West Virginia – Constitutional Carry w/shall issue permits
Wisconsin – Shall Issue
WyomingConstitutional Carry w/shall issue permits
RELATED STORY
Top 10 Lifesaving Concealed Carry Tips for 2022
Concealed Carry Laws By State Discussion
The interstate traveler has 50 different sets of rules to deal with, plus over-riding federal law. It isn’t easy, but for safety and peace of mind when traveling, the laws of the jurisdictions where you’re going are worth knowing.
I write more than a few magazine articles each year, and this one is always the hardest. The reason is because nothing else I’m assigned to write about has 50 or more facets on its surface, every one of them capable of changing at a moment’s notice.
In other countries where I’ve carried guns, the license usually covers the holder anywhere in the nation. Here, in this regard at least, it seems that the operative word in “United States” is “states.” There are 50 of them, each with their own set of gun laws: a patchwork quilt made up of half a hundred pieces.
That worked out reasonably well a hundred years ago, when this country still had an agrarian-based economy and most ordinary folks still grew up, lived, and died within 50 or 100 miles of where they were born. Today, we Americans constitute the most mobile society on earth. A road trip might take you through several states in a single day.
The states have universal reciprocity with your driver’s license. That’s not so with your concealed carry license. The differences are many. For instance, carrying a gun without a piece of paper that authorizes you to do so is perfectly legal in Alaska, but will get you popped for a misdemeanor on the first offense and a felony on the second offense in New Hampshire, and will see you convicted of a felony for the first offense in New York. There are states where any honest, law-abiding citizen can get the permit to carry, states where only the rich and powerful are likely to do so, and states where no one can.
I’ve long since given up on trying to publish lists of state gun laws in an annual magazine since they change so frequently. Just about every week, you hear that State A has added State B to the list of issuing authorities whose gun carry permits they’ll recognize, while State C has announced that it will no longer be reciprocal with State D.
That’s why, instead, I’m going to recommend that you go online and check an Internet site that can be far more up to date than any print medium. The best site (www.handgunlaw.us) for concealed carry at this time, in my opinion. Founded by Steve Aikens and Gary Slider, this site “has its feelers out” and stays on top of changes in handgun laws, with emphasis on concealed carry rules. There are links to each state’s official “dot-gov” websites, where you can pick up the fine points of their regulations.
First, let’s get a little terminology thing out of the way. Some absolutists and semanticists like to debate whether that little paper that authorizes CCW (Concealed Carry Weapon) is a “license” or “permit.” Not having time for semantics here, I’ll use them interchangeably. Whether or not we believe that carrying a gun should be a right, we have to understand the reality, our legal system has evolved in such a way that carrying a gun has come to be treated as a privilege, one that requires that specific piece of paper in 48 of the 50 states.
If you want to carry a concealed handgun in this country, there are four different approaches you’ll have to deal with depending on where you are.
Constitutional Carry
Under this system, no permit or license is required to carry a loaded, concealed handgun in public, though certain places (courthouses, for example) may be off-limits. For many years, Vermont was our only such state. A few years ago, Alaska took the same route. One is merely forbidden to “carry” if one is a convicted felon, has been adjudicated mentally incompetent, or has criminal intent. And yes, in both Vermont and Alaska, these laws extend to visitors from out of state. Since that time, many other states have joined the list of Constitutional Carry states.
This seems to have worked well for the relatively short time it has been in place in Alaska, and it has worked famously well for the long time that it has been in place in Vermont. For many years Vermont has proven to have the lowest crime rate in the nation. You’d think this would tell the other states something about Free Carry.
About the only real problem Vermont had with this system was that with no permit of their own, when other states offered reciprocity, pistol packers in the Green Mountain state had nothing to reciprocate with. The savvy lawmakers who brought the Vermont Model to Alaska picked up on that, and Alaskans today have the option of a shall-issue permit which is recognized by many other states.
Shall-Issue
It is on this front that activists for gun owners’ civil rights have won the most important series of victories in the last 20 years. Circa 1987, the state of Florida went from a system where it was optional for the authorities to give out such permits (and they were only good in the county where they were issued) to a license that authorized the holder to carry statewide. Moreover, the law was written so that the permit could not be denied to any law-abiding citizen with a clean criminal record who could show a minimal acceptable level of firearms safety training. This is known as shall-issue licensing.
The “Florida Model” was soon copied across the land. It has been wonderfully successful. Nowhere has it triggered the increase in spontaneous violent crimes that its opponents predicted, and indeed, the norm seems to be that violent crime against the person goes down after these improved legislative reforms are passed.
Shall-issue means that the appointed issuing authority can’t turn you down because they don’t like the color of your skin or the way you vote, or the idea of ordinary people carrying guns. Currently, shall issue is the most popular form of concealed carry.
May-Issue
As the term implies, issuing authorities in these states may issue permits if they choose, but are not required to do so. This is also known as the “Discretionary” system, because the permits are issued at the discretion of the authorities. This old system is rife with corruption. In one big city, the story on the police force was that the cops in charge of issuing permits were transferred more frequently than vice cops, because police bosses saw the position as being ripe to draw tantalizing bribes for the “victimless crime” of allowing people to protect themselves from criminals.
This is not to say that the authorities take bribes, mind you. However, in may-issue jurisdictions, when a list of carry permit holders is published, it tends to comprise the wealthiest members of the community. New York State Penal Code 265, which encompasses this sort of regulation, requires that the issuing authority set its own standards as to who will get permits, and then stick to it. In New York City, one standard set was that the individual was likely to carry large sums of money. When Old West gunfighter Bat Masterson became a sportswriter in New York City, he wrote that the law in its wisdom allowed both the rich and poor to have ice, it was just that the rich had it in the summer and the poor had it in winter. New York City’s interpretation of the concealed carry privilege seemed to be similar, the rich and poor alike can get carry permits, so long as they carry large amounts of cash or other valuables.
States that currently hold to the may-issue rule include Alabama, California, Connecticut, Delaware, Hawaii, Iowa, Maryland, Massachusetts, New Jersey, New York, and Rhode Island. The District of Columbia technically falls in this group as well, though one wonders how someone who lives there can utilize the permit, since possession of handguns by all but police has long been banned in that jurisdiction. Fortunately, as I write this, that ban has just been struck down by the SCOTUS decision in the Heller case.
May-issue systems lend themselves to the sort of decisions for which the legal system coined the term “arbitrary and capricious.” In Hawaii, for instance, while technically it’s possible to get a carry permit, it just isn’t possible in real world practice. I am aware of three having been issued there to private citizens during my adult lifetime. One went to the civilian armorer who serviced the Honolulu Police Department’s duty weapons. Another was held by the Governor, who got it when he was Lieutenant Governor. The third didn’t last long, a Honolulu Police Chief issued it to his sister-in-law, but had to take it back when the newspapers got wind of the story. On the other hand, I hear that a few hundred carry permits have been issued in the last few years to security guards in Hawaii. That’s sort of analogous to a chip out of the Great Wall of China, but maybe it’s a start.
No-Issue
As of 2022, there are no longer any US states that completely deny the right to carry a concealed or open firearm. However, as noted above, some may-issue states such as Miami have such arbitrary and capricious permitting systems as to be functionally no-issue. Other states, such as New Jersey and New York only issue permits to the rich, famous, and connected.
Reciprocity
Gun owners’ civil rights groups have made great strides in gaining reciprocity, that is, recognition of permits issued in other states. Reciprocity keys on agreements between the Attorney General of the given states. The carry permits that seem to have the most reciprocity, as many as 30 or so states, come from Florida, New Hampshire, and Utah. Some states have “total reciprocity,” in that they recognize permits issued in all other states. Indiana and Michigan have had this policy for as long as I can remember, and it has always worked well. More common, however, is “limited reciprocity,” which means that only certain states’ carry licenses will be recognized by the given jurisdiction. Sometimes this is because the given state insists that the other state have requirements at least as strict as their own, and sometimes it’s simply a case of “we’ll recognize yours if you’ll recognize ours.” There are also some states that will only recognize your out-of-state permit if you live in the state where it was issued.
Some other states will not recognize outside permits, but will issue their own non-resident permits. Check out www.handgunlaw.us for the lists of who recognizes whom, and which states issue non-resident permits, and where to apply for the latter.
The careful armed citizen who knows the law and fills out the paperwork can broaden their concealed carry world dramatically. For instance, it has long been believed that New England was a bastion of anti-gun sentiment, but the fact is that the responsible gun owner who dots every “i” and crosses every “t” can become legal to carry throughout that six-state region. Vermont does not require a permit to carry (though some towns there have reportedly enacted concealed carry bans: check which ones before you go there). New Hampshire has a long list of states whose permits they’ll recognize reciprocally, and also issues non-resident permits through the State Police in Concord, the capital city. Maine, Connecticut, Massachusetts and Rhode Island also have non-resident permit procedures in place, though you may encounter progressively difficult procedures as you attempt to obtain them. Nonetheless, it can be done.
The bottom line is that the concealed carry picture is brighter right now than it has been in the memory of any living American. We who worked for it can congratulate ourselves, but we can’t rest on our laurels. There is still much work to do. There are still many more lives to protect.
You’ve gotta break some eggs to make a YouTube video. The Slow Mo Guys broke out the big guns with the Phantom TMX 7510 high-speed camera to capture footage of eggs being pierced with a bullet at as much as 1 million frames per second. While the slowest shots are amazing, the resolution drops off dramatically around 100,000 fps.
I’m no video game nerd, but I’ve seen and played enough games to know that these guys pretending to be in a video game are very accurate and very impressive.
Donning the novelty singer’s trademark curly hair, mustache, and accordion, Daniel Radcliffe pulls out all of the stops for this unconventional biopic about the life of “Weird Al” Yankovic. We have high hopes it’s as weird as it sounds. Coming to The Roku Channel fall 2022.
WINSTON-SALEM, NC—Gary Chapman, the author of the best-selling Christian romance novel The 5 Love Languages, has just announced that a 6th love language has emerged: Tacos.
“I always knew a love language was missing. Acts of Service, Quality Time, Physical Touch, Recurring Gifts, and Words Of Affirmation just felt incomplete and left me with an insatiable hunger that could never be filled,” said Gary Chapman. “That’s when it hit me: what people need to feel loved is Tacos!”
Chapman continued, ”It needed some additional meat to it (preferably seasoned ground beef or pork) with something special sprinkled on top and all wrapped up together in something tangible people could actually hold, and sink their teeth into. And that’s when it hit me…TACOS!”
According to sources, Gary Chapman’s new book The 6th Love Language details how couples can keep their love tank full by providing their loved one with delicious tacos. Many positive reviews have already flooded in with hundreds stating that their marriage has been saved thanks to tacos.
“Our marriage was on the rocks. We just couldn’t seem to express our love for one another in the way that fills each other’s ‘love tank,'” said Ben Heinemeier and his wife Jennifer. “Sometimes your words, time, gifts, touch, and actions just aren’t what people need. Instead, what they need is a tasty Mexican dish full of meat, cheese, and lettuce in a fried tortilla shell!”
At publishing time, Gary Chapman was rumored to be developing a brand new secret 7th love language: Pizza.
Mandy is absolutely triggered by Twitter’s possible takeover by Elon Musk. She attends a Twitter-sponsored therapy session to help her cope.
https://i.ytimg.com/vi/qSJlovwPEJE/maxresdefault.jpgA facade in Laravel is a wrapper around a non-static function that turns it into a static function. Before we continue, you need to have a basic understanding of Laravel Ioc service containers.Laravel News Links
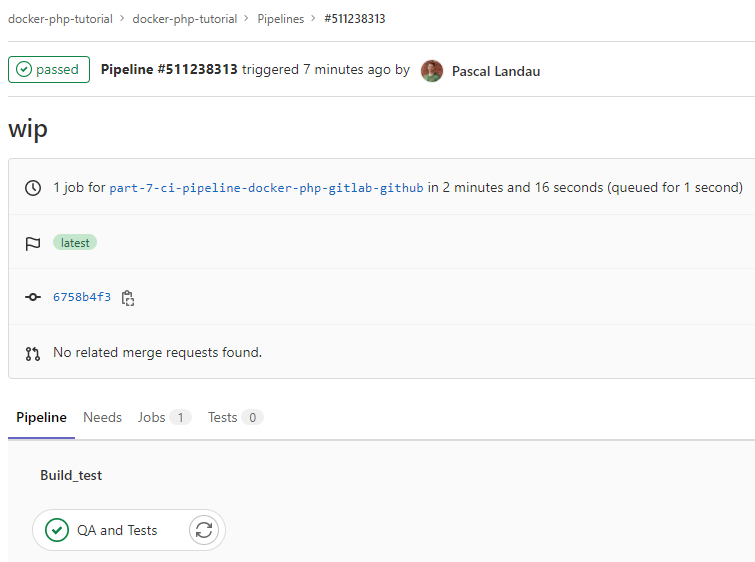
In the seventh part of this tutorial series on developing PHP on Docker we will setup a CI
(Continuous Integration) pipeline to run code quality tools and tests on Github Actions and Gitlab
Pipelines.
If you want to follow along, please subscribe to the RSS feed
or via email
to get automatic notifications when the next part comes out 🙂
Table of contents
Introduction
CI is short for Continuous Integration and to me mostly means running the code quality
tools and tests of a codebase in an isolated environment (preferably automatically). This is
particularly important when working in a team, because the CI system acts as the final
gatekeeper before features or bugfixes are merged into the main branch.
I initially learned about CI systems when I stubbed my toes into the open source water. Back in the
day I used Travis CI for my own projects and replaced it
with Github Actions at some point. At ABOUT YOU we started
out with a self-hosted Jenkins server and then moved on to Gitlab CI as a fully
managed solution (though we use custom runners).
Recommended reading
This tutorial builds on top of the previous parts. I’ll do my best to cross-reference the
corresponding articles when necessary, but I would still recommend to do some upfront reading on:
And as a nice-to-know:
Approach
In this tutorial I’m going to explain how to make our existing docker setup work with Github Actions
and Gitlab CI/CD Pipelines. As I’m a big fan of a
“progressive enhancement” approach, we will ensure that all necessary steps can be performed
locally through make. This has the additional benefit of keeping a single source of truth (the Makefile) which will come in handy when we set up the CI system on two different providers
(Github and Gitlab).
The general process will look very similar to the one for local development:
build the docker setup
start the docker setup
run the qa tools
run the tests
You can see the final results in the CI setup section, including the concrete yml
files and links to the repositories, see
On a code level, we will treat CI as an environment, configured through the env variable ENV. So
far we only used ENV=local and we will extend that to also use ENV=ci. The necessary changes
are explained after the concrete CI setup instructions in the sections
This should give you a similar output as presented in the Execution example.
git checkout part-7-ci-pipeline-docker-php-gitlab-github
# Initialize make
make make-init
# Execute the local CI run
bash .local-ci.sh
CI setup
General CI notes
Initialize make for CI
As a very first step we need to “configure” the codebase to operate for the ci environment.
This is done through the make-init target as explained later in more detail in the Makefile changes section via
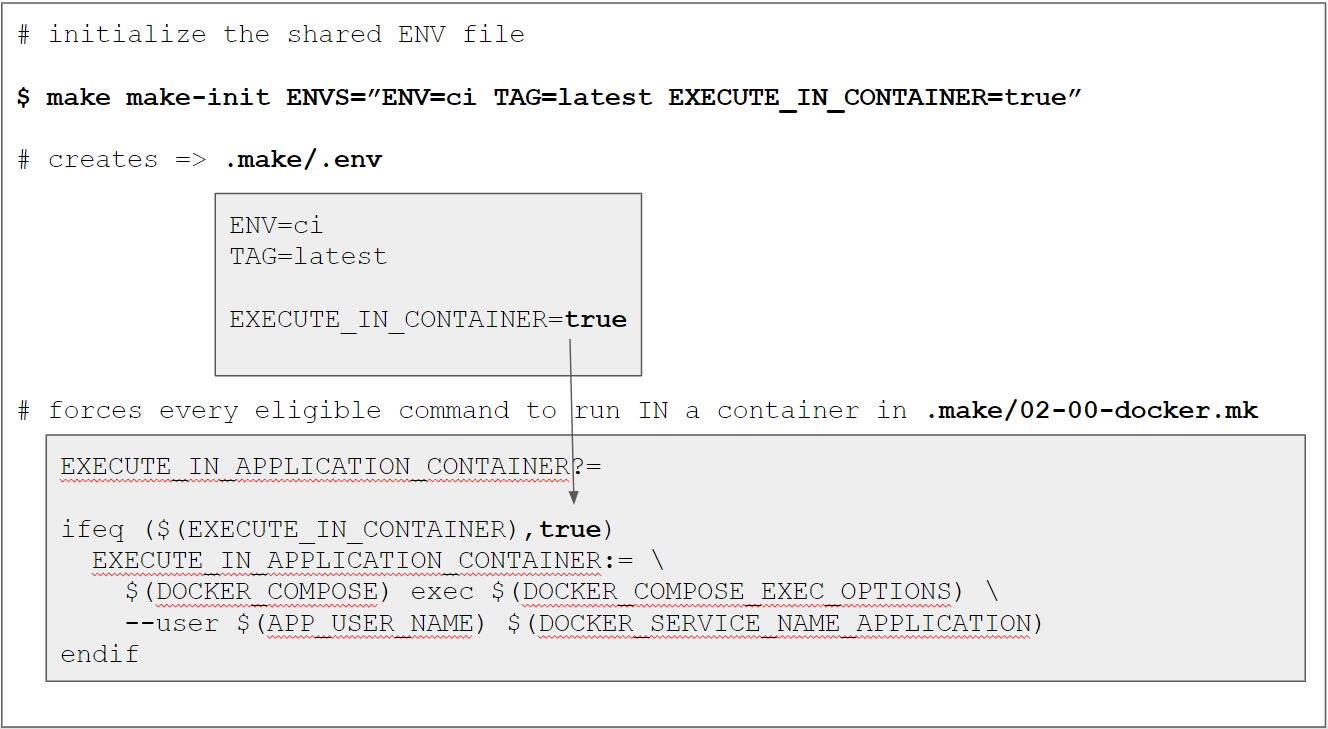
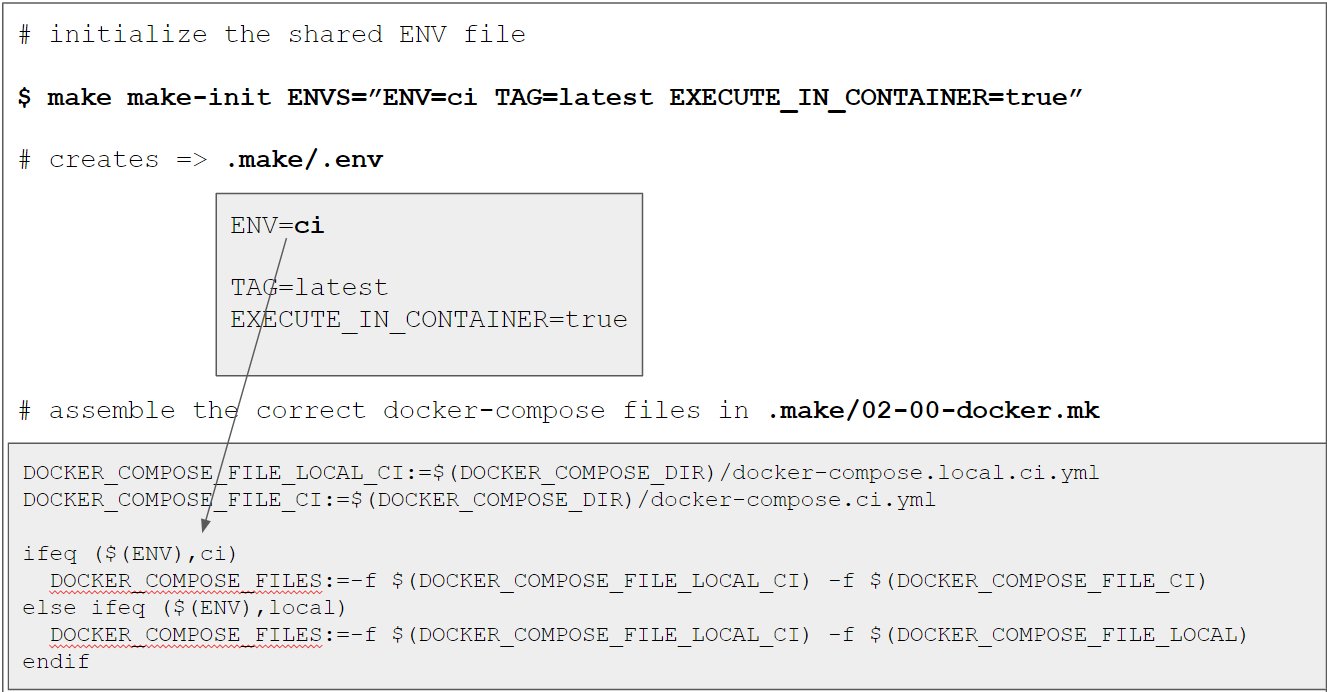
make make-init ENVS="ENV=ci TAG=latest EXECUTE_IN_CONTAINER=true GPG_PASSWORD=12345678"
$ make make-init ENVS="ENV=ci TAG=latest EXECUTE_IN_CONTAINER=true GPG_PASSWORD=12345678"
Created a local .make/.env file
ENV=ci ensures that we
TAG=latest is just a simplification for now because we don’t do anything with the images yet.
In an upcoming tutorial we will push them to a container registry for later usage in production
deployments and then set the TAG to something more meaningful (like the build number).
EXECUTE_IN_CONTAINER=true forces every make command that uses a RUN_IN_*_CONTAINER setup
to run in a container. This is important, because the Gitlab runner will actually run in a
docker container itself. However, this would cause any affected target to omit the $(DOCKER_COMPOSER) exec prefix.
I’ll explain the “container is up and running but the underlying service is not” problem
for the mysql service and how we can solve it with a health check later in this article at Adding a health check for mysql.
On purpose, we don’t want docker compose to take care of the waiting because we can make
“better use of the waiting time” and will instead implement it ourselves with a simple bash
script located at .docker/scripts/wait-for-service.sh:
#!/bin/bash
name=$1
max=$2
interval=$3
[ -z "$1" ] && echo "Usage example: bash wait-for-service.sh mysql 5 1"
[ -z "$2" ] && max=30
[ -z "$3" ] && interval=1
echo "Waiting for service '$name' to become healthy, checking every $interval second(s) for max. $max times"
while true; do
((i++))
echo "[$i/$max] ...";
status=$(docker inspect --format "" "$(docker ps --filter name="$name" -q)")
if echo "$status" | grep -q '"healthy"'; then
echo "SUCCESS";
break
fi
if [ $i == $max ]; then
echo "FAIL";
exit 1
fi
sleep $interval;
done
CAUTION: The script uses $(docker ps --filter name="$name" -q) to determine the id of the
container, i.e. it will “match” all running containers against the $name – this would fail if
there is more than one matching container! I.e. you must ensure that $name is specific
enough to identify one single container uniquely.
The script will check up to $max times
in a interval of $interval seconds. See these answers on the
“How do I write a retry logic in script to keep retrying to run it up to 5 times?” question for
the implementation of the retry logic. To check the health of the mysql service for 5
times with 1 seconds between each try, it can be called via
bash wait-for-service.sh mysql 5 1
Output
$ bash wait-for-service.sh mysql 5 1
Waiting for service 'mysql' to become healthy, checking every 1 second(s) for max. 5 times
[1/5] ...
[2/5] ...
[3/5] ...
[4/5] ...
[5/5] ...
FAIL
# OR
$ bash wait-for-service.sh mysql 5 1
Waiting for service 'mysql' to become healthy, checking every 1 second(s) for max. 5 times
[1/5] ...
[2/5] ...
SUCCESS
The problem of “container dependencies” isn’t new and there are already some existing solutions
out there, e.g.
But unfortunately all of them operate by checking the availability of a host:port combination
and in the case of mysql that didn’t help, because the container was up, the port was reachable
but the mysql service in the container was not.
Setup for a “local” CI run
As mentioned under Approach, we want to be able to perform all necessary steps
locally and I created a corresponding script at .local-ci.sh:
#!/bin/bash
# fail on any error
# @see https://stackoverflow.com/a/3474556/413531
set -e
make docker-down ENV=ci || true
start_total=$(date +%s)
# STORE GPG KEY
cp secret-protected.gpg.example secret.gpg
# DEBUG
docker version
docker compose version
cat /etc/*-release || true
# SETUP DOCKER
make make-init ENVS="ENV=ci TAG=latest EXECUTE_IN_CONTAINER=true GPG_PASSWORD=12345678"
start_docker_build=$(date +%s)
make docker-build
end_docker_build=$(date +%s)
mkdir -p .build && chmod 777 .build
# START DOCKER
start_docker_up=$(date +%s)
make docker-up
end_docker_up=$(date +%s)
make gpg-init
make secret-decrypt-with-password
# QA
start_qa=$(date +%s)
make qa || FAILED=true
end_qa=$(date +%s)
# WAIT FOR CONTAINERS
start_wait_for_containers=$(date +%s)
bash .docker/scripts/wait-for-service.sh mysql 30 1
end_wait_for_containers=$(date +%s)
# TEST
start_test=$(date +%s)
make test || FAILED=true
end_test=$(date +%s)
end_total=$(date +%s)
# RUNTIMES
echo "Build docker: " `expr $end_docker_build - $start_docker_build`
echo "Start docker: " `expr $end_docker_up - $start_docker_up `
echo "QA: " `expr $end_qa - $start_qa`
echo "Wait for containers: " `expr $end_wait_for_containers - $start_wait_for_containers`
echo "Tests: " `expr $end_test - $start_test`
echo "---------------------"
echo "Total: " `expr $end_total - $start_total`
# CLEANUP
# reset the default make variables
make make-init
make docker-down ENV=ci || true
# EVALUATE RESULTS
if [ "$FAILED" == "true" ]; then echo "FAILED"; exit 1; fi
echo "SUCCESS"
Run details
as a preparation step, we first ensure that no outdated ci containers are running (this is
only necessary locally, because runners on a remote CI system will start “from scratch”)
make docker-down ENV=ci || true
we take some time measurements to understand how long certain parts take via
start_total=$(date +%s)
to store the current timestamp
we need the secret gpg key in order to decrypt the secrets and simply copy the password-protected example key
(in the actual CI systems the key will be configured as a secret value that is injected in
the run)
# STORE GPG KEY
cp secret-protected.gpg.example secret.gpg
I like printing some debugging info in order to understand which exact circumstances
we’re dealing with (tbh, this is mostly relevant when setting the CI system up or making
modifications to it)
# DEBUG
docker version
docker compose version
cat /etc/*-release || true
We don’t need to pass a GPG_PASSWORD to secret-decrypt-with-password because we have set
it up in the previous step as a default value via make-init
once the application container is running, the qa tools are run by invoking the qa make target
# QA
make qa || FAILED=true
The || FAILED=true part makes sure that the script will not be terminated if the checks fail.
Instead, the fact that a failure happened is “recorded” in the FAILED variable so that we
can evaluate it at the end. We don’t want the script to stop here because we want the
following steps to be executed as well (e.g. the tests).
Workflows are yaml files that live in the special .github/workflows directory in the
repository
a Workflow can contain multiple Jobs
each Job consists of a series of Steps
each Step needs a run: element that represents a command that is executed by a new shell
The Workflow file
Github Actions are triggered automatically based on the files in the .github/workflows directory.
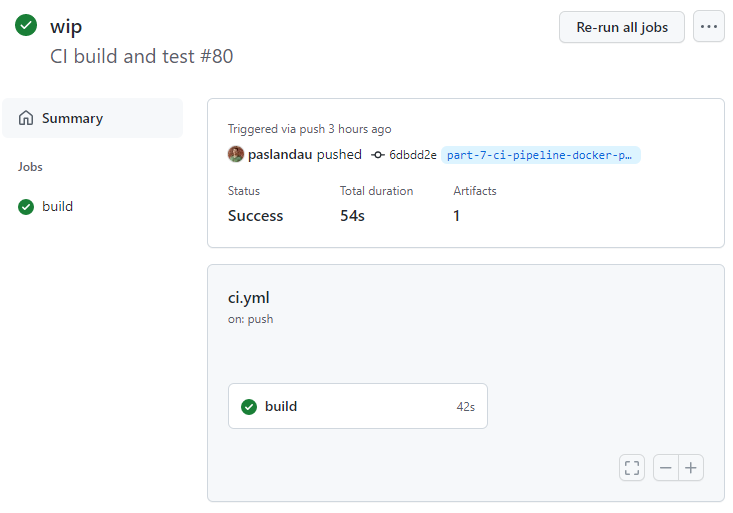
I have added the file .github/workflows/ci.yml with the following content:
name: CI build and test
on:
# automatically run for pull request and for pushes to branch "part-7-ci-pipeline-docker-php-gitlab-github"
# @see https://stackoverflow.com/a/58142412/413531
push:
branches:
- part-7-ci-pipeline-docker-php-gitlab-github
pull_request: {}
# enable to trigger the action manually
# @see https://github.blog/changelog/2020-07-06-github-actions-manual-triggers-with-workflow_dispatch/
# CAUTION: there is a known bug that makes the "button to trigger the run" not show up
# @see https://github.community/t/workflow-dispatch-workflow-not-showing-in-actions-tab/130088/29
workflow_dispatch: {}
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/[email protected]
- name: start timer
run: |
echo "START_TOTAL=$(date +%s)" > $GITHUB_ENV
- name: STORE GPG KEY
run: |
# Note: make sure to wrap the secret in double quotes (")
echo "$" > ./secret.gpg
- name: SETUP TOOLS
run : |
DOCKER_CONFIG=${DOCKER_CONFIG:-$HOME/.docker}
# install docker compose
# @see https://docs.docker.com/compose/cli-command/#install-on-linux
# @see https://github.com/docker/compose/issues/8630#issuecomment-1073166114
mkdir -p $DOCKER_CONFIG/cli-plugins
curl -sSL https://github.com/docker/compose/releases/download/v2.2.3/docker-compose-linux-$(uname -m) -o $DOCKER_CONFIG/cli-plugins/docker-compose
chmod +x $DOCKER_CONFIG/cli-plugins/docker-compose
- name: DEBUG
run: |
docker compose version
docker --version
cat /etc/*-release
- name: SETUP DOCKER
run: |
make make-init ENVS="ENV=ci TAG=latest EXECUTE_IN_CONTAINER=true GPG_PASSWORD=$"
make docker-build
mkdir .build && chmod 777 .build
- name: START DOCKER
run: |
make docker-up
make gpg-init
make secret-decrypt-with-password
- name: QA
run: |
# Run the tests and qa tools but only store the error instead of failing immediately
# @see https://stackoverflow.com/a/59200738/413531
make qa || echo "FAILED=qa" >> $GITHUB_ENV
- name: WAIT FOR CONTAINERS
run: |
# We need to wait until mysql is available.
bash .docker/scripts/wait-for-service.sh mysql 30 1
- name: TEST
run: |
make test || echo "FAILED=test $FAILED" >> $GITHUB_ENV
- name: RUNTIMES
run: |
echo `expr $(date +%s) - $START_TOTAL`
- name: EVALUATE
run: |
# Check if $FAILED is NOT empty
if [ ! -z "$FAILED" ]; then echo "Failed at $FAILED" && exit 1; fi
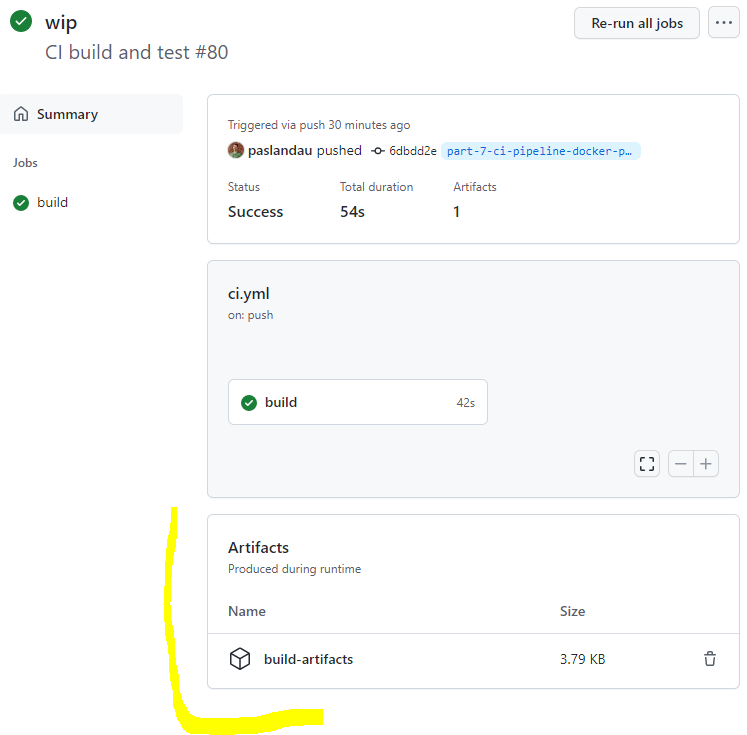
- name: upload build artifacts
uses: actions/[email protected]
with:
name: build-artifacts
path: ./.build
This will be the only timer we use, because the job uses multiple steps that are timed
automatically – so we don’t need to take timestamps manually:
the gpg key is configured as an encrypted secret named GPG_KEY and is stored in ./secret.gpg. The value is the content of the secret-protected.gpg.example file
for the make initialization we need the second secret named GPG_PASSWORD – which is
configured as 12345678 in our case, see Add a password-protected secret gpg key
because the runner will be shutdown after the run, we need to move the build artifacts to a
permanent location, using the actions/[email protected] action
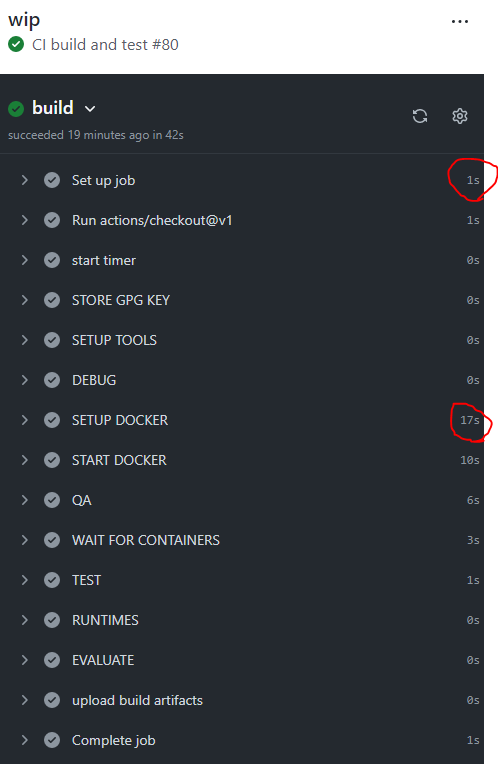
Performance isn’t an issue right now, because the CI runs take only about ~1 min (Github Actions)
and ~2 min (Gitlab Pipelines), but that’s mostly because we only ship a super minimal
application and those times will go up when things get more complex. For the local setup I
used all 8 cores of my laptop. The time breakdown is roughly as follows:
Step
Gitlab
Github
local without cache
local with cached images
local with cached images + layers
SETUP TOOLS
1
0
0
0
0
SETUP DOCKER
33
17
39
39
5
START DOCKER
17
11
34
2
1
QA
17
5
10
13
1
WAIT FOR CONTAINERS
5
5
3
2
13
TESTS
3
1
3
6
3
total (excl. runner startup)
78
43
97
70
36
total (incl. runner startup)
139
54
97
70
36
Times taken from
Optimizing the performance is out of scope for this tutorial, but I’ll at least document my
current findings.
The caching problem on CI
A good chunk of time is usually spent on building the docker images. We did our best to optimize
the process by leveraging the layer cache and using cache mounts
(see section Build stage ci in the php-base image).
But those steps are futile on CI systems, because the corresponding runners will start “from
scratch” for every CI run – i.e. there is no local cache that they could use. In
consequence, the full docker setup is also built “from scratch” on every run.
There are ways to mitigate that e.g.
But: None of that worked for me out-of-the-box 🙁 We will take a closer look in an upcoming
tutorial. Some reading material that I found valuable so far:
Docker changes
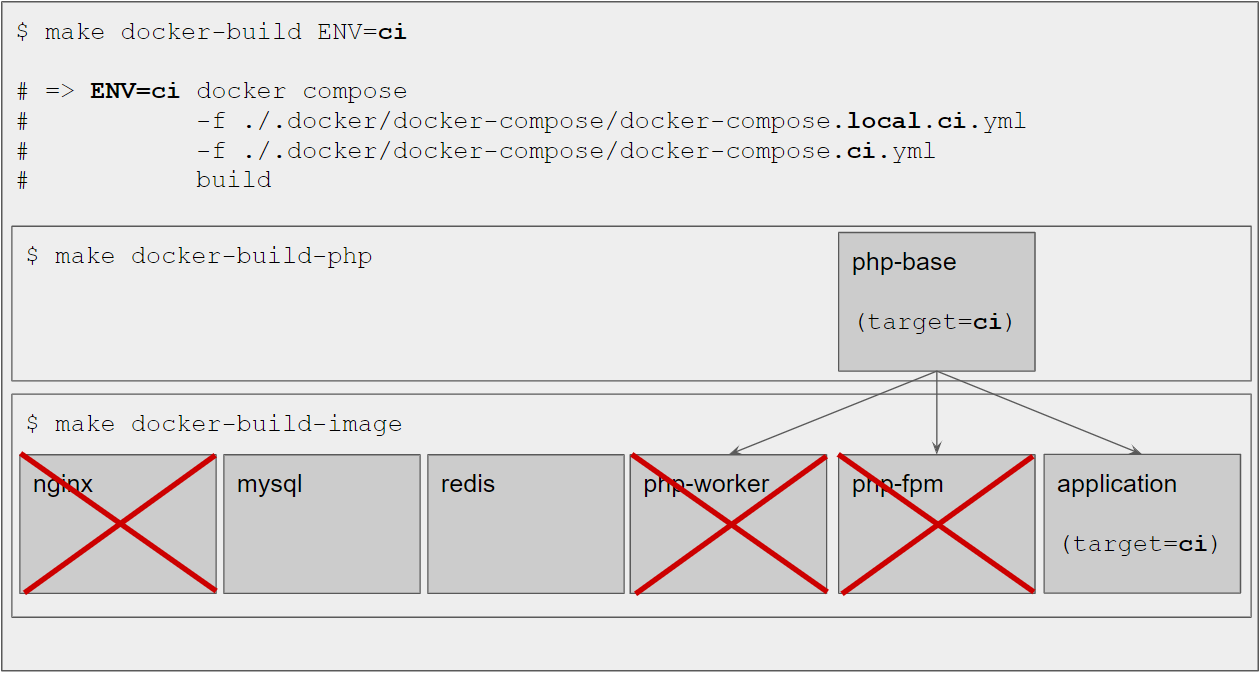
As a first step we need to decide which containers are required and how to provide the
codebase.
Since our goal is running the qa tools and tests, we only need the application php container. The
tests also need a database and a queue, i.e. the mysql and redis containers are required as
well – whereas nginx, php-fpm and php-worker are not required. We’ll handle that through
dedicated docker compose configuration files that only contain the necessary services. This is
explained in more detail in section Compose file updates.
In our local setup, we have shared the codebase between the host system and docker – mainly
because we wanted our changes to be reflected immediately in docker. This isn’t necessary for the
CI use case. In fact we want our CI images as close as possible to our production images – and
those should “contain everything to run independently”. I.e. the codebase should live in the
image – not on the host system. This will be explained in section Use the whole codebase as build context.
Compose file updates
We will not only have some differences between the CI docker setup and the local docker setup
(=different containers), but also in the configuration of the individual services. To accommodate
for that, we will use the following docker compose config files in the .docker/docker-compose/ directory:
docker-compose.local.ci.yml:
holds configuration that is valid for local and ci, trying to keep the config files DRY
docker-compose.ci.yml:
holds configuration that is only valid for ci
docker-compose.local.yml:
holds configuration that is only valid for local
When using docker compose we then need to make sure to include only the required files, e.g. for ci:
So all of those config values will only live in the docker-compose.local.yml file. In fact, there
are only two things that ci needs that local doesn’t:
a volume mount to share only the secret gpg key from the host with the application container
This will be used to collect any files we want to retain from a build (e.g. code coverage
information, log files, etc.)
Adding a health check for mysql
When running the tests for the first time on a CI system, I noticed some weird errors related to the
database:
1) Tests\Feature\App\Http\Controllers\HomeControllerTest::test___invoke with data set "default" (array(), ' <li><a href="?dispatch=fo...></li>')
PDOException: SQLSTATE[HY000] [2002] Connection refused
As it turned out, the mysql container itself was up and running – but the mysql process within the container was not yet ready to accept connections. Locally, this hasn’t been a problem,
because we usually would not run the tests “immediately” after starting the containers – but on CI
this is the case.
healthcheck declares a check that’s run to determine whether or not containers for this service are “healthy”.
Since this healthcheck is also “valid” for local, I defined it in the combined docker-compose.local.ci.yml file:
mysql:
healthcheck:
# Only mark the service as healthy if mysql is ready to accept connections
# Check every 2 seconds for 30 times, each check has a timeout of 1s
test: mysqladmin ping -h 127.0.0.1 -u $$MYSQL_USER --password=$$MYSQL_PASSWORD
timeout: 1s
retries: 30
interval: 2s
When starting the docker setup, docker ps will now add a health info to the STATUS:
$ make docker-up
$ docker ps
CONTAINER ID IMAGE STATUS NAMES
b509eb2f99c0 dofroscra/application-ci:latest Up 1 seconds dofroscra_ci-application-1
503e52fd9e68 mysql:8.0.28 Up 1 seconds (health: starting) dofroscra_ci-mysql-1
# a couple of seconds later
$ docker ps
CONTAINER ID IMAGE STATUS NAMES
b509eb2f99c0 dofroscra/application-ci:latest Up 13 seconds dofroscra_ci-application-1
503e52fd9e68 mysql:8.0.28 Up 13 seconds (healthy) dofroscra_ci-mysql-1
Note the (health: starting) and (healthy) infos for the mysql service.
FYI: We could also use the depends_on property with a condition: service_healthy on the application container so that docker compose would
only start the container once the mysql service is healthy:
However, this would “block” the make docker-up until mysql is actually up and running. In
our case this is not desirable, because we can do “other stuff” in the meantime (namely: run the qa checks, because they don’t require a database) and thus save a couple of seconds on each CI
run.
in the Dockerfile of a service, define the ENV as a build stage. E.g. in .docker/images/php/base/Dockerfile
FROM base as ci
# ...
So to enable the new ci environment, we need to modify the Dockerfiles for the php-base and
the application image.
Build stage ci in the php-base image
Use the whole codebase as build context
As mentioned in section Docker changes we want to “bake” the codebase into
the ci image of the php-base container. Thus, we must change the context property in .docker/docker-compose/docker-compose-php-base.ymlto not only use the .docker/ directory
but instead the whole codebase. I.e. “dont use ../ but ../../“:
# File: .docker/docker-compose/docker-compose-php-base.yml
php-base:
build:
# pass the full codebase to docker for building the image
context: ../../
Build the dependencies
The composer dependencies must be set up in the image as well, so we introduce a new stage
stage in .docker/images/php/base/Dockerfile. The most trivial solution would look like this:
copy the whole codebase
run composer install
FROM base as ci
COPY . /codebase
RUN composer install --no-scripts --no-plugins --no-progress -o
However, this approach has some downsides:
if any file in the codebase changes, the COPY . /codebase layer will be invalidated. I.e.
docker could not use the layer cache
which also means that every layer afterwards cannot use the cache as well. In consequence the composer install would run every time – even when the composer.json file doesn’t change.
composer itself uses a cache for
storing dependencies locally so it doesn’t have to download dependencies that haven’t changed.
But since we run composer installin Docker, this cache would be “thrown away” every time
a build finishes. To mitigate that, we can use --mount=type=cache
to define a directory that docker will re-use between builds:
Contents of the cache directories persists between builder invocations without invalidating
the instruction cache.
Keeping those points in mind, we end up with the following instructions:
# File: .docker/images/php/base/Dockerfile
# ...
FROM base as ci
# By only copying the composer files required to run composer install
# the layer will be cached and only invalidated when the composer dependencies are changed
COPY ./composer.json /dependencies/
COPY ./composer.lock /dependencies/
# use a cache mount to cache the composer dependencies
# this is essentially a cache that lives in Docker BuildKit (i.e. has nothing to do with the host system)
RUN --mount=type=cache,target=/tmp/.composer \
cd /dependencies && \
# COMPOSER_HOME=/tmp/.composer sets the home directory of composer that
# also controls where composer looks for the cache
# so we don't have to download dependencies again (if they are cached)
COMPOSER_HOME=/tmp/.composer composer install --no-scripts --no-plugins --no-progress -o
# copy the full codebase
COPY . /codebase
RUN mv /dependencies/vendor /codebase/vendor && \
cd /codebase && \
# remove files we don't require in the image to keep the image size small
rm -rf .docker/ && \
# we need a git repository for git-secret to work (can be an empty one)
git init
FYI: The COPY . /codebase step doesn’t actually copy “everything in the repository”, because we
have also introduced a .dockerignore file to exclude some files from being included in the
build context – see section .dockerignore.
Some notes on the final RUN step:
rm -rf .docker/ doesn’t really save “that much” in the current setup – please take it more
as an example to remove any files that shouldn’t end up in the final image (e.g. “tests in a
production image”)
the git init part is required because we need to decrypt the secrets later – and git-secret requires a git repository (which can be empty). We can’t decrypt the secrets
during the build, because we do not want decrypted secret files to end up in the image.
When tested locally, the difference between the trivial solution and the one that makes use of
layer caching is ~35 seconds, see the results in the Performance section.
Create the final image
As a final step, we will rename the current stage to codebase and copy the “build
artifact” from that stage into our final ci build stage:
FROM base as codebase
# build the composer dependencies and clean up the copied files
# ...
FROM base as ci
COPY --from=codebase --chown=$APP_USER_NAME:$APP_GROUP_NAME /codebase $APP_CODE_PATH
Why are we not just using the previous stage directly as ci?
That does not only save us some layers, but also allows us to get rid of
files like the .docker/ directory. We needed that directory in the build context because
some files where required in other parts of the Dockerfile (e.g. the php ini files), so we
can’t exclude it via .dockerignore. But we can remove it in the codebase stage – so it will NOT
be copied over and thus not end up in the final image. If we wouldn’t have the codebase stage,
the folder would be part of the layer created when COPYing all the files from the build context
and removing it via rm -rf .docker/ would have no effect on the image size.
Currently, that doesn’t really matter, because the building step is super simple (just a composer install) – but in a growing and more complex codebase you can easily
save a couple MB.
To be concrete, the multistage build has 31 layers and the final layer containing the
codebase has a size of 65.1MB.
$ docker image history -H dofroscra/application-ci
IMAGE CREATED CREATED BY SIZE COMMENT
d778c2ee8d5e 17 minutes ago COPY /codebase /var/www/app # buildkit 65.1MB buildkit.dockerfile.v0
^^^^^^
<missing> 17 minutes ago WORKDIR /var/www/app 0B buildkit.dockerfile.v0
<missing> 17 minutes ago COPY /usr/bin/composer /usr/local/bin/compos… 2.36MB buildkit.dockerfile.v0
<missing> 17 minutes ago COPY ./.docker/images/php/base/.bashrc /root… 395B buildkit.dockerfile.v0
<missing> 17 minutes ago COPY ./.docker/images/php/base/.bashrc /home… 395B buildkit.dockerfile.v0
<missing> 17 minutes ago COPY ./.docker/images/php/base/conf.d/zz-app… 196B buildkit.dockerfile.v0
<missing> 17 minutes ago COPY ./.docker/images/php/base/conf.d/zz-app… 378B buildkit.dockerfile.v0
<missing> 17 minutes ago RUN |8 APP_USER_ID=10000 APP_GROUP_ID=10001 … 1.28kB buildkit.dockerfile.v0
<missing> 17 minutes ago RUN |8 APP_USER_ID=10000 APP_GROUP_ID=10001 … 41MB buildkit.dockerfile.v0
<missing> 18 minutes ago ADD https://php.hernandev.com/key/php-alpine… 451B buildkit.dockerfile.v0
<missing> 18 minutes ago RUN |8 APP_USER_ID=10000 APP_GROUP_ID=10001 … 62.1MB buildkit.dockerfile.v0
<missing> 18 minutes ago ADD https://gitsecret.jfrog.io/artifactory/a… 450B buildkit.dockerfile.v0
<missing> 18 minutes ago RUN |8 APP_USER_ID=10000 APP_GROUP_ID=10001 … 4.74kB buildkit.dockerfile.v0
<missing> 18 minutes ago ENV ENV=ci 0B buildkit.dockerfile.v0
<missing> 18 minutes ago ENV ALPINE_VERSION=3.15 0B buildkit.dockerfile.v0
<missing> 18 minutes ago ENV TARGET_PHP_VERSION=8.1 0B buildkit.dockerfile.v0
<missing> 18 minutes ago ENV APP_CODE_PATH=/var/www/app 0B buildkit.dockerfile.v0
<missing> 18 minutes ago ENV APP_GROUP_NAME=application 0B buildkit.dockerfile.v0
<missing> 18 minutes ago ENV APP_USER_NAME=application 0B buildkit.dockerfile.v0
<missing> 18 minutes ago ENV APP_GROUP_ID=10001 0B buildkit.dockerfile.v0
<missing> 18 minutes ago ENV APP_USER_ID=10000 0B buildkit.dockerfile.v0
<missing> 18 minutes ago ARG ENV 0B buildkit.dockerfile.v0
<missing> 18 minutes ago ARG ALPINE_VERSION 0B buildkit.dockerfile.v0
<missing> 18 minutes ago ARG TARGET_PHP_VERSION 0B buildkit.dockerfile.v0
<missing> 18 minutes ago ARG APP_CODE_PATH 0B buildkit.dockerfile.v0
<missing> 18 minutes ago ARG APP_GROUP_NAME 0B buildkit.dockerfile.v0
<missing> 18 minutes ago ARG APP_USER_NAME 0B buildkit.dockerfile.v0
<missing> 18 minutes ago ARG APP_GROUP_ID 0B buildkit.dockerfile.v0
<missing> 18 minutes ago ARG APP_USER_ID 0B buildkit.dockerfile.v0
<missing> 2 days ago /bin/sh -c #(nop) CMD ["/bin/sh"] 0B
<missing> 2 days ago /bin/sh -c #(nop) ADD file:5d673d25da3a14ce1… 5.57MB
The non-multistage build has 32 layers and the final layer(s) containing the
codebase have a combined size of 65.15MB (60.3MB + 4.85MB).
$ docker image history -H dofroscra/application-ci
IMAGE CREATED CREATED BY SIZE COMMENT
94ba50438c9a 2 minutes ago RUN /bin/sh -c COMPOSER_HOME=/tmp/.composer … 60.3MB buildkit.dockerfile.v0
<missing> 2 minutes ago COPY . /var/www/app # buildkit 4.85MB buildkit.dockerfile.v0
^^^^^^
<missing> 31 minutes ago WORKDIR /var/www/app 0B buildkit.dockerfile.v0
<missing> 31 minutes ago COPY /usr/bin/composer /usr/local/bin/compos… 2.36MB buildkit.dockerfile.v0
<missing> 31 minutes ago COPY ./.docker/images/php/base/.bashrc /root… 395B buildkit.dockerfile.v0
<missing> 31 minutes ago COPY ./.docker/images/php/base/.bashrc /home… 395B buildkit.dockerfile.v0
<missing> 31 minutes ago COPY ./.docker/images/php/base/conf.d/zz-app… 196B buildkit.dockerfile.v0
<missing> 31 minutes ago COPY ./.docker/images/php/base/conf.d/zz-app… 378B buildkit.dockerfile.v0
<missing> 31 minutes ago RUN |8 APP_USER_ID=10000 APP_GROUP_ID=10001 … 1.28kB buildkit.dockerfile.v0
<missing> 31 minutes ago RUN |8 APP_USER_ID=10000 APP_GROUP_ID=10001 … 41MB buildkit.dockerfile.v0
<missing> 31 minutes ago ADD https://php.hernandev.com/key/php-alpine… 451B buildkit.dockerfile.v0
<missing> 31 minutes ago RUN |8 APP_USER_ID=10000 APP_GROUP_ID=10001 … 62.1MB buildkit.dockerfile.v0
<missing> 31 minutes ago ADD https://gitsecret.jfrog.io/artifactory/a… 450B buildkit.dockerfile.v0
<missing> 31 minutes ago RUN |8 APP_USER_ID=10000 APP_GROUP_ID=10001 … 4.74kB buildkit.dockerfile.v0
<missing> 31 minutes ago ENV ENV=ci 0B buildkit.dockerfile.v0
<missing> 31 minutes ago ENV ALPINE_VERSION=3.15 0B buildkit.dockerfile.v0
<missing> 31 minutes ago ENV TARGET_PHP_VERSION=8.1 0B buildkit.dockerfile.v0
<missing> 31 minutes ago ENV APP_CODE_PATH=/var/www/app 0B buildkit.dockerfile.v0
<missing> 31 minutes ago ENV APP_GROUP_NAME=application 0B buildkit.dockerfile.v0
<missing> 31 minutes ago ENV APP_USER_NAME=application 0B buildkit.dockerfile.v0
<missing> 31 minutes ago ENV APP_GROUP_ID=10001 0B buildkit.dockerfile.v0
<missing> 31 minutes ago ENV APP_USER_ID=10000 0B buildkit.dockerfile.v0
<missing> 31 minutes ago ARG ENV 0B buildkit.dockerfile.v0
<missing> 31 minutes ago ARG ALPINE_VERSION 0B buildkit.dockerfile.v0
<missing> 31 minutes ago ARG TARGET_PHP_VERSION 0B buildkit.dockerfile.v0
<missing> 31 minutes ago ARG APP_CODE_PATH 0B buildkit.dockerfile.v0
<missing> 31 minutes ago ARG APP_GROUP_NAME 0B buildkit.dockerfile.v0
<missing> 31 minutes ago ARG APP_USER_NAME 0B buildkit.dockerfile.v0
<missing> 31 minutes ago ARG APP_GROUP_ID 0B buildkit.dockerfile.v0
<missing> 31 minutes ago ARG APP_USER_ID 0B buildkit.dockerfile.v0
<missing> 2 days ago /bin/sh -c #(nop) CMD ["/bin/sh"] 0B
<missing> 2 days ago /bin/sh -c #(nop) ADD file:5d673d25da3a14ce1… 5.57MB
Again: It is expected that the differences aren’t big, because the only size savings come from
the .docker/ directory with a size of ~70kb.
There is actually “nothing” to be done here. We don’t need SSH any longer because it is only
required for the SSH Configuration of PhpStorm.
So the build stage is simply “empty”:
ARG BASE_IMAGE
FROM ${BASE_IMAGE} as base
FROM base as ci
FROM base as local
# ...
Though there is one thing to keep in mind: In the local image we used sshd as the entrypoint,
i.e. we had a long running process that would keep the container running. To keep the ci application container running, we must
.dockerignore
The .dockerignore file
is located in the root of the repository and ensures that certain files are kept out of the
Docker build context. This will
speed up the build (because less files need to be transmitted to the docker daemon)
keep images smaller (because irrelevant files are kept out of the image)
The syntax is quite similar to the .gitignore file – in fact I’ve found it to be quite often
the case that the contents of the .gitignore file are a subset of the .dockerignore file. This
makes kinda sense, because you typically wouldn’t want files that are excluded from the
repository to end up in a docker image (e.g. unencrypted secret files). This has also been
noticed by others, see e.g.
but to my knowledge there is currently (2022-04-24) no way to “keep the two files in sync”.
In our case, the content of the .dockerignore file looks like this:
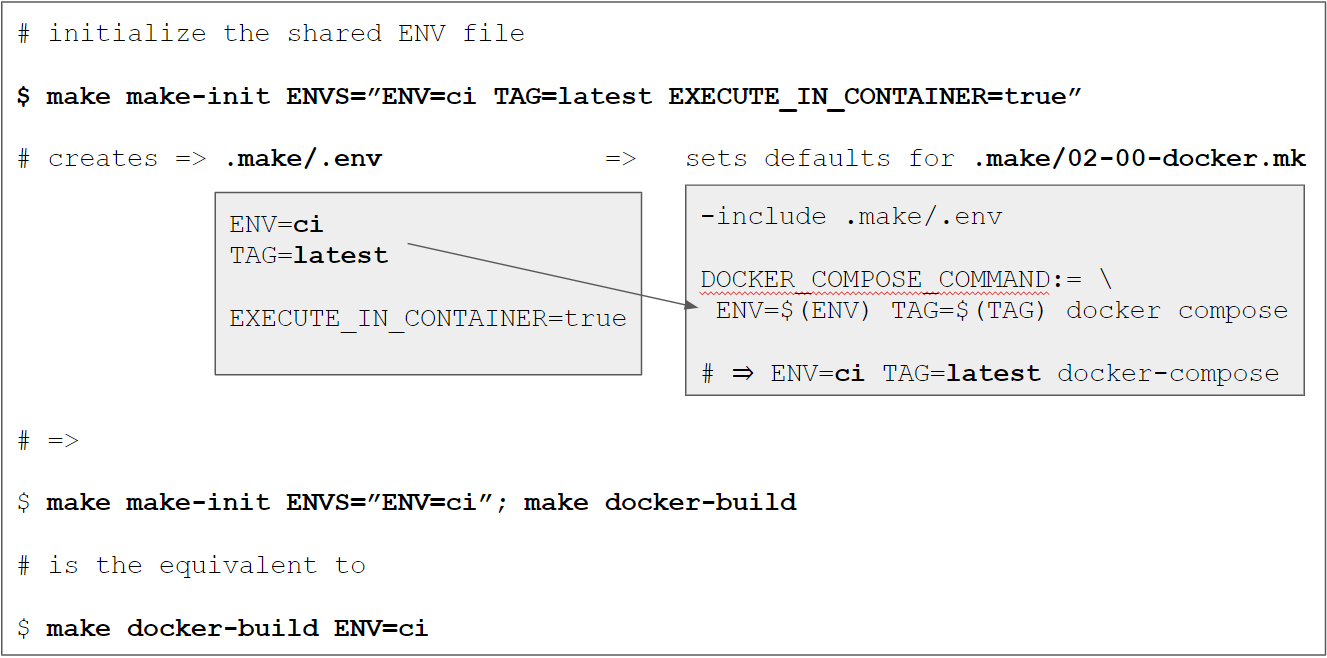
We have introduced the concept of shared variables via .make/.env
previously. It allows us to define variables in one place (=single source
of truth) that are then used as “defaults” so we don’t have to define them explicitly when
invoking certain make targets (like make docker-build). We’ll make use of this concept by
setting the environment to civiaENV=ci and thus making sure that all docker commands use ci “automatically” as well.
In addition, I made a small modification by introducing a second file at .make/variables.env
that is also included in the main Makefile and holds the “default” shared variables. Those
are neither “secret” nor are they likely to be be changed for environment adjustments. The file
is NOT ignored by .gitignore and is basically just the previous .make/.env.example file without
the environment specific variables:
The .make/.env file is still .gitignored and can be initialized with the make-init
target using the ENVS variable:
make make-init ENVS="ENV=ci SOME_OTHER_DEFAULT_VARIABLE=foo"
which would create a .make/.env file with the content
ENV=ci
SOME_OTHER_DEFAULT_VARIABLE=foo
If necessary, we could also override variables defined in the .make/variables.env file,
because the .make/.env is included last in the Makefile:
# File: Makefile
# ...
# include the default variables
include .make/variables.env
# include the local variables
-include .make/.env
The default value for ENVS is ENV=local TAG=latest to retain the same default behavior as
before when ENVS is omitted. The corresponding make-init target is defined in the main Makefile and now looks like this:
ENVS?=ENV=local TAG=latest
.PHONY: make-init
make-init: ## Initializes the local .makefile/.env file with ENV variables for make. Use via ENVS="KEY_1=value1 KEY_2=value2"
@$(if $(ENVS),,$(error ENVS is undefined))
@rm -f .make/.env
for variable in $(ENVS); do \
echo $$variable | tee -a .make/.env > /dev/null 2>&1; \
done
@echo "Created a local .make/.env file"
ENV based docker compose config
As mentioned in section Compose file updates we need to select the
“correct” docker compose configuration files based on the ENV value. This is done in .make/02-00-docker.mk:
# File .make/02-00-docker.mk
# ...
DOCKER_COMPOSE_DIR:=...
DOCKER_COMPOSE_COMMAND:=...
DOCKER_COMPOSE_FILE_LOCAL_CI:=$(DOCKER_COMPOSE_DIR)/docker-compose.local.ci.yml
DOCKER_COMPOSE_FILE_CI:=$(DOCKER_COMPOSE_DIR)/docker-compose.ci.yml
DOCKER_COMPOSE_FILE_LOCAL:=$(DOCKER_COMPOSE_DIR)/docker-compose.local.yml
# we need to "assemble" the correct combination of docker-compose.yml config files
ifeq ($(ENV),ci)
DOCKER_COMPOSE_FILES:=-f $(DOCKER_COMPOSE_FILE_LOCAL_CI) -f $(DOCKER_COMPOSE_FILE_CI)
else ifeq ($(ENV),local)
DOCKER_COMPOSE_FILES:=-f $(DOCKER_COMPOSE_FILE_LOCAL_CI) -f $(DOCKER_COMPOSE_FILE_LOCAL)
endif
DOCKER_COMPOSE:=$(DOCKER_COMPOSE_COMMAND) $(DOCKER_COMPOSE_FILES)
When we now take a look at a full recipe when using ENV=ci with a docker target (e.g. docker-up), we can see that the correct files are chosen, e.g.
We’ve introduced git-secret in the previous tutorial Use git-secret to encrypt secrets in the repository
and used it to store the file passwords.txt encrypted in the codebase. To make sure that the
decryption works as expected on the CI systems, I’ve added a test at tests/Feature/EncryptionTest.php to check if the file exists and if the content is correct.
class EncryptionTest extends TestCase
{
public function test_ensure_that_the_secret_passwords_file_was_decrypted()
{
$pathToSecretFile = __DIR__."/../../passwords.txt";
$this->assertFileExists($pathToSecretFile);
$expected = "my_secret_password\n";
$actual = file_get_contents($pathToSecretFile);
$this->assertEquals($expected, $actual);
}
}
Of course this doesn’t make sense in a “real world scenario”, because the secret value would now
be exposed in a test – but it suffices for now as proof of a working secret decryption.
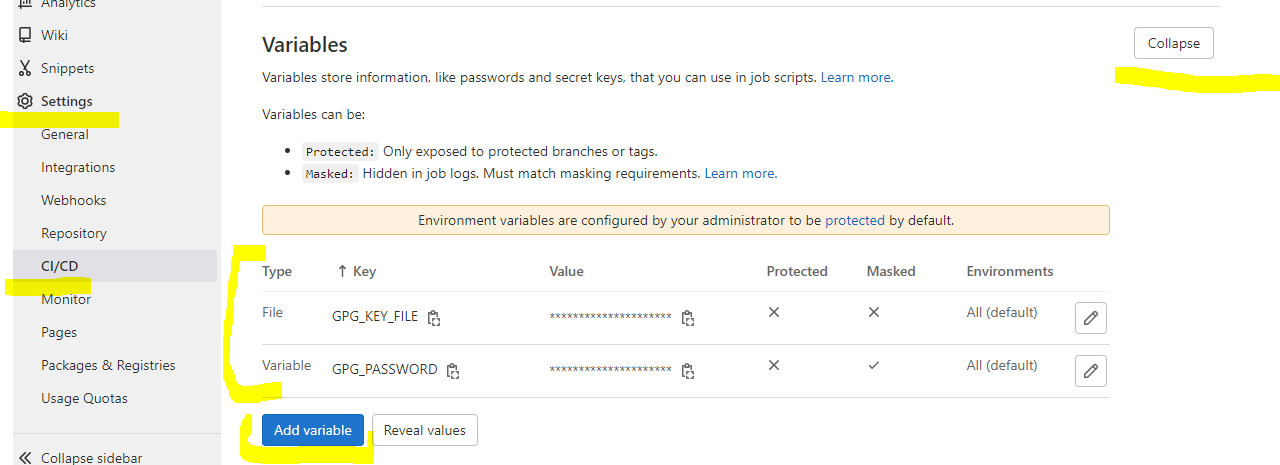
Add a password-protected secret gpg key
I’ve mentioned in Scenario: Decrypt file
that it is also possible to use a password-protected secret gpg key for
an additional layer of security. I have created such a key and stored it in the repository at secret-protected.gpg.example (in a “real world scenario” I wouldn’t do that – but since this
is a public tutorial I want you to be able to follow along completely). The password for that
key is 12345678.
make gpg-init
make secret-add-user EMAIL="[email protected]"
make secret-encrypt
When I now import the secret-protected.gpg.example key, I can decrypt the secrets, though I
cannot use the usual secret-decrypt target but must instead use secret-decrypt-with-password
make secret-decrypt-with-password GPG_PASSWORD=12345678
or store the GPG_PASSWORD in the .make/.env file when it is initialized for CI
make make-init ENVS="ENV=ci TAG=latest EXECUTE_IN_CONTAINER=true GPG_PASSWORD=12345678"
make secret-decrypt-with-password
Create a JUnit report from PhpUnit
I’ve added the --log-junit option
to the phpunit configuration of the test make target in order to create an XML report in the .build/ directory in the .make/01-02-application-qa.mk file:
I.e. each run of the tests will now create a Junit XML report at .build/report.xml. The file is used as an example of a build artifact, i.e.
“something that we would like to keep” from a CI run.
Wrapping up
Congratulations, you made it! If some things are not completely clear by now, don’t hesitate to
leave a comment. You should now have a working CI pipeline for Github (via Github Actions)
and/or Gitlab (via Gitlab pipelines) that runs automatically on each push.
In the next part of this tutorial, we will use terraform to create an infrastructure for
production deployments on GCP and deploy the docker containers there.
Please subscribe to the RSS feed or via email to get automatic
notifications when this next part comes out 🙂
Wanna stay in touch?
Since you ended up on this blog, chances are pretty high that you’re into Software Development
(probably PHP, Laravel, Docker or Google Big Query) and I’m a big fan of feedback and networking.
So – if you’d like to stay in touch, feel free to shoot me an email with a couple of words about yourself and/or
connect with me on LinkedIn or Twitter
or simply subscribe to my RSS feed
or go the crazy route and subscribe via mail
and don’t forget to leave a comment 🙂


 I write more than a few magazine articles each year, and this one is always the hardest. The reason is because nothing else I’m assigned to write about has 50 or more facets on its surface, every one of them capable of changing at a moment’s notice.
I write more than a few magazine articles each year, and this one is always the hardest. The reason is because nothing else I’m assigned to write about has 50 or more facets on its surface, every one of them capable of changing at a moment’s notice. First, let’s get a little terminology thing out of the way. Some absolutists and semanticists like to debate whether that little paper that authorizes CCW (Concealed Carry Weapon) is a “license” or “permit.” Not having time for semantics here, I’ll use them interchangeably. Whether or not we believe that carrying a gun should be a right, we have to understand the reality, our legal system has evolved in such a way that carrying a gun has come to be treated as a privilege, one that requires that specific piece of paper in 48 of the 50 states.
First, let’s get a little terminology thing out of the way. Some absolutists and semanticists like to debate whether that little paper that authorizes CCW (Concealed Carry Weapon) is a “license” or “permit.” Not having time for semantics here, I’ll use them interchangeably. Whether or not we believe that carrying a gun should be a right, we have to understand the reality, our legal system has evolved in such a way that carrying a gun has come to be treated as a privilege, one that requires that specific piece of paper in 48 of the 50 states. This seems to have worked well for the relatively short time it has been in place in Alaska, and it has worked famously well for the long time that it has been in place in Vermont. For many years Vermont has proven to have the lowest crime rate in the nation. You’d think this would tell the other states something about Free Carry.
This seems to have worked well for the relatively short time it has been in place in Alaska, and it has worked famously well for the long time that it has been in place in Vermont. For many years Vermont has proven to have the lowest crime rate in the nation. You’d think this would tell the other states something about Free Carry. Shall-Issue
Shall-Issue Reciprocity
Reciprocity