https://picperf.io/https://laravelnews.s3.amazonaws.com/featured-images/featured-img-laravel-news-2.png
Call it age. Call it apathy, if you must. I call it contentment. Much of my twenties were spent endlessly experimenting and searching for the perfect editor and workflow. As I read these words back to myself, I’m somewhat embarrassed. “Really? That’s what you spent your twenties doing?” Okay, well, not exclusively. I also like hiking. But, yes, if a new editor hit the market, I was first in line to test it out.
But that was a long time ago. Fast-forward to 2024, and I can’t remember the last time I installed a new code editor. In my eyes, PhpStorm won the IDE wars years ago. The quality and power that they’ve managed to bake into one application is truly staggering.
So, in that spirit, I’d love to share my setup and general workflow with you. As you’ll soon see, the term IDE no longer suggests an incredibly dense UI with hundreds of buttons (though that’s an option, if you prefer). No, I prefer a more minimal approach that I think you’ll appreciate. Okay, let’s do this!
Default Works for Me
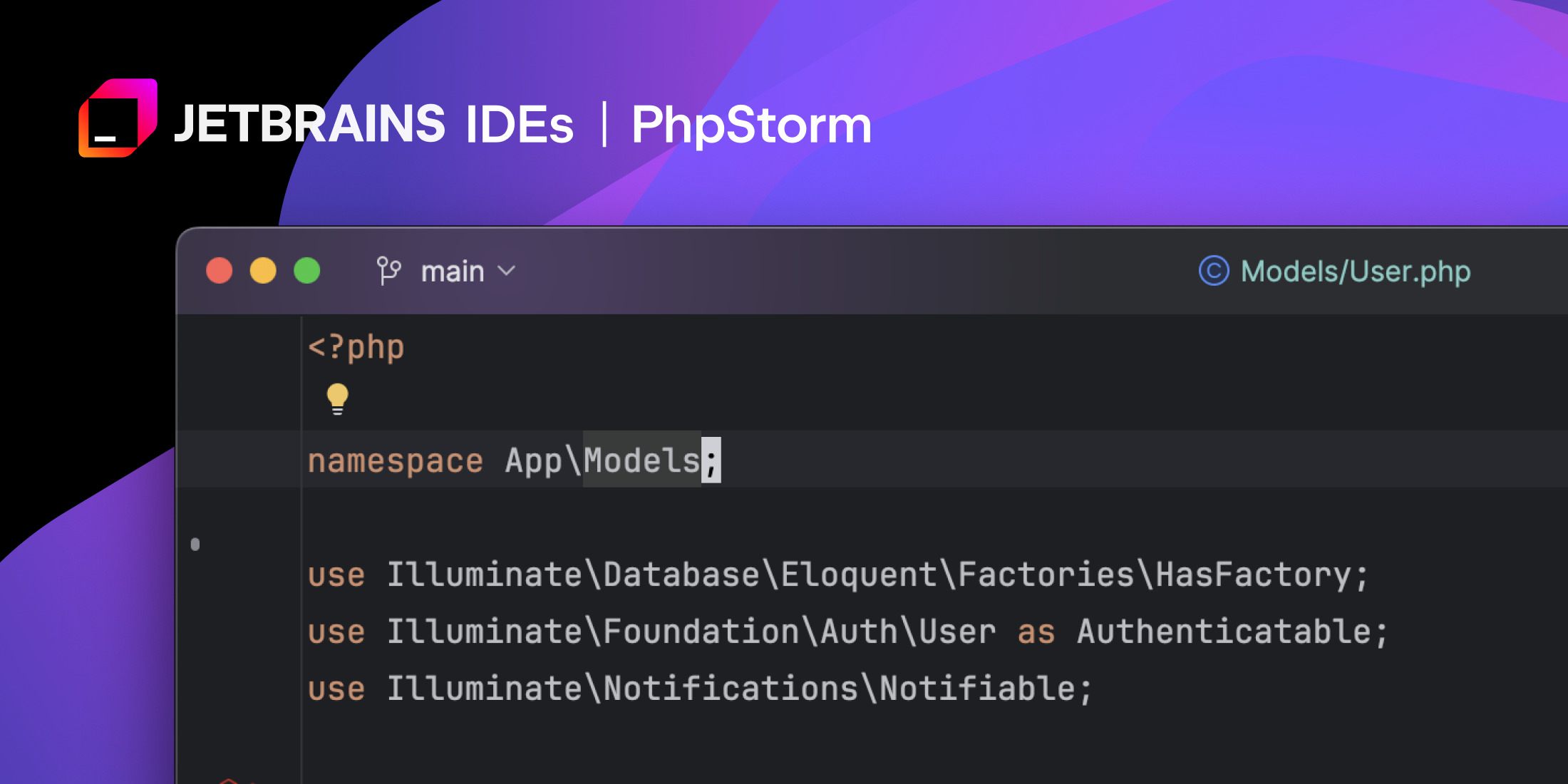
When it comes to color themes, it has taken me a decade to realize that one of your IDE’s suggested defaults is usually the way to go. A plugin containing hundreds of themes, each of which misses the mark in some key area, isn’t a great experience. But your editor’s default themes have been battle tested in every possible configuration.
With that in mind, my preference these days is PhpStorm’s Dark theme, combined with their “New UI” (now the default layout).

Similarly, I also stick with the default JetBrains Mono font at 15px. Yes, it seems that age is becoming a recurring theme for this article. Fifteen pixels looks good to me now.

You’ll notice that I’ve also hidden line numbers and tabs. This is of course a personal preference – and a questionable one to many – however, it’s worth experimenting with for a day.
If you’d like to test it out, like all of PhpStorm’s various actions, you can toggle line numbers and tabs using the “Search Anywhere” menu, which defaults to a keybinding of “Shift + Shift.” Search for “line numbers” and “tab placement,” respectively.
For file traversal, I use a combination of the “Search Anywhere” and “Recent Files” menus. Even better, because all of PhpStorm’s file trees allow for instant filtering, I only need to open the “Recent Files” menu and begin typing the first few characters of the file that I want to open. It’s an incredibly fast workflow.

Plugins
When it comes to plugins, the truth is that PhpStorm includes most of what you need straight out of the box. Support for Tailwind CSS, Vue, Pest, Vite, and Node – to name a small handful – are bundled from the start.
As a former Vim user who will never abandon the keybindings that I spent over a year drilling into my finger tips, I do pull in IdeaVim, which is effectively a Vim engine. And if you want to play around with custom UIs and themes, consider installing the Material Theme UI, Nord or Carbon plugins.
But – there’s one incredibly important plugin that deserves its own heading…
Laravel Idea is the Secret Weapon
PhpStorm has a secret weapon that I’ve yet to see any competing editor match. Laravel Idea is a cheap third-party plugin (with a free 30 day trial) that provides an incredibly deep understanding of the Laravel framework.

It provides powerful code generation directly from your editor, Eloquent attribute auto-completion, pre-populated validation rules, smart routing completion, and so much more. Laravel Idea is the only plugin I pay for, and I do it without thinking. It’s that good.
Code Generation
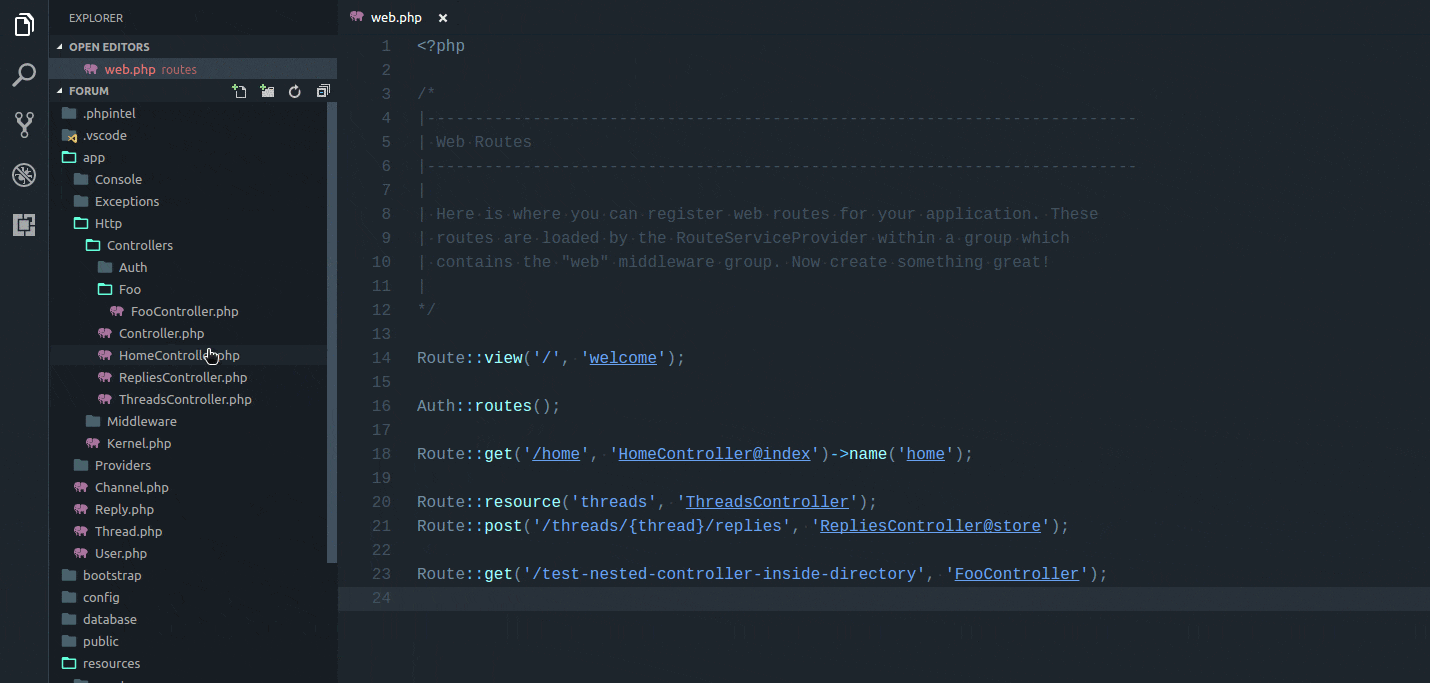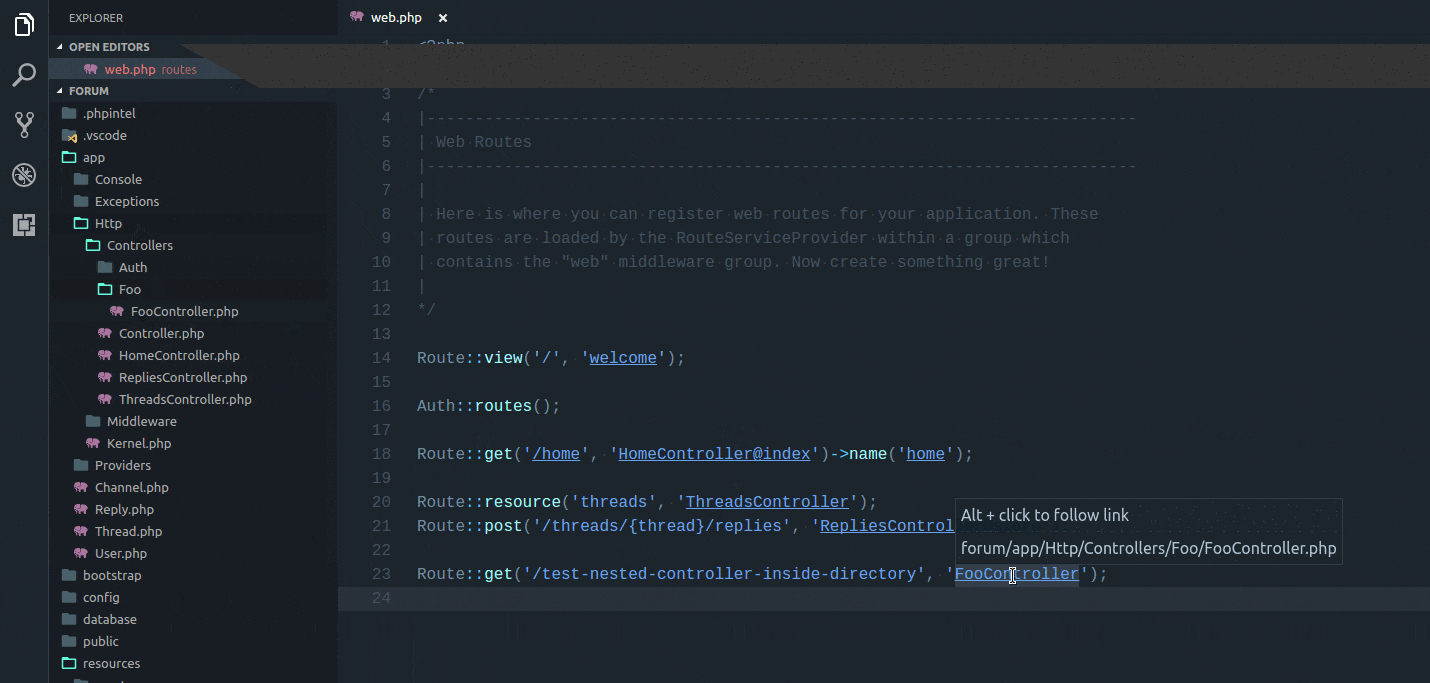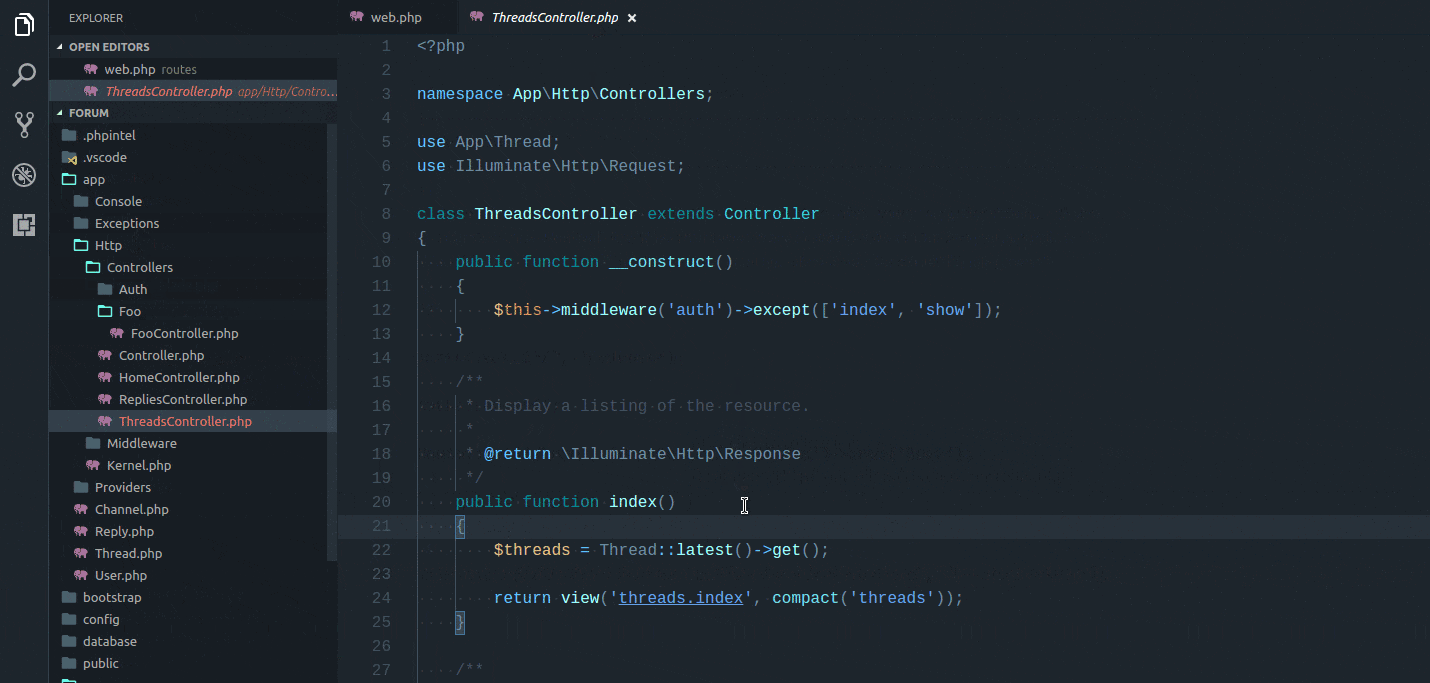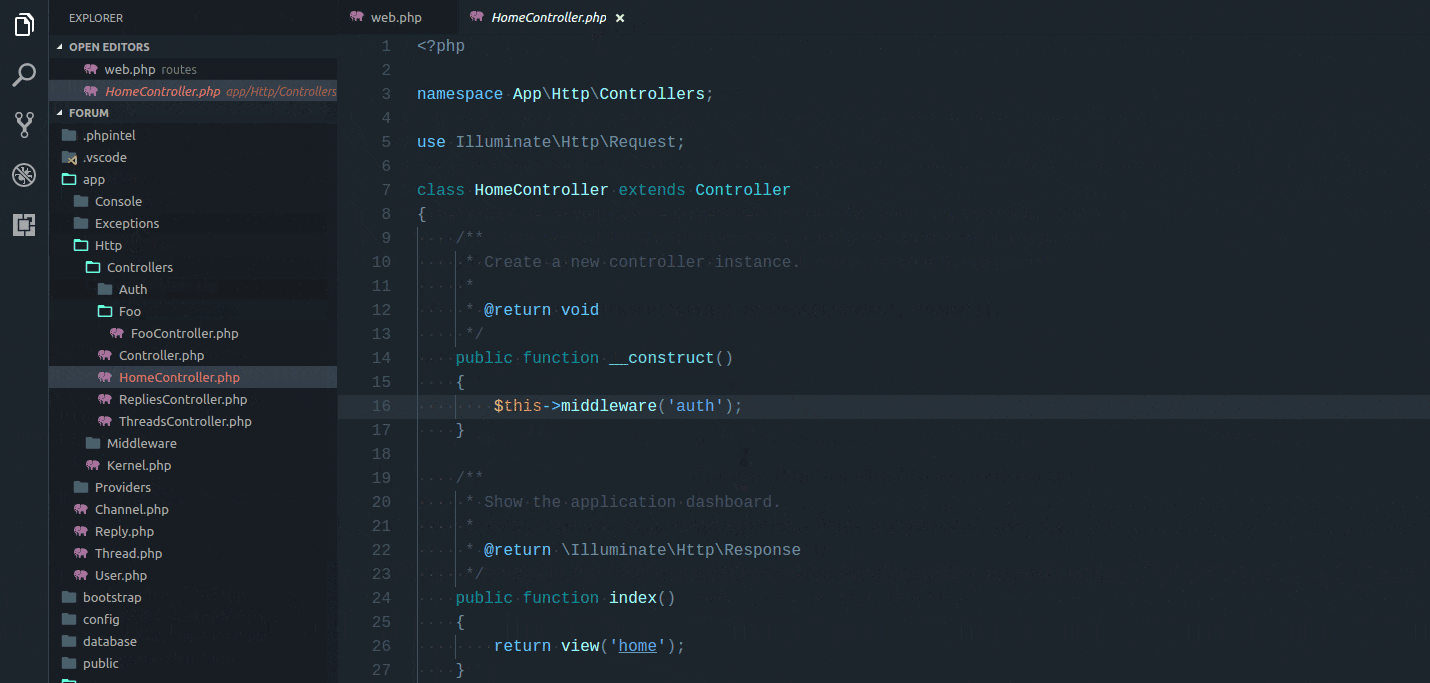
Of course, Laravel and Artisan provide a variety of generators that can be triggered from the command line. However, if you prefer, you can instead run these generators directly within PhpStorm. Navigate to the “Laravel” tab in the menu bar, and choose “Code Generation.”
Here, you can choose your desired file type to generate. It’s so fast.

Notably, when generating an Eloquent model, you’ll be introduced to a dedicated dialog for configuring your desired fields, relations, and options.

Here, I can declare all of the appropriate fields for the model and toggle any companion files that should be generated in the process.
Automatic Validation Rules
Let’s see another example. Imagine that you have an endpoint in your routes file that stores a new Job in the database. Certainly, you should first validate the request data. Rather than writing the rules manually, Laravel Idea can do it for you.
Route::post('/jobs', function () {
request()->validate([
//
]);
});
Place the caret within the validate() array, press Cmd + n, and choose “Add Eloquent Model Fields.” Type the name of the relevant model, Job, and the plugin will populate the array with the appropriate rules, like so:
Route::post('/jobs', function () {
request()->validate([
'employer_id' => ['required', 'exists:employers'],
'title' => ['required'],
'salary' => ['required'],
]);
});
Useful! Laravel Idea provides countless time-savers just like this. It’s an essential plugin for every Laravel user, in my opinion.
Refactor This
The best argument for a dedicated IDE is that you want an editor that deeply understands your underlying language. If I need to rename a variable, implement an interface, or extract a method, I don’t want to rely on regular expressions or a third-party extension. I want that functionality baked into the editor. I want these things working properly to be directly correlated to the financial success of Jetbrains.
If you’re anything like me, you probably have keyboard shortcuts seeping out of your ears at this point. It’s incredible that we can remember so many across a wide range of apps. With that in mind, while there are respective shortcuts for each of PhpStorm’s refactoring options, I use the catch-all “Refactor This” menu, which I bind to Ctrl + t. Open “Search Anywhere” and type “Refactor This” to open the menu manually. This will display a top-level refactoring menu, at which point I can select my preferred refactor.

As always, begin typing to instantly filter the menu items. If I need to, say, extract a method, I would type “extract” and press enter. That way, I never have to reach for the mouse.
An Integrated Terminal
Beginning with the 2024 edition of PHPStorm, you’ll find a new integrated terminal UI that’s significantly improved over previous iterations.

It now supports auto completion, command history (press up), isolated command blocks, and more. I’d recommend binding the integrated Terminal to a shortcut that you’ll remember – I prefer "Ctrl + ` (Backtick)" or Now, you can rapidly toggle the terminal without ever leaving your editor.
Seamless Testing
Testing in PhpStorm is a breeze. Whether you prefer PHPUnit or Pest, it has you covered. Open any test class or file, and you’ll find a Run icon beside each test definition. Give it a click to run that single test in isolation directly inside your editor.

Of course, not every test will pass. For this reason, it can often be useful to re-run the last test from anywhere in your project. This way, you can open a class, make a change, and instantly re-run the failing test to confirm that the issue has been resolved.
The command you want for this behavior is “Rerun.” To avoid touching the mouse, consider assigning a keybinding, such as “Shift + Command + T.”
Tip: You can configure your own keybindings within Settings → Keymap.

In the screenshot above, notice that the commented-out line in Comment.php has triggered a failing test. Let’s fix the issue by uncommenting that line (if only all bugs were this easy to solve), and rerunning the test (using Shift + Command + T).

Wew!
Auto-formatting
PhpStorm of course includes support for automatic code formatting in a variety of code styles. Within the Settings menu, visit Editor → Code Style → PHP and click “Set From” to choose your style.

This is helpful, but if you’d instead prefer an external code formatter such as Laravel Pint, you can easily instruct PhpStorm to disable its internal formatter in favor of your external tool. This is precisely what I do.
Open your Settings menu once again, and visit PHP → Quality Tools. Here, you’ll find a handful of external formatters. Select “Laravel Pint” and you should be all set to go!

Next, it would be nice if we could instruct PhpStorm to perform a series of actions or commands each time we save a file. For example, format the file, optimize the imports (sort and remove unused), clean up the code, run ESLint, etc. This is what the “Actions on Save” menu is for. You can access it within the Settings menu, as usual: Tools → Actions on Save.

Select your preferred actions, and the editor will execute them each time you save a file.
Debugging
Despite what its creator may suggest – 👀 – Xdebug can often be an exercise in frustration to install. It’s clear, though, that the PhpStorm team is well aware of this. They’ve done an excellent job making the process as simple and obvious as possible. Let me show you.
The first stop on your debugging journey is Settings → PHP → Debug. On this page, you’ll see a “Pre-Configuration” checklist to verify that you’ve properly installed Xdebug. Helpful!

This checklist roughly consists of installing Xdebug, choosing a browser toolbar extension, enabling listening for PHP Debug Connections, and then starting a debug session. I would highly suggest using the validator that PhpStorm links to in pre-configuration step one.
Validation Heads Up! If you’re using Herd Pro to automatically detect and enable Xdebug on the fly, PhpStorm’s configuration validator will fail if you simply copy the contents of phpinfo() directly from the command line (php —info | pbcopy). Instead, signal to Herd that you intend to use Xdebug. One way to do this is by setting a breakpoint. Click inside the gutter for any line number. Next, echo phpinfo() and copy its output directly from the browser.

Once you follow each step in the pre-configuration checklist, you should be ready to roll. Set a breakpoint, load the page, and start debugging like the champion you are.

Conclusion
And that’s a wrap!
You may have noticed, but programmers tend to have… opinions. When it comes to code editors, they have even more opinions. Of course, choose the tool that best fits your personality and workflow, but I really do think PhpStorm is worth your time. Having used it for many years at this point, I continue to discover new features and time-savers that I never knew existed.
If I’ve piqued your interest, we have an excellent and free PhpStorm course over at Laracasts. In 2.5 hours, we’ll show you everything you need to know. 🚀

The post Jeffrey Way’s PhpStorm Setup in 2024 appeared first on Laravel News.
Join the Laravel Newsletter to get all the latest Laravel articles like this directly in your inbox.
Laravel News
 Photo by Tucker Bowe for Gear Patrol
Photo by Tucker Bowe for Gear Patrol Dockcase
Dockcase



 We usually receive and see some questions regarding the charset levels in MySQL, especially after the deprecation of utf8mb3 and the new default uf8mb4. If you understand how the charset works on MySQL but have some questions regarding this change, please check out Migrating to utf8mb4: Things to Consider by Sveta Smirnova.Some of the questions […]Planet MySQL
We usually receive and see some questions regarding the charset levels in MySQL, especially after the deprecation of utf8mb3 and the new default uf8mb4. If you understand how the charset works on MySQL but have some questions regarding this change, please check out Migrating to utf8mb4: Things to Consider by Sveta Smirnova.Some of the questions […]Planet MySQL