}
}
Now sort can be applied as instructed in sort usage.
The system validates allowed filters in the following order of priority:
filter() function.Post::filter('$eq', '$in')->get();
// or
Post::filter(EqualFilter::class, InFilter::class)->get();
$filters variable in the model.Note applied only if no parameters passed to
filter()function.
// App\Models\Post
private array $filters = [
'$eq',
'$in',
];
// or
private array $filters = [
EqualFilter::class,
InFilter::class,
];
filters configuration in the configs/purity.php file.Note applied only if above parameters are not set.
// configs/purity.php
'filters' => [
EqualFilter::class,
InFilter::class,
],
Create custom filter class by this command:
php artisan make:filter EqualFilter
this will generate a filter class in Filters directory. by default all classes defined in Filters directory are loaded into the package. you can change scan folder location in purity config file.
// configs/purity.php
'custom_filters_location' => app_path('Filters'),
By default, purity silences it own exceptions (not sql exceptions). to change that behavior change silent index to false in config file.
// configs/purity.php
'silent' => false,
This section is a guide for front-end developers who want to use an API that uses Laravel Purity.
Queries can accept a filters’ parameter with the following syntax:
GET /api/posts?filters[field][operator]=value
By Default the following operators are available:
| Operator | Description |
|---|---|
$eq |
Equal |
$eqc |
Equal (case-sensitive) |
$ne |
Not equal |
$lt |
Less than |
$lte |
Less than or equal to |
$gt |
Greater than |
$gte |
Greater than or equal to |
$in |
Included in an array |
$notIn |
Not included in an array |
$contains |
Contains |
$notContains |
Does not contain |
$containsc |
Contains (case-sensitive) |
$notContainsc |
Does not contain (case-sensitive) |
$null |
Is null |
$notNull |
Is not null |
$between |
Is between |
$startsWith |
Starts with |
$startsWithc |
Starts with (case-sensitive) |
$endsWith |
Ends with |
$endsWithc |
Ends with (case-sensitive) |
$or |
Joins the filters in an “or” expression |
$and |
Joins the filters in an “and” expression |
Tip in javascript use qs directly to generate complex queries instead of creating them manually. Examples in this documentation showcase how you can use
qs.
Find users having ‘John’ as first name
GET /api/users?filters[name][$eq]=John
const qs = require('qs');
const query = qs.stringify({
filters: {
username: {
$eq: 'John',
},
},
}, {
encodeValuesOnly: true, // prettify URL
});
await request(`/api/users?${query}`);
Find multiple restaurants with ids 3, 6, 8
GET /api/restaurants?filters[id][$in][0]=3&filters[id][$in][1]=6&filters[id][$in][2]=8
const qs = require('qs');
const query = qs.stringify({
filters: {
id: {
$in: [3, 6, 8],
},
},
}, {
encodeValuesOnly: true, // prettify URL
});
await request(`/api/restaurants?${query}`);
Complex filtering is combining multiple filters using advanced methods such as combining $and & $or. This allows for more flexibility to request exactly the data needed.
Find books with 2 possible dates and a specific author.
GET /api/books?filters[$or][0][date][$eq]=2020-01-01&filters[$or][1][date][$eq]=2020-01-02&filters[author][name][$eq]=Kai%20doe
const qs = require('qs');
const query = qs.stringify({
filters: {
$or: [
{
date: {
$eq: '2020-01-01',
},
},
{
date: {
$eq: '2020-01-02',
},
},
],
author: {
name: {
$eq: 'Kai doe',
},
},
},
}, {
encodeValuesOnly: true, // prettify URL
});
await request(`/api/books?${query}`);
Deep filtering is filtering on a relation’s fields.
Find restaurants owned by a chef who belongs to a 5-star restaurant
GET /api/restaurants?filters[chef][restaurants][stars][$eq]=5
const qs = require('qs');
const query = qs.stringify({
filters: {
chef: {
restaurants: {
stars: {
$eq: 5,
},
},
},
},
}, {
encodeValuesOnly: true, // prettify URL
});
await request(`/api/restaurants?${query}`);
Queries can accept a sort parameter that allows sorting on one or multiple fields with the following syntax’s:
GET /api/:pluralApiId?sort=value to sort on 1 field
GET /api/:pluralApiId?sort[0]=value1&sort[1]=value2 to sort on multiple fields (e.g. on 2 fields)
The sorting order can be defined with:
:asc for ascending order (default order, can be omitted):desc for descending order.Sort using 2 fields
GET /api/articles?sort[0]=title&sort[1]=slug
const qs = require('qs');
const query = qs.stringify({
sort: ['title', 'slug'],
}, {
encodeValuesOnly: true, // prettify URL
});
await request(`/api/articles?${query}`);
Sort using 2 fields and set the order
GET /api/articles?sort[0]=title%3Aasc&sort[1]=slug%3Adesc
const qs = require('qs');
const query = qs.stringify({
sort: ['title:asc', 'slug:desc'],
}, {
encodeValuesOnly: true, // prettify URL
});
await request(`/api/articles?${query}`);
Laravel Purity is Licensed under The MIT License (MIT). Please see License File for more information.
Laravel News Links
https://twtv3.ams3.digitaloceanspaces.com/subdomain-routes-laravel.jpg
Also Read: Structure Laravel App for DDD
Also Read: Routes in Laravel for DDD
If you need to access your routes based on subdomains like product.thewebtier.com/products. To achieve this, you need to modify your route definitions in Laravel and configure web server to handle subdomains.
First, update your route definitions to use subdomain-based routing in the app/Domain/Product/routes/web.php or app/Domain/Product/routes/api.php file.
Also Read: Create own PHP Router
For example, in app/Domain/Product/routes/web.php:
<?php
use App\Domain\Product\Controllers\ProductController;
use Illuminate\Support\Facades\Route;
Route::domain('product.thewebtier.com')->group(function () {
Route::get('/products', [ProductController::class, 'index'])->name('products.index');
// Add other product routes here
});Similarly, you can define routes for other domains in their respective route files.
You need to configure your web server (e.g., Apache or Nginx) to handle subdomains and point them to your Laravel application.
Following example code will work for Nginx configuration for setting up subdomain routing for Laravel application in DDD.
server {
listen 80;
server_name product.thewebtier.com;
root /path/to/laravel/public;
index index.php index.html index.htm;
location / {
try_files $uri $uri/ /index.php?$query_string;
}
location ~ \.php$ {
include snippets/fastcgi-php.conf;
fastcgi_pass unix:/run/php/php7.4-fpm.sock;
}
location ~ /\.ht {
deny all;
}
}For Apache, create or modify the virtual host configuration:
<VirtualHost *:80>
ServerName product.thewebtier.com
DocumentRoot /path/to/laravel/public
<Directory /path/to/laravel/public>
AllowOverride All
Require all granted
</Directory>
</VirtualHost>Make sure to replace /path/to/laravel with the actual path to your Laravel application.
Add a DNS record (A or CNAME) for the subdomain (product.thewebtier.com) and point it to your server’s IP address or domain.
Also Read: MySQL backups in Laravel
After completing these steps, you should be able to access your routes using the subdomain-based URL, like product.thewebtier.com/products.
Laravel News Links
https://laravelnews.s3.amazonaws.com/images/modelling-business-processes-in-laravel.png
As developers, we often map business processes to digital processes, from sending an email to something quite complex. Let’s look at how to take a more complicated process and write clean and elegant code.
It all starts with a workflow. I tweeted about writing this tutorial to see if there would be any feedback on business processes people would find helpful – I only really got one response, though.
So with that in mind, let’s look at the Order/Shipping process, something with enough moving parts to get the idea across – but I won’t go into too much detail from a domain logic perspective.
Imagine you run an online merch store, have an online shop, and use a dropshipping service to send merch out on demand when an order is placed. We need to think about what the business process might look like without any digital help – this allows us to understand the business and its needs.
An item is requested (we are using a print-on-demand service, so stock isn’t an issue).
We take the customers’ details.
We create an order for this new customer.
We accept payment for this order.
We confirm the order and payment to the customer.
We then place our order with the print-on-demand service.
The print-on-demand service will periodically update us on the order status, which we can update our customers, but this would be a different business process. Let’s look at the order process first and imagine this was all done inline in one controller. It would get quite complicated to manage or change.
class PlaceOrderController
{
public function __invoke(PlaceOrderRequest $request): RedirectResponse
{
// Create our customer record.
$customer = Customer::query()->create([]);
// Create an order for our customer.
$order = $customer->orders()->create([]);
try {
// Use a payment library to take payment.
$payment = Stripe::charge($customer)->for($order);
} catch (Throwable $exception) {
// Handle the exception to let the customer know payment failed.
}
// Confirm the order and payment with the customer.
Mail::to($customer->email)->send(new OrderProcessed($customer, $order, $payment));
// Send the order to the Print-On-Demand service
MerchStore::create($order)->for($customer);
Session::put('status', 'Your order has been placed.');
return redirect()->back();
}
}
So if we walk through this code, we see that we create a user and order – then accept the payment and send an email. Finally, we add a status message to the session and redirect the customer.
So we write to the database twice, talk to the payment API, send an email, and finally, write to the session and redirect. It is quite a lot in one synchronous thread to handle, with a lot of potential for things to break. The logical step here is to move this to a background job so that we have a level of fault tolerance.
class PlaceOrderController
{
public function __invoke(PlaceOrderRequest $request): RedirectResponse
{
// Create our customer record.
$customer = Customer::query()->create([]);
dispatch(new PlaceOrder($customer, $request));
Session::put('status', 'Your order is being processed.');
return redirect()->back();
}
}
We have cleaned up our controller a lot – however, all we have done is move the problem to a background process. While moving this to a background process is the right way to handle this, we need to approach this a lot differently.
Firstly, we want to first or create the customer – in case they have made an order before.
class PlaceOrderController
{
public function __invoke(PlaceOrderRequest $request): RedirectResponse
{
// Create our customer record.
$customer = Customer::query()->firstOrCreate([], []);
dispatch(new PlaceOrder($customer, $request));
Session::put('status', 'Your order is being processed.');
return redirect()->back();
}
}
Our next step is to move the creation of a customer to a shared class – this is one of many times we would want to create or get a customer record.
class PlaceOrderController
{
public function __construct(
private readonly FirstOrCreateCustomer $action,
) {}
public function __invoke(PlaceOrderRequest $request): RedirectResponse
{
// Create our customer record.
$customer = $this->action->handle([]);
dispatch(new PlaceOrder($customer, $request));
Session::put('status', 'Your order is being processed.');
return redirect()->back();
}
}
Let’s look at the background process code if we moved it directly there.
class PlaceOrder implements ShouldQueue
{
use Dispatchable;
use InteractsWithQueue;
use Queueable;
use SerializesModels;
public function _construct(
public readonly Customer $customer,
public readonly Request $request,
) {}
public function handle(): void
{
// Create an order for our customer.
$order = $this->customer->orders()->create([]);
try {
// Use a payment library to take payment.
$payment = Stripe::charge($this->customer)->for($order);
} catch (Throwable $exception) {
// Handle the exception to let the customer know payment failed.
}
// Confirm the order and payment with the customer.
Mail::to($this->customer->email)
->send(new OrderProcessed($this->customer, $order, $payment));
// Send the order to the Print-On-Demand service
MerchStore::create($order)->for($this->customer);
}
}
Not too bad, but – what if a step fails and we retry the job? We will end up redoing parts of this process again and again when not needed. We should first look to create the order within a database transaction.
class CreateOrderForCustomer
{
public function handle(Customer $customer, data $payload): Model
{
return DB::transaction(
callback: static fn () => $customer->orders()->create(
attributes: $payload,
),
);
}
}
Now we can update our background process to implement this new command.
class PlaceOrder implements ShouldQueue
{
use Dispatchable;
use InteractsWithQueue;
use Queueable;
use SerializesModels;
public function _construct(
public readonly Customer $customer,
public readonly Request $request,
) {}
public function handle(CreateOrderForCustomer $command): void
{
// Create an order for our customer.
$order = $command->handle(
customer: $customer,
payload: $this->request->only([]),
);
try {
// Use a payment library to take payment.
$payment = Stripe::charge($this->customer)->for($order);
} catch (Throwable $exception) {
// Handle the exception to let the customer know payment failed.
}
// Confirm the order and payment with the customer.
Mail::to($this->customer->email)
->send(new OrderProcessed($this->customer, $order, $payment));
// Send the order to the Print-On-Demand service
MerchStore::create($order)->for($this->customer);
}
}
This approach works well. However, it isn’t ideal, and you do not have much visibility at any point. We could model this differently so that we are modeling our business process instead of splitting it out into parts.
It all starts with the Pipeline facade, enabling us to build this process correctly. We will still want to create our customer in the controller, but we will handle the rest of the process within the background job using a business process.
To begin with, we will need an abstract class that our business process classes can extend to minimize code duplication.
abstract class AbstractProcess
{
public array $tasks;
public function handle(object $payload): mixed
{
return Pipeline::send(
passable: $payload,
)->through(
pipes: $this->tasks,
)->thenReturn();
}
}
Our business process class will have many associated tasks, which we declare in the implementation. Then our abstract process will take the passed-on payload and send it through these tasks – eventually returning. Unfortunately, I can’t think of a nice way to return an actual type instead of mixed, but sometimes we have to compromise…
class PlaceNewOrderForCustomer extends AbstractProcess
{
public array $tasks = [
CreateNewOrderRecord::class,
ChargeCustomerForOrder::class,
SendConfirmationEmail::class,
SendOrderToStore::class,
];
}
As you can see, this is super clean to look at and works well. These tasks can be reused in other business processes where it makes sense.
class PlaceOrder implements ShouldQueue
{
use Dispatchable;
use InteractsWithQueue;
use Queueable;
use SerializesModels;
public function _construct(
public readonly Customer $customer,
public readonly Request $request,
) {}
public function handle(PlaceNewOrderForCustomer $process): void
{
try {
$process->handle(
payload: new NewOrderForCustomer(
customer: $this->customer->getKey(),
orderPayload: $this->request->only([]),
),
);
} catch (Throwable $exception) {
// Handle the potential exceptions that could occur.
}
}
}
Our background process now tries to handle the business process, and if any exceptions happen, we can fail and retry the process later on. As Laravel will use its DI container to pass through what you need into the jobs handle method, we can pass our process class into this method and let Laravel resolve this for us.
class CreateNewOrderRecord
{
public function __invoke(object $payload, Closure $next): mixed
{
$payload->order = DB::transaction(
callable: static fn () => Order::query()->create(
attributes: [
$payload->orderPayload,
'customer_id' $payload->customer,
],
),
);
return $next($payload);
}
}
Our business process tasks are invokable classes that get passed the “traveller”, which is the payload we want to pass through, and a Closure which is the next task in the pipeline. This is similar to how the middleware functionality works in Laravel, where we can chain on as many as we need, and they are just sequentially called.
The payload we pass in can be a simple PHP object we can use to build as it goes through a pipeline, extending it at each step, allowing the next task in the pipeline to access any information it needs without running a database query.
Using this approach, we can break down our business processes that aren’t digital and make digital representations of them. Chaining them together in this way adds automation where we need it. It is quite a simple approach, really, but it is very powerful.
Have you found a nice way to handle business processes in Laravel? What did you do? Let us know on twitter!
Laravel News
https://2.img-dpreview.com/files/p/E~C213x0S3413x2560T1200x900~articles/5410838737/20230228-DSC01945_-_shipping_and_receiving.jpeg
 |
If you’ve ever bought a new lens, you know the joy of removing a beautiful, pristine optic from its box and attaching it to your camera for the first time. But have you ever wondered what it takes to design and build that lens? During a recent trip to Japan, we had the opportunity to go behind the scenes at Sigma’s lens factory in the city of Aizu to answer that question, and we’re going to walk you through how it’s done, step by step.
Most photographers are familiar with Sigma, but maybe not with its unique history. Sigma is a family-owned business founded in 1961 by Michihiro Yamaki. Mr. Yamaki was an engineer at a small optical company that made binoculars, cameras and video lenses. When the company went bankrupt, some of its suppliers, needing new clients, approached Mr. Yamaki about starting a new business, and Sigma was born.
Today, Sigma has over 1,700 employees, nine subsidiaries in eight countries, and annual sales of 42 billion yen (about $322 million).
 |
As Sigma’s current CEO, Kazuto Yamaki, explained in our recent interview, Sigma has a business philosophy of ‘small office, big factory.’ It has a minimal administrative, sales and marketing staff and prioritizes investment in engineering and manufacturing. This explains why about 75% of the employees at the company’s headquarters in Kawasaki, Japan, are engineers.
Sigma opened its current factory in Aizu, about 300km north of Tokyo in Fukushima Prefecture, in 1974 and it’s home to about 1,500 of Sigma’s employees – the majority of its workforce. The proximity means that Sigma teams can quickly meet in person to resolve problems when needed to solve engineering and manufacturing challenges. This is Sigma’s only factory, and all of its products are made here.
Above: Sigma’s factory in Aizu, Japan.
 |
Sigma’s factory covers almost 72,000 square meters of floor space (approximately 775,000 square feet) and produces 80,000 lenses and 2,000 cameras annually. It’s a vertically integrated factory, meaning that almost every aspect of manufacturing, including the individual parts that make up each lens – right down to the screws – are produced here.
From the company’s early days, Michihiro Yamaki believed that to make a good product, working with local people and businesses was essential. That approach continues to this day; all of Sigma’s suppliers are located in the northern part of Japan. Essentially, Sigma aims to do everything by itself and with local partners, an approach that paid off during the global pandemic. Unlike companies with complex global supply chains, Sigma was able to keep its factory in operation during that time.
With that background, let’s dive into how lenses are made.
Above: The Sigma’s Aizu factory in 1974 and today, with Mt. Bandai behind. (Image courtesy of Sigma)
 |
Since optics are the core of any lens, we’ll start with glass. Before diving into the manufacturing process, let’s talk about how Sigma establishes performance metrics for every lens it manufactures.
Each time a new lens is designed, a high-quality master copy is created which is used for benchmark testing; it establishes a baseline performance spec for each new interaction constructed. This baseline becomes the reference point for all Modulation Transfer Function (MTF) machines used throughout the lens manufacturing process, ensuring that each lens meets the design specification for resolution. Sigma designs and builds its own MTF machines in-house.
Testing of the master lens takes place on a Trioptic measurement machine, one of only a few of its type in Japan. It can measure the range between the minimum focusing distance and infinity for all of Sigma’s lenses and uses collimators up to 1000mm.
Most lens elements start as lens blanks, glass disks with a slight curve. Before any grinding occurs, lens blanks have an opaque, white appearance. Sigma uses lens blanks from Hoya to manufacture its lenses.
 |
The first step in the lens manufacturing process is to roughly grind out the curve of the lens. Each lens blank is attached to a plunger that guides it into a machine where the glass is ground to the correct curve for the lens. Since this part of the process is intended only to create the right shape for the lens, it still appears somewhat opaque when finished.
A second, more refined precision grinding step is then performed, which gives the lens its clear, smooth finish.
There are about 330 machines used in the glass manufacturing process at Sigma’s Aizu factory, and every few minutes a technician is checking one with a gauge to ensure that its curve is correct.
 |
After the lenses are ground, the third and final step is polishing. Lenses are set into a machine on polyurethane pads mounted in a mold that matches the final shape or curve of the lens. These grind the lens using a special polishing paste, typically cerium or zirconium oxide. The process usually takes two to ten minutes, depending on the size and type of the lens.
 |
Not all glass elements are ground. Aspherical optics are manufactured through glass molding using one of two processes, depending on their size. Smaller elements begin life as what looks like a bulbous glob of clear optical glass, while larger elements begin as pre-formed glass units.
In both cases, these pieces of glass are put into molds and pushed through a machine that presses them into their final shape using high pressure and heat. Sigma currently manufactures aspherical elements up to 84mm in diameter. Sigma also makes its own molds for manufacturing aspherical lenses, part of its philosophy of building its own tools in-house to maintain quality control.
Aspherical lens manufacturing is one of the better-guarded parts of the lens manufacturing process and something that makes lenses unique, so we were asked to refrain from taking photos in this area. Instead, I’ve included a picture above of one of my favorite Sigma lenses, the 14mm F1.8 Art, which features a front aspherical element that’s 80mm in diameter.
 |
After glass elements are formed and coated, they receive a final grinding around the edges to make sure the diameter and thickness of the edges of the elements are within specifications and will mount correctly inside the lens. This also ensures that the glass elements will be optically centered inside the lens housing.
 |
Once lenses are polished or molded, it’s time to apply Sigma’s Super Multi-Layer coatings, which suppress flare and ghosting. Before applying coatings, each lens is visually inspected for dust. The lens is then loaded onto a ‘planet,’ a dome-shaped device with inserts for specific lens elements.
The planets are then loaded into machines in which special chemicals have been evaporated into a chamber. The planet rotates inside the device, evenly spreading the vaporized chemicals onto the lens elements, before holding them to be cured by UV light.
 |
Once the individual optical elements are manufactured, those that get grouped in a lens go through a process called caulking and joining. Each element is placed into a plastic frame, and high heat and pressure are used to fix them into place, creating a single unit made of multiple lens elements.
A separate process called lens bonding (photo above) is used when two to three elements must be bonded directly with no space in between. The two lenses are joined with a special adhesive, and a machine ensures that both lenses are optically centered. The bonded lenses are then exposed to UV light to cure the adhesive.
 |
Now that we’ve covered glass, let’s move on to the rest of the manufacturing process, starting with metals. A lens has many metal parts, so metal processing covers a large part of the factory floor, producing components out of materials like steel, aluminum and brass.
The automated blue machines visible in the photo above carry out the process of cutting out, shaping and drilling holes in metal for a perfect fit. The process is quick, often taking only a few minutes per part. The factory runs about 160 of the machines you see in the photo.
 |
Although numerous parts are produced in this factory area, lens barrels and bayonet mounts are the most recognizable. This photo shows freshly milled inner rotation barrels for lenses before any surface treatment has been applied.
 |
The machining process that turns metal blocks into lens components produces metal waste, like the shavings in this photo. Sigma captures this material and works with a local recycling facility to ensure the materials are repurposed rather than landing in a landfill.
 |
Some metal parts are stamped out by machines rather than being machined individually. In this case, a strip of metal is fed through a pressing machine by what looks like a giant roll of metal tape.
 |
And here’s the final product you saw being stamped out on the previous page: metal plates that help control the movement of the aperture blades on a lens.
 |
For safety reasons, magnesium parts are machined in a separate building that isn’t connected to the main factory. Magnesium can be flammable, mainly when it’s in a fine shaving or powder form – precisely the forms you tend to produce when milling parts out of metal. As a result, this facility has extra thick concrete walls that offer protection in the event of an accident.
Magnesium is used for many components because it’s strong and durable yet lighter than aluminum. This allows parts to be smaller and lighter than if they were made from aluminum, but there’s a tradeoff: magnesium is more costly. As a result, it’s not used for everything, but only for parts where durability and light weight matter.
Magnesium components start as die-cast parts, one of the few items Sigma doesn’t produce in its factory. There are only a small number of suppliers for die-cast parts worldwide, and Sigma only sources die-cast from a limited number of suppliers in Japan. This photo shows a die-cast lens collar on the left and a fully machined version on the right.
 |
These automated machines cut out, shape and drill holes in the die-cast part with high precision. After milling, each piece goes through a cleaning process to remove oils left over from production, then receives a corrosion-resistant coating to protect the metal. Once milling is complete, each part is measured by a machine to make sure it’s within the specified tolerances for the part. In this photo, you can see a tripod collar mounted to a machine.
At any given time, there are about 20 machines milling parts from die-cast magnesium. For safety, each machine is equipped with specialized fire extinguishing equipment explicitly designed for magnesium fires.
 |
Sigma’s philosophy is to control as much of the manufacturing process as possible in its factory, as that allows them to better control the quality of everything it produces. This extends to the molds and tools used to manufacture its products.
This area isn’t automated. Prototypes and parts are handmade, as seen in the photo above. Hand-made parts become blanks and are used to create the injection molds used to manufacture many components. This is also where Sigma builds the specialized tools required to build a new product, typically with a focus on making the assembly process more efficient.
 |
Molds for plastic or pressed parts are made using a process called electronic discharge machining (EDM). This thermal process removes material by applying discharging sparks in the gap between an electrode and the part being manufactured.
Once on the assembly line, viscous plastic is fed into the mold through the center of the mold. A separate series of tubes delivers coolant to the mold, causing the plastic parts to harden. Around 40 injection molding machines are making parts on the assembly line at any given time, and molds will be rotated in and out of production depending on what products are being produced.
 |
Surface mounting refers to mounting electronics onto circuit boards for lenses. As with many things, Sigma manufactures circuit boards in-house. Baseboards are fed into one end of a machine where soldering paste is applied and heated to spread out the paste evenly. Components are then fed into the machine from rolls that look like tape and stamped onto the board.
 |
A 3D photo test of each board confirms that all the parts are in the correct positions, followed by an X-ray check. There are about 20 machines in the factory building circuit boards.
The board in this photo is a two-sided circuit board. One side has been printed and is now ready to feed back through the machine for surface mounting on the opposite side.
 |
Once metal parts like lens barrels have been milled, and any necessary surface coatings applied, it’s time for a paint job. Each part is mounted on a metal jig which spins in circles as the paint is sprayed on, ensuring an even coat of paint. These painted parts are then dried in ovens.
Some materials, like those made of aluminum, may receive a black anodized coating instead.
 |
Most of the reference markings on a lens, like scale windows and apertures, as well as labels on accessories like lens hoods, are printed or painted on. A technician applies the ‘Sigma’ logo to part of a lens barrel in this photo.
 |
Electroplating is used to apply a chrome surface to metal parts, which makes them more durable. The most recognizable parts to go through the electroplating process are the brass lens mounts for each lens, which are chrome-plated here. Some smaller metal parts are plated here as well.
 |
Once all lens elements are made and all parts have been manufactured, surface treated and painted, they meet at the final assembly line. In this clean room environment, each line is set up based on what models are in production on a given day. A single assembly line extends from the first set of parts to the final build.
Each lens’ alignment is performed using Sigma’s in-house designed and built MTF machines to adjust and confirm that they meet MTF specs. Although total assembly time varies by product, it can take as little as 30 minutes to assemble one lens, but it can certainly extend to longer periods for complex products.
After assembly, lenses are sent to the quality assurance division, which checks them using an MTF measuring machine. Additionally, they are inspected for dirt, surface scratches and other anomalies, and to confirm that zoom mechanisms, apertures and electronic contacts all work correctly. Some products may go through a resolution test at this stage as well.
 |
Products arrive in the packing and shipping area without serial numbers. Until a product receives a serial number, it’s like a person without an identity. Once a serial number is assigned, the lens learns where it will be shipped.
Finished products and accessories are matched together and boxed in retail packaging, then loaded into large cardboard shipping boxes based on their final destination.
 |
The final step before a product leaves the factory is to be placed into the finished product storage area. With over 60 lens models in production across multiple lens mounts, there are a lot of lenses in this room. Products don’t sit here long – Sigma’s factory is producing at capacity, and there’s a constant need to clear this space to make room for new products coming off the assembly line.
Trucks arrive in the evening to ship boxes off to Narita airport in Tokyo, where they will be sent to distributors or subsidiaries worldwide.
I’m pretty sure the Ark of the Covenant is hiding in here somewhere.
 |
In addition to manufacturing, the Aizu factory serves as a center for Sigma’s customer support services. Most items received for repair here are from Japan (most countries will have their own service centers). However, products from other regions may be sent here if they require specialized repair.
Once a product is checked in, it’s handed over to one of Sigma’s ace repair technicians, who will repair it to Sigma’s original specifications, ensuring that it does so using the projection room shown on the next slide.
 |
The projection room, located next to the customer support and service area, is used to test products before and after repair. On the opposite side of the room, there’s a reverse projector for testing Sigma’s cinema lenses.
Sigma’s standard practice is to test lenses on both the resolution chart and MTF machine to ensure that they meet Sigma’s product specs before returning them to customers.
Additionally, technicians will even go outside to take real-world before and after photos to check a lens depending on the nature of the repair, for example to check for flare.
 |
Of course, no visit to Sigma would be complete without a trip to the Sigma museum, where it’s possible to see cameras and lenses past and present. There’s a lot to see, including modern lenses, classic lenses, SA-mount lenses and even cameras, like Sigma’s SD10 DSLR or compact Merrill models.
Finding some of the lenses you used early in your photography career is a fun, nostalgic trip down memory lane.
Articles: Digital Photography Review (dpreview.com)
https://i.kinja-img.com/gawker-media/image/upload/c_fill,f_auto,fl_progressive,g_center,h_675,pg_1,q_80,w_1200/ce18459b349fd7d58666159ba9b2d0c4.jpg
It’s a mere eight days before Dungeons & Dragons: Honor Among Thieves hits theaters, a movie that by all accounts is quite fun if not particularly consequential. Seriously, I haven’t heard anybody bad-mouth the film since its first trailer was released back in July of 2022. So why does this final trailer seem so convinced that everyone thinks the movie is terrible?
The trailer is so bizarre that the choice to use /Film’s quote about how it contains “The most Chris Pine a Chris performance has been in a long time” is not the weirdest thing about it:
The trailer begins with “Forget everything you think you know… everyone is raving about Dungeons & Dragons!” Charitably, it reads like the announcer is certain everyone thinks the movie is going to be a huge pile of crap, but don’t listen to the haters! Except… there aren’t any? Seriously, the film’s gotten good critical reactions and looks—and has always looked—like a lot of fun! There’s a giant list of publications that have given the movie positive reviews right in the trailer! It’s weirdly defensive, trying to fight a problem that doesn’t seem to exist.
With that in mind, it sounds more like the announcer wants you to have some sort of amnesia before you go to watch the film when it premieres on March 31. “Forget everything you know! …also, unrelatedly, people seem to like Dungeons & Dragons: Honor Among Thieves. It’s Chris Pine-y as hell, guys. You like Chris Pine, right? Well, forget that you like Chris Pine, too! I demand it!”
Want more io9 news? Check out when to expect the latest Marvel, Star Wars, and Star Trek releases, what’s next for the DC Universe on film and TV, and everything you need to know about the future of Doctor Who.
Gizmodo
https://laravelnews.s3.amazonaws.com/images/mysql-for-devs.jpg
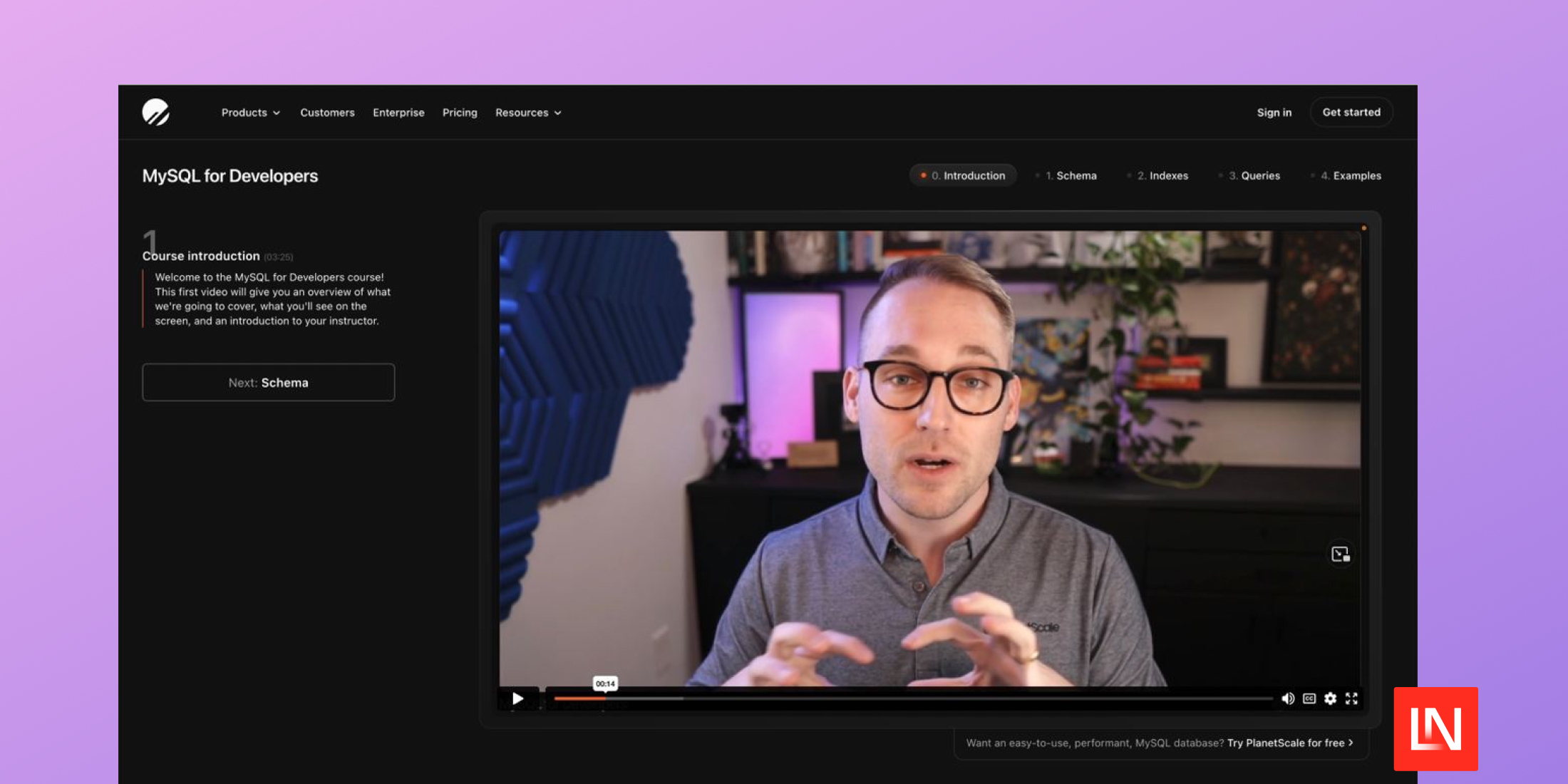
MySQL for Developers is a free course consisting of over 7 hours and 64 videos with everything a developer needs to know about MySQL.
The post MySQL for Developers Course is Live appeared first on Laravel News.
Join the Laravel Newsletter to get Laravel articles like this directly in your inbox.
Laravel News
https://www.percona.com/blog/wp-content/uploads/2023/03/lucas.speyer_an_underwater_high_tech_computer_server_a_dolpin_i_9337e5c5-e3c5-41dd-b0b1-e6504186488b-150×150.png
With a special focus on Percona Operator for MySQL
HAProxy, ProxySQL, MySQL Router (AKA MySQL Proxy); in the last few years, I had to answer multiple times on what proxy to use and in what scenario. When designing an architecture, many components need to be considered before deciding on the best solution.
When deciding what to pick, there are many things to consider, like where the proxy needs to be, if it “just” needs to redirect the connections, or if more features need to be in, like caching and filtering, or if it needs to be integrated with some MySQL embedded automation.
Given that, there never was a single straight answer. Instead, an analysis needs to be done. Only after a better understanding of the environment, the needs, and the evolution that the platform needs to achieve is it possible to decide what will be the better choice.
However, recently we have seen an increase in the usage of MySQL on Kubernetes, especially with the adoption of Percona Operator for MySQL. In this case, we have a quite well-defined scenario that can resemble the image below:

In this scenario, the proxies must sit inside Pods, balancing the incoming traffic from the Service LoadBalancer connecting with the active data nodes.
Their role is merely to be sure that any incoming connection is redirected to nodes that can serve them, which includes having a separation between Read/Write and Read Only traffic, a separation that can be achieved, at the service level, with automatic recognition or with two separate entry points.
In this scenario, it is also crucial to be efficient in resource utilization and scaling with frugality. In this context, features like filtering, firewalling, or caching are redundant and may consume resources that could be allocated to scaling. Those are also features that will work better outside the K8s/Operator cluster, given the closer to the application they are located, the better they will serve.
About that, we must always remember the concept that each K8s/Operator cluster needs to be seen as a single service, not as a real cluster. In short, each cluster is, in reality, a single database with high availability and other functionalities built in.
Anyhow, we are here to talk about Proxies. Once we have defined that we have one clear mandate in mind, we need to identify which product allows our K8s/Operator solution to:
To identify the above points, I have simulated a possible K8s/Operator environment, creating:
We will have very simple test cases. The first one has the scope to define the baseline, identifying the moment when we will have the first level of saturation due to the number of connections. In this case, we will increase the number of connections and keep a low number of operations.
The second test will define how well the increasing load is served inside the previously identified range.
For documentation, the sysbench commands are:
Test1
sysbench ./src/lua/windmills/oltp_read.lua --db-driver=mysql --tables=200 --table_size=1000000 --rand-type=zipfian --rand-zipfian-exp=0 --skip_trx=true --report-interval=1 --mysql-ignore-errors=all --mysql_storage_engine=innodb --auto_inc=off --histogram --stats_format=csv --db-ps-mode=disable --point-selects=50 --reconnect=10 --range-selects=true –rate=100 --threads=<#Threads from 2 to 4096> --time=1200 run
Test2
sysbench ./src/lua/windmills/oltp_read.lua --mysql-host=<host> --mysql-port=<port> --mysql-user=<user> --mysql-password=<pw> --mysql-db=<schema> --db-driver=mysql --tables=200 --table_size=1000000 --rand-type=zipfian --rand-zipfian-exp=0 --skip_trx=true --report-interval=1 --mysql-ignore-errors=all --mysql_storage_engine=innodb --auto_inc=off --histogram --table_name=<tablename> --stats_format=csv --db-ps-mode=disable --point-selects=50 --reconnect=10 --range-selects=true --threads=<#Threads from 2 to 4096> --time=1200 run
As indicated here, I was looking to identify when the first Proxy will reach a dimension that would not be manageable. The load is all in creating and serving the connections, while the number of operations is capped at 100.

As you can see, and as I was expecting, the three Proxies were behaving more or less the same, serving the same number of operations (they were capped, so why not) until they weren’t.
MySQL router, after the 2048 connection, could not serve anything more.
NOTE: MySQL Router actually stopped working at 1024 threads, but using version 8.0.32, I enabled the feature: connection_sharing. That allows it to go a bit further.
Let us take a look also the latency:

Here the situation starts to be a little bit more complicated. MySQL Router is the one that has the higher latency no matter what. However, HAProxy and ProxySQL have interesting behavior. HAProxy performs better with a low number of connections, while ProxySQL performs better when a high number of connections is in place.
This is due to the multiplexing and the very efficient way ProxySQL uses to deal with high load.
Everything has a cost:

HAProxy is definitely using fewer user CPU resources than ProxySQL or MySQL Router …

.. we can also notice that HAProxy barely reaches, on average, the 1.5 CPU load while ProxySQL is at 2.50 and MySQL Router around 2.
To be honest, I was expecting something like this, given ProxySQL’s need to handle the connections and the other basic routing. What was instead a surprise was MySQL Router, why does it have a higher load?
This test highlights that HAProxy and ProxySQL can reach a level of connection higher than the slowest runner in the game (MySQL Router). It is also clear that traffic is better served under a high number of connections by ProxySQL, but it requires more resources.
When the going gets tough, the tough get going
Let’s remove the –rate limitation and see what will happen.

The scenario with load changes drastically. We can see how HAProxy can serve the connection and allow the execution of more operations for the whole test. ProxySQL is immediately after it and behaves quite well, up to 128 threads, then it just collapses.
MySQL Router never takes off; it always stays below the 1k reads/second, while HAProxy served 8.2k and ProxySQL 6.6k.

Looking at the latency, we can see that HAProxy gradually increased as expected, while ProxySQL and MySQL Router just went up from the 256 threads on.
To observe that both ProxySQL and MySQL Router could not complete the tests with 4096 threads.

Why? HAProxy always stays below 50% CPU, no matter the increasing number of threads/connections, scaling the load very efficiently. MySQL router was almost immediately reaching the saturation point, being affected by the number of threads/connections and the number of operations. That was unexpected, given we do not have a level 7 capability in MySQL Router.
Finally, ProxySQL, which was working fine up to a certain limit, reached saturation point and could not serve the load. I am saying load because ProxySQL is a level 7 proxy and is aware of the content of the load. Given that, on top of multiplexing, additional resource consumption was expected.

Here we just have a clear confirmation of what was already said above, with 100% CPU utilization reached by MySQL Router with just 16 threads, and ProxySQL way after at 256 threads.
HAProxy comes up as the champion in this test; there is no doubt that it could scale the increasing load in connection without being affected significantly by the load generated by the requests. The lower consumption in resources also indicates the possible space for even more scaling.
ProxySQL was penalized by the limited resources, but this was the game, we had to get the most out of the few available. This test indicates that it is not optimal to use ProxySQL inside the Operator; it is a wrong choice if low resource and scalability are a must.
MySQL Router was never in the game. Unless a serious refactoring, MySQL Router is designed for very limited scalability, as such, the only way to adopt it is to have many of them at the application node level. Utilizing it close to the data nodes in a centralized position is a mistake.
I started showing an image of how the MySQL service is organized and want to close by showing the variation that, for me, is the one to be considered the default approach:

This highlights that we must always choose the right tool for the job.
The Proxy in architectures involving MySQL/Percona Server for MySQL/Percona XtraDB Cluster is a crucial element for the scalability of the cluster, no matter if using K8s or not. Choosing the one that serves us better is important, which can sometimes be ProxySQL over HAProxy.
However, when talking about K8s and Operators, we must recognize the need to optimize the resources usage for the specific service. In that context, there is no discussion about it, HAProxy is the best solution and the one we should go to.
My final observation is about MySQL Router (aka MySQL Proxy).
Unless there is a significant refactoring of the product, at the moment, it is not even close to what the other two can do. From the tests done so far, it requires a complete reshaping, starting to identify why it is so subject to the load coming from the query more than the load coming from the connections.
Great MySQL to everyone.
Percona Database Performance Blog
https://media.notthebee.com/articles/6418778b6bbe46418778b6bbe6.jpg
Dr. Fauci is on another one of his publicity tours, this time in DC with Mayor Muriel Bowser to guilt poor people into taking his experimental jab.
Not the Bee