A print-in-place planetary gear spinner that rotates freely straight off the plate. Two profiles included — standard and heavy outer ring (43g) for added inertia
Every Thursday is #3dthursday here at Adafruit! The DIY 3D printing community has passion and dedication for making solid objects from digital models. Recently, we have noticed electronics projects integrated with 3D printed enclosures, brackets, and sculptures, so each Thursday we celebrate and highlight these bold pioneers!
Have you considered building a 3D project around an Arduino or other microcontroller? How about printing a bracket to mount your Raspberry Pi to the back of your HD monitor? And don’t forget the countless LED projects that are possible when you are modeling your projects in 3D!
3D printing – Adafruit Industries – Makers, hackers, artists, designers and engineers!
Playing Minecraft is better with Bedrock, but it’s not directly available for macOS. Here’s how to get around the limitation and improve your building experience.
Minecraft is one of the longest-running online games that is still actively being played by a lot of people. Originally playable since 2009 and officially released in 2011, it has stood the test of time.
However, while it has been improved over the years, Mac gamers have missed out on one important update: Bedrock Edition. It’s a version that is available on many other platforms, but never made its way to macOS.
Though you can continue using the original Java version on Mac, it is possible to get Bedrock working. It takes a little work, a GitHub project, and buying the game from the Google Play Store.
What is Minecraft Bedrock?
The original version of Minecraft was made in Java, which enabled it to be easily ported to multiple platforms without much trouble. It’s also a version that is very easily modded by the community, without necessarily requiring permission from Microsoft beforehand.
However, the Java edition has a key issue, in that it’s not natively built for any specific platforms. It wasn’t really intended to build a game as complex as Minecraft at all.
As an interpreted language, Java has to be compiled into an intermediate "bytecode" format before being run by a Java Virtual Machine. This just-in-time interpretation means that processing performance is impacted directly compared to a compiled native version.
There is also the issue of the earliest iterations of Minecraft being developed by Markus "Notch" Persson, and later by his studio, Mojang. Eventually, Microsoft got involved with its purchase of the studio in 2014.
Tim Cook introduced Minecraft on Apple TV in 2016. It survived until 2018.
Since it was made by Notch alone at first, it meant that there were elements of code that he would be able to manage, but a team of developers would struggle with. After years of development, there was enough technical debt to prompt a rethink by those managing the game.
Cue the development of a C++ version, which started off with a demo of Pocket Edition in 2011. Over time, the codebase was expanded and improved upon, until it was rebranded as Bedrock Edition in 2022.
With that change, it became a more widely available version, including a release for Windows. The change also made it possible to create versions of Minecraft for other platforms, and for the games to more easily communicate with each other between different platforms.
The change also meant Microsoft could incorporate an in-game store, monetizing their expensive acquisition, as well as other elements.
Working around the limits
While there’s Minecraft: Bedrock Edition for Windows, Xbox, PlayStation, Nintendo Switch, Android, and iOS, there is not a specific macOS version. You also can’t use the workaround of buying the iOS version and trying the iPadOS game in macOS, as that has been disabled.
There’s nothing wrong with sticking to the Java edition of Minecraft on your Mac, but there are ways to use the Bedrock edition. Just not by officially buying a macOS app.
A legitimate way of doing it is through using Windows on your Mac. Software like Parallels will let you run the Windows version of Minecraft Bedrock, but you again get that dreaded performance penalty.
Phases of installing the Minecraft Launcher
There’s also the possibility of sideloading an iOS or iPadOS version, but we’d rather not anger Apple with that method.
Another way is to use the Linux Minecraft Launcher. There’s a build available for macOS, which works using the Android version of the game.
If you happen to have a Google account with Minecraft Bedrock already on it, you can use that. If not, you will have to pay for it from the Google Play Store.
This can be a bit tricky if you don’t have an Android device on the account. By running the launcher and trying to download the game without the purchased version on your Google account, it will come up as a device under the Google Play Store.
How to run Minecraft Bedrock Edition on a Mac using Linux Minecraft Launcher
Open the DMG. Drag the Minecraft Bedrock Launcher to the Applications folder shortcut. After the transfer, you can close the installer and unmount the DMG.
Open Minecraft Bedrock Launcher. If you’re blocked from opening, head to System Settings then Privacy & Security, then next to the blocked app warning, click Open Anyway.
On the Linux Minecraft Launcher changelog, click Continue.
Log into the Google account associated with the Android game’s purchase. You will be asked to create a password to save the credentials, then click Save & Complete Login.
Click Download And Play.
Once completed, the game will run in a window, which you can make larger from the edges. There are also video settings available, both in a menu at the top and in the game’s settings.
You should see this if installing the Minecraft launcher goes correctly.
Feel free to push things like the draw distance and frame rate up, as well as the resolution. It’s arguably one of the best features of Bedrock edition over Java, and you can use it to the fullest on your Mac desktop.
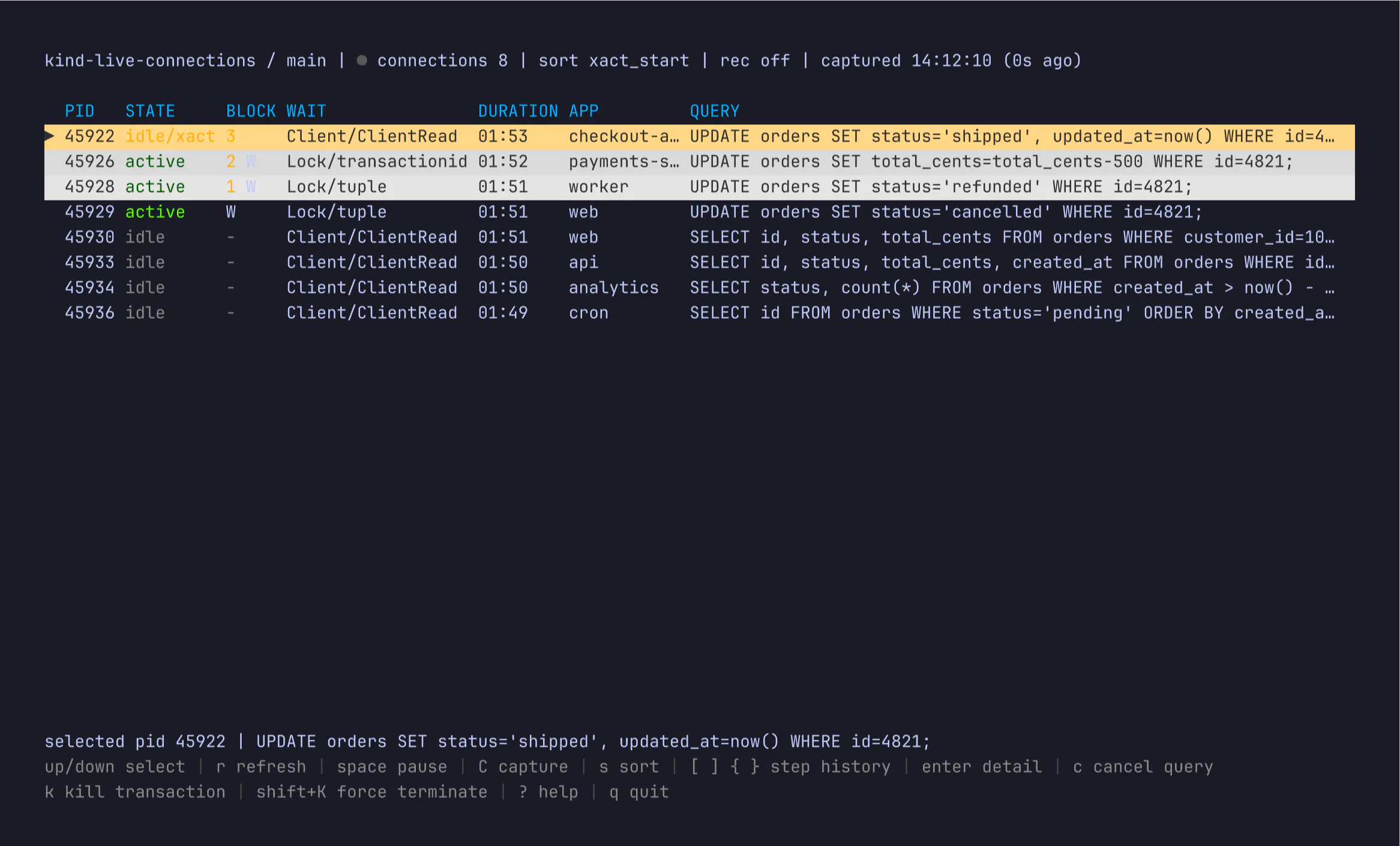
Much of database debugging eventually turns into carefully inspecting what each connection is doing. In Postgres, this means watching pg_stat_activity in a loop. In Vitess, it means watching SHOW FULL PROCESSLIST the same way.
Tools like Query Insights are useful for exploring the recent history of queries. They can tell you what was slow, what’s consuming resources, and where to spend tuning effort.
But during an active incident, the questions are more immediate. What’s happening this second? Did the last thing I changed fix it?
Here’s a manual version of this workflow in Postgres:
SELECT pid, state, wait_event_type, wait_event, now() - xact_start AS tx_age, pg_blocking_pids(pid) AS blocked_by, left(query, 60) AS queryFROM pg_stat_activityWHERE state <> 'idle'ORDER BY tx_age DESC;
Run it over and over again in a terminal and it’s a pretty effective view of the database.
It’s also a rough interface.
You’re scanning rows as they move around, trying to reconstruct what’s blocking progress, and hunting for the one detail that actually matters for the fix.
The worst version of this problem is when you can’t connect at all because the database has exhausted all of its connections. You can’t fix what you can’t connect to.
That workflow shaped the design of Connections, a new feature of the pscale CLI available today for PlanetScale Postgres and Vitess (MySQL) databases.
Here’s that same debugging flow using the new pscale branch connections top functionality with a Postgres database, instead of pasting that pg_stat_activity query in a loop and comparing output:
pscale branch connections top <database> <branch>
Connections opens an interactive live view that refreshes about once a second and sorts the sessions most likely to matter toward the top. There are keyboard shortcuts to navigate the list of connections and inspect each one in more detail.
Columns in the list include the Process ID (PID), status, number of blocked queries, why they’re waiting, and more.
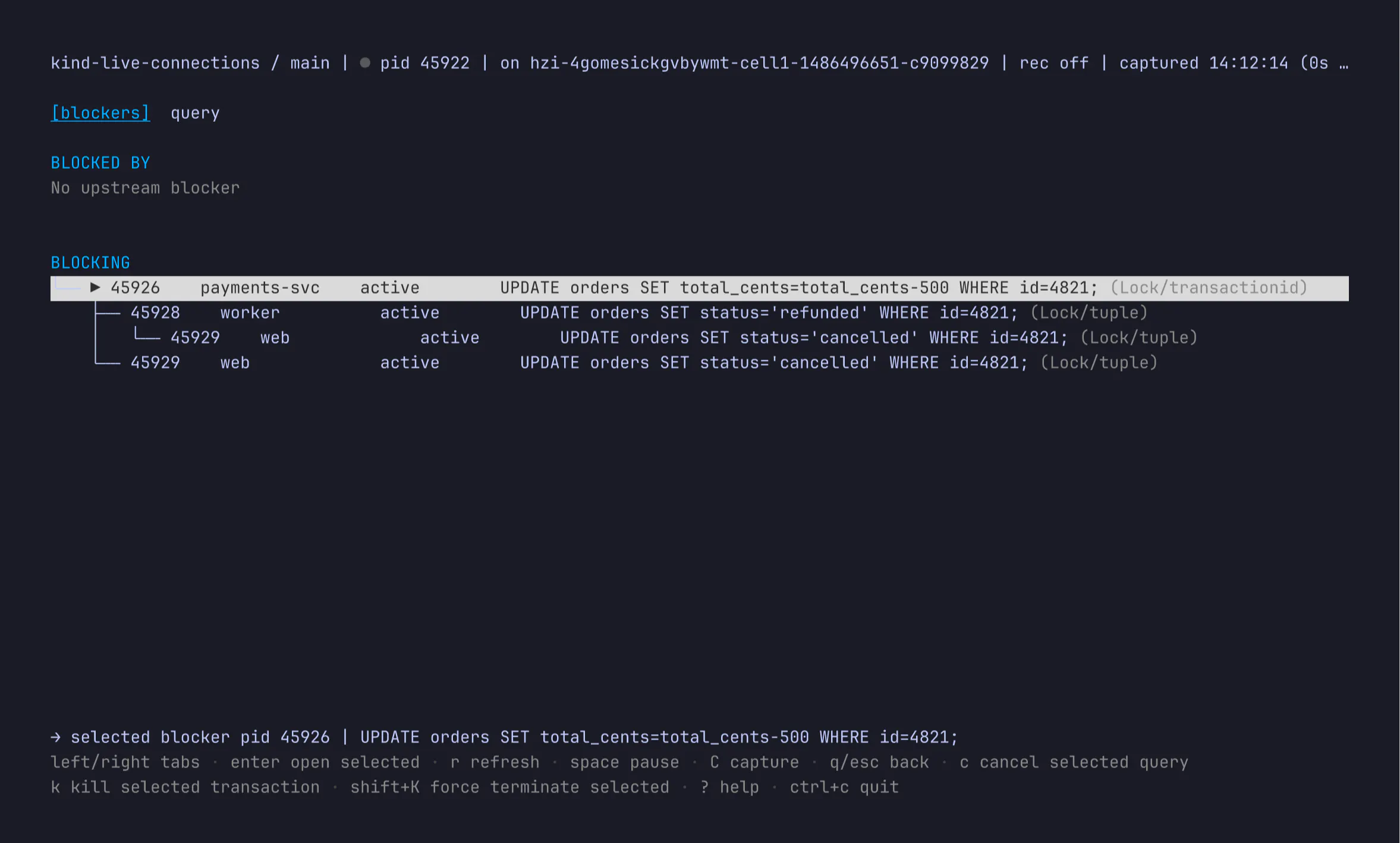
Say your writes are backing up and the app is timing out. In this example, an idle transaction from checkout-api is holding up three other writes. Open the row, and the blocker tree shows the queue behind it:
From there you can decide whether the right fix is to cancel a query or terminate the connection. You no longer need to remember the syntax of pg_stat_activity, retrace the blocker chain by hand or copy and paste PIDs around.
Another problem with running that query in a loop is that the interesting moment flies by. Connections keeps a recent rolling history, so you can pause, step forward and backward with [ and ], and see how the state has changed.
You can also capture a session to a file. You can record everything you see in Connections by pressing C. This includes the recent history already buffered in memory and keeps appending from there. Perfect for handing off logs to agents to assist with debugging.
That also makes it easier to write a postmortem, share what happened with a teammate, or replay the same view later instead of describing it from memory.
The stress of debugging an active incident is worse when you can’t even connect to the database yourself.
Connections uses a reserved administrative connection, so the inspection path still works when regular application connections are exhausted.
Managed databases should remove the need to SSH into a box, not remove your ability to debug an incident.
You can still get in, see what is running, and act from there.
The PlanetScale CLI’s new Connections feature also works with Vitess databases (MySQL). In this case, the live view is the PlanetScale version of watching SHOW FULL PROCESSLIST, with the ability to cancel the current query or terminate the connection from this unified interface.
The main difference is scope. Vitess connections are shown for one keyspace (and one shard) at a time. If a branch has multiple keyspaces, or a sharded keyspace, pass --keyspace and --shard to choose the tablet:
pscale branch connections top <database> <branch> --keyspace <keyspace> --shard <shard>
The same live monitoring, pause, history, capture, and replay workflow applies. The actions are MySQL-specific: canceling a query runs KILL QUERY, and terminating a connection runs KILL. See the Inspect live Vitess connections guide for the full command behavior.
Connections is available for PlanetScale Postgres and Vitess. Update to the latest version of pscale and run:
Austrian company Fischer Development has taken a notably different approach to pistol suppression. Where virtually every other suppressor on the market threads onto the barrel, the FD-Silencer mounts to the frame accessory rail: no barrel threading, no gunsmithing, no modifications to the weapon whatsoever. One click onto the rail and you’re done. I’ve tried it, and it works!
The result is a suppressor that looks like it was designed for a dystopian sci-fi franchise rather than a civilian shooting range, which is part of the appeal. Mounted on a Glock 17 or HK SFP9, the overall silhouette transforms the pistol into something Robocop or Judge Dredd would holster without a second thought. The FD-Silencer adds around 165mm in front of the muzzle and sits low along the frame, giving the whole package an unmistakably aggressive, angular profile.
The engineering is clever beyond the aesthetics. Because it doesn’t thread to the barrel, it works with subsonic and supersonic ammunition alike, doesn’t affect the point of impact, and lets you use your standard iron sights without any riser or adapter. The tradeoff is weight (at 380 grams, it’s a substantial addition), but for a range toy or a duty pistol in jurisdictions where suppressors are permitted, the no-modification approach is genuinely practical. Coverage includes the Glock 17, 19, 34, 45, and the HK SFP9, in black or FDE. Which one would you go for?
Fischer Development is based in Austria. Make of that what you will: Glock country producing a suppressor that makes a Glock look like it belongs in Old Detroit.
Journalist Johnny Harris explores the seldom-discussed period from 1776 to 1789, when the first attempt to unite the 13 colonies failed miserably, and how we ended up with constructs like the electoral college. During those years, the young nation operated under the Articles of Confederation, leaving Congress with little power to govern, tax, or solve disputes.
Superfeet is now letting customers scan their feet with an iPhone to order custom 3D-printed insoles directly through superfeet.com. The service requires no separate app download and works on iPhone 13 or newer running iOS 26.
The mobile experience mirrors what’s been available at select specialty run retailers, where staff guide customers through a foot scan in person. Now that same scan can happen at home. After completing the guided scan, users can review their foot profile, including arch height and shoe size, preview a 3D rendering of their insoles, and add custom engraving to the heel. The finished data gets sent to Superfeet’s 3D-printing facility in Bellingham, Wash., where the insoles are manufactured to the customer’s specifications.
Credit: Superfeet
“This evolution allows us to deliver a level of individualized engineering that was once only possible through specialized in-person experiences, unlocking access to our most advanced one-of-one custom technology,” said Superfeet CEO Trip Randall. “By putting this power into the hands of consumers, we ensure that whether you are at home or on the go, the highest standard of personalized support is just a few clicks away.”
The insoles come in two foam options. SuperRev is a lightweight, thin design suited for tighter-fitting performance footwear. SuperRev Max uses a supercritical beaded foam matrix built for high-rebound cushioning and fits better in roomier running shoes. Both pair with a 3D-printed support cap shaped from the customer’s scan. That cap includes a custom arch profile matched to each foot’s geometry, a stability lattice that adjusts thickness based on body mass, and a heel cutout designed to reduce impact forces.
Customers who don’t have a compatible iPhone or who’d rather work with a specialist can still get scanned at select specialty run retailers nationwide. Superfeet hasn’t disclosed how many retail locations currently offer the in-store service.
Johnny FPV is known for capturing cinematic aerial videos with his precision drone flying. He was approached by Bobcat to shoot a video of their top-of-the-line ZT7000 lawnmower. With a Kawasaki FX engine, this ride-on, zero-turn mower can hit speeds up to 19 mph when it’s not cutting grass, and Johnny’s video makes this thing look like a true backyard beast.
Glock helped change what shooters expected from a modern service pistol: lighter weight, higher capacity, fewer controls, and rugged reliability. IMG Ryan Hodges
In today’s firearms market, it’s almost impossible to imagine a time before Glock. When polymer-framed semi-automatic pistols were not the norm.
Modern shooters can choose from an enormous variety of calibers, modular grip frames, optics-ready slides, and specialized features tailored for military service, law enforcement, self-defense, and recreational use. But turn the clock back to the mid-1980s, and the handgun landscape looked entirely different.
From the early 19th century onward, the revolver was America’s dominant handgun. Beginning with black-powder six-shooters and continuing through Samuel Colt’s 1873 “Peacemaker,” revolvers earned a reputation for mechanical reliability, cost-effective manufacturing, and cultural significance. These traits kept revolvers relevant well into the 20th century, even as many European nations transitioned to semi-automatic pistols. Law enforcement agencies continued issuing revolvers through the 1980s—typically short-barreled Smith & Wesson models chambered in .38 Special or .357 Magnum. While these guns lacked the ammunition capacity of contemporary semi-automatics, their simplicity and reliability kept them in police holsters for decades.
Manufacturers still built most semi-automatic pistols around traditional hammer-fired designs. They often featured heavy steel frames, blued finishes, and wood grips. Gunmakers treated them as finely machined mechanical tools—often beautifully crafted, but rooted in long-established design conventions. Companies such as Colt, SIG Sauer, Beretta, and Smith & Wesson dominated the market. Yet shifting law enforcement needs, evolving military requirements, and the unconventional thinking of an Austrian engineer would soon disrupt the handgun world forever.
By the late 1970s, the Austrian Army realized it needed a replacement for its aging World War II-era Walther P38. The new pistol needed to exceed the P38’s performance while meeting strict criteria: higher ammunition capacity, a maximum weight of 28 ounces, a light and consistent trigger pull, and a total parts count of no more than forty. These requirements pushed far beyond the standards of most handguns of the time.
Enter Gaston Glock. At the time, Glock operated a small manufacturing business in Vienna. Using a secondhand Russian metal press, the company produced brass door and window fittings before securing military contracts for field knives and bayonets. During visits to the Austrian Defense Ministry, Glock overheard discussions about the military’s search for a new service pistol. He instantly recognized an opportunity. But what did a curtain rod manufacturer know about designing firearms? Nothing—and that was precisely where Glock found success.
Unlike traditional firearms manufacturers, Glock was not constrained by decades of design convention or industry assumptions.
Glock later explained, “That I knew nothing was my advantage.”
Glock approached the challenge with methodical intensity. He purchased and disassembled a variety of modern handguns—including the Beretta 92F, SIG Sauer P220, CZ 75, and Walther P38—to study their strengths and weaknesses. In May 1980, he invited several firearms experts to his vacation home in Velden, Austria, and asked a simple question: “What would you want in a pistol of the future?” Their insights helped shape a revolutionary handgun design.
Rather than relying on traditional manufacturing techniques, Glock focused entirely on meeting the Austrian military’s performance requirements.
Simplicity, durability, light weight, and reliability became the guiding principles behind the pistol.
Glock’s use of a polymer frame became one of the pistol’s most significant innovations. Having worked with high-strength polymer materials while producing handles and sheaths for his military knives, Glock recognized the material’s potential for firearms manufacturing. Polymer construction dramatically reduced weight and manufacturing cost compared to the steel-framed pistols dominating the market.
Glock also broke from convention with his “Safe Action” trigger system. Instead of an external hammer and manual safety, the pistol used a striker-fired mechanism and a trigger-mounted safety lever. This design reduced snagging during the draw and lowered the chance of accidental discharges caused by drops or improper handling.
“Safe Action” trigger system. IMG Ryan Hodges
Development moved remarkably fast. Within a year, Glock produced a working prototype. On April 30, 1981, he filed a patent application for the seventeenth iteration of his design, which Glock simply named the Glock 17.
The Austrian Trials
The Glock 17’s unconventional design immediately drew skepticism. A polymer-framed pistol with no manual safety, no external hammer, and a striker-fired system seemed radical—especially coming from a manufacturer with no firearms pedigree.
During the Austrian trials, Glock’s pistol competed against established giants including Heckler & Koch, SIG Sauer, Beretta, Fabrique Nationale, and Steyr. The tests were grueling. Testers subjected each handgun to heat, ice, sand, mud, and a 10,000-round endurance test. Officials also evaluated the pistols on weight, capacity, and parts count.
The Glock 17 excelled in the tests. It malfunctioned only once during the firing trial and weighed just 23 ounces, making it the lightest pistol in the competition. The polymer frame and rolled-steel slide held up to abuse far better than skeptics expected.
Although the Glock lacked traditional aesthetic appeal, its utilitarian design perfectly matched the Austrian military’s requirements. Impressed by its performance and low manufacturing cost, the Ministry of Defense ordered 20,000 Glock 17 pistols in 1983. What began as a military contract would soon reshape the global handgun market.
Glock 19 Gen 4 Field Stripped. IMG Ryan Hodges
Glock Comes to America
Winning the Austrian trials was only the beginning. To reach its full potential, Glock needed to break into the American market.
While on a business trip in 1984, Austrian-American firearms salesman Karl Walter first encountered the Glock 17 and became intrigued by its design. At the time, many U.S. police departments still relied on revolvers, and Walter quickly recognized the Glock as a modern solution to growing law enforcement challenges.
Walter and American gun writer Peter G. Kokalis soon arranged a meeting with Gaston Glock. The conversation proved fruitful, and their partnership led to the establishment of Glock’s U.S. operations in Smyrna, Georgia, in 1985.
However, Glock’s introduction to the American market proved rocky from the start. Media outlets fueled fears about the “plastic gun,” claiming it could evade X-ray machines and pose a significant threat to aviation security. Congressional concern soon followed. Ultimately, authorities debunked the claims—but the controversy generated massive publicity. Ironically, the negative attention benefited Glock enormously. Millions of Americans suddenly became familiar with the strange Austrian pistol made largely from polymer. Law enforcement agencies took notice, and civilian shooters did too.
Glock 19 Gen 4. IMG Ryan Hodges
The Shift in Police Sidearms
The 1980s saw a sharp rise in violent crime in the United States. Drug trafficking, gang violence, and heavily armed criminals created increasingly dangerous encounters for police. Many departments realized their six-shot revolvers were becoming outmatched.
The turning point came with the infamous 1986 FBI Miami shootout, which left two agents dead and five wounded. Several agents armed with revolvers found themselves badly outgunned during the firefight. The incident accelerated the nationwide shift toward higher-capacity semi-automatic pistols.
The Glock 17 arrived at exactly the right moment. Lightweight, simple, durable, and offering 17+1 rounds, it provided a practical and affordable solution for agencies seeking modern sidearms. The Miami Police Department became one of the first major adopters, ordering 1,100 pistols. Soon, departments across the country followed.
While not the newest gun by Glock, the Gen 3 G17 is still a formidable pistol. IMG Jim Grant
From Duty Holster to Household Name
As Glock pistols spread through American law enforcement, their reputation grew. Shooters appreciated their reliability, simplicity, and ease of maintenance. The pistol’s distinctive appearance and rising popularity also made it a fixture in American pop culture.
Glock reached full pop culture status in Die Hard 2: Die Harder when Bruce Willis’ character John McClane shouted at an airport security guard, “That punk pulled a Glock 7 on me! You know what that is? It’s a porcelain gun made in Germany. Doesn’t show up on your airport X-ray machines, here, and it costs more than you make in a month!”
Nearly every detail in the quote was wrong—but the Glock name had officially entered the American lexicon. Soon, Glocks appeared in action films, television dramas, and rap lyrics. The brand became synonymous with the modern semi-automatic pistol.
Meanwhile, civilian shooters embraced the platform as well. Competitive shooters, instructors, and concealed carriers valued its durability and modularity. A massive aftermarket industry emerged, offering custom sights, triggers, holsters, and slide modifications. By the late 1990s, Glock had become one of the dominant handgun platforms in America.
The Polymer Revolution
Glock’s success did more than create a popular handgun—it changed the direction of the entire firearms industry. Before Glock, shooters viewed polymer-framed pistols with skepticism, and most manufacturers treated striker-fired systems as unconventional. Glock proved that a lightweight, durable, high-capacity polymer pistol could not only compete with traditional steel designs, but often outperform them. Combined with Karl Walter’s aggressive marketing strategy and excellent timing, Glock quickly became one of the most recognizable names in the global firearms industry.
Competitors across the industry soon followed. Smith & Wesson, SIG Sauer, Springfield Armory, FN, Walther, and numerous others introduced their own polymer-framed striker-fired pistols, many heavily influenced by Glock’s design philosophy. To this day, Glock’s design remains one of the most influential handgun developments of the modern era. Modular polymer-framed, striker-fired pistols now dominate the handgun market, and Glock pistols remain among the most widely carried law enforcement sidearms in the world.
Glock didn’t invent every concept found in the Glock 17, but the company combined proven ideas into a simple, reliable, affordable package that redefined consumer expectations.
Sources Referenced:
Barrett, Paul M. Glock: The Rise of America’s Gun. New York: Crown Publishers, 2012.
Ryan is an outdoorsman and firearms enthusiast with over a decade of experience in the industry. He holds a B.A. in History with a concentration in Public History from Roanoke College and was an intern at the Cody Firearms Museum in Cody, Wyoming where he contributed to exhibit development and public education initiatives. He later worked with Taylor’s & Co. in Winchester, Virginia for 9 years, building expertise in historical and reproduction firearms.
An avid hunter and shooter based in Northern Virginia and the West Virginia panhandle, Ryan has a deep appreciation for the intersection of history, firearms, and the natural world. His primary area of focus is 19th-century American firearms, particularly those used during the Civil War and the era of westward expansion. Through his writing, he aims to educate and engage readers by connecting the historical significance of firearms with their enduring legacy in the field today.
Database purchases are often considered just another IT expense. The primary concerns are limited to license fees and sign support contracts. But this mindset ignores hidden costs like downtime, excess capacity, rising renewal fees, and data transfer charges.
The financial sector particularly suffers, as proprietary databases hinder system updates for compliance and real-time AI, impose rigid pricing, and shift operational risk to the buyer.
Procurement leaders are starting to see this problem. Over 74% of Database as a Service (DBaaS) users cite high and unpredictable costs as their top challenge due to proprietary pricing structures. Meanwhile, the open source database market is projected to reach $63.48 billion by 2034, signaling a major industry shift.
Switching to open source databases offers procurement teams better financial control, allowing spending to be measured and predicted like any other asset.
This article provides a framework for procurement leaders to realize the ROI of open source databases. It explains how to move beyond license-focused sourcing to a strategy that prioritizes risk reduction, spend predictability, and vendor optionality.
The procurement blind spot: What database TCO really includes
License fees often become the total cost baseline in many sourcing cycles. But that license cost is only a fraction of the true database Total Cost of Ownership (TCO). The massive operational and strategic costs are hidden beneath the surface. The cost drivers show up in six areas:
Outage and SLA penalties: Downtime incurred due to vendor-managed recovery or architecture constraints.
Forced over-provisioning: Licensing models that require institutions to buy capacity they may not fully use (because licenses are sold in “blocks” or “cores”). If your workload requires 9 cores, you are often forced to pay for 16.
Escalating renewal pricing: Per-core or per-instance fees that climb with infrastructure growth, unrelated to feature value.
Data egress fees and platform taxes: Cloud DBaaS charges for cross-region replication, data exports, backups, and traffic that accumulate unpredictably.
Staffing and operational overhead: Database administrators and Site Reliability Engineers (SREs) dedicating time to tuning, patching, and managing vendor-specific tooling.
Migration and switching costs: The financial and technical burden of moving data if vendor changes or licensing terms shift.
Downtime as a financial liability (Not a technical issue)
Procurement teams may not always be the primary owners of downtime risk, but they often influence it through vendor selection, contract terms, and support coverage. Because outages carry measurable business impact, support responsiveness and recovery capability should be evaluated as a financial exposure.
For example, critical-incident response and restoration expectations must be defined and aligned with the organization’s risk tolerance. If not, the institution may be accepting avoidable financial and operational exposure during high-severity events.
For a bank with three major outages per year, averaging 4 hours each, with a $500K/hour impact:
3 × 4 × $500,000 = $6 million in annual downtime risk
Open source works best when supported by vendor-agnostic experts like Percona’s. It allows procurement to source support that focuses on restoring service across the entire stack, rather than defending a specific piece of software.
Cost predictability vs. vendor-driven cost escalation
Budget forecasting becomes impossible when database costs are unpredictable. Yet proprietary licensing introduces multiple mechanisms that undermine forecast accuracy and negatively affect business success.
The scaling penalty: As your customer base grows and you add more hardware, your software costs increase exponentially because of per-core or per-socket licensing.
Tier creep: You might start on a Standard tier, but as soon as you need a critical security feature like advanced encryption or granular auditing for DORA (Digital Operational Resilience Act) compliance, you are forced into an Enterprise tier that can cost more.
In contrast, open source separates the software cost from growth. If you double your infrastructure to handle peak trading volumes, your software cost remains zero. It lets procurement provide the business with a linear, predictable cost model (you only pay for the infrastructure you use and the expertise required to run it).
Vendor lock-in and contract leverage
The primary objective of a sales team from a proprietary vendor is to make customers more committed to their products. The more vendor-specific features you use, the harder it is for procurement to negotiate when renewing the contract. Over time:
Switching costs add up: Data migration, changing schemas, and application changes create high barriers to leaving.
Vendor leverage grows: As integration deepens, alternatives become more costly, reducing competition in renewal negotiations.
Renewal pricing rises: With fewer alternatives, vendors increase renewal fees, confident that institutions cannot easily leave.
Percona’s research on Redis users shows that nearly 75% have considered or tested alternatives when licensing terms change, but most couldn’t really switch. This is vendor lock-in at its most destructive, as institutions resent the vendor but cannot leave.
Open source gives institutions more options (restores vendor optionality). Procurement can regain power through:
Multi-vendor support: If one support provider underperforms or raises prices, you can move your support contract to another provider without migrating your data.
Deployment flexibility: Open source can run on-premise, in any cloud (AWS, Azure, GCP), or in a hybrid model.
Lower switching costs: Since open source uses standard protocols, it is easier to find talent and tools that work across the stack, and reduce the exit cost of any single relationship.
Operational efficiency as a budget control mechanism
Database operations often increase operating expenses. When teams react to problems rather than prevent them, labor costs rise without notice. Inefficient database management raises labor costs in two ways:
Specialized labor scarcity: Finding a specialist for a proprietary database is expensive.
Reactive engineering: When database performance is poor, teams spend more time fixing issues instead of building new products.
Switching to an open-source system with integrated management tools, like Percona Monitoring and Management, can help the organization save valuable engineering time.
For example, if a 10-person engineering team spends 20% of their time on manual database maintenance, that’s like paying two full-time employees just to keep things running. Improving tools and support reduces this work and provides immediate operational ROI.
Data egress fees: The hidden variable cost
In cloud services, it’s usually free to get your data in, but costs can skyrocket when you want to get your data out. Many managed proprietary DBaaS platforms are designed to trap your data. They make it easy to scale up, but charge massive data egress fees if you want to move that data to a third-party analytics tool or a different cloud provider.
Open source databases, particularly when run on Kubernetes or self-managed infrastructure, give you full control over the data path. With that control, procurement and platform stakeholders can design data flows that reduce unnecessary cross-cloud transfers and help minimize egress fees.
Annualized ROIs Summary for procurement
When presenting the move to open source to the executive team, procurement should frame the benefits across the following financial pillars:
ROI Lever
Procurement outcome
Financial impact
Risk avoidance
Reduced downtime frequency and duration.
Lowered black swan event liability.
Spend control
Removal of license multipliers.
Predictable, linear cost growth.
Leverage
Multi-vendor support options.
Stronger renewal negotiating power.
Productivity
Reduced manual DB management.
Reclaiming expensive engineering hours.
Why open source aligns with procurement objectives
Modern procurement is about governance, compliance, and strategic alignment. Open source databases align with these goals better than proprietary ones:
No licensing premiums for scale or performance. A 10x increase in data does not mean 10x higher license fees.
Transparent, auditable cost structures. Procurement knows exactly what they are paying for.
Support can be competitively sourced. Institutions are not locked into a single software vendor.
Better compliance and security. Open code enables internal security reviews, transparency for auditors, and helps meet regulatory requirements.
Operating open source with procurement-grade assurance
A common objection to open source is that it’s unsupported. Procurement teams need operational assurance, confidence that open source environments meet the same regulatory, availability, and financial standards as proprietary systems.
When evaluating a support partner, procurement should require:
SLA clarity: Specific, contractually backed response and resolution times.
Multi-database coverage: One contract that covers MySQL, PostgreSQL, and MongoDB to reduce contract sprawl.
Regulated-environment experience: A partner who understands PCI-DSS, SOC2, and the high-compliance needs of finance.
Percona meets all of these criteria and offers procurement with a partner that turns technical operations into financial metrics.
Where Percona fits
Percona operationalizes open source databases for regulated, mission-critical environments. It delivers measurable outcomes across four strategic dimensions for procurement teams:
Independent, vendor-neutral support model
Percona provides technology-agnostic support across MySQL, PostgreSQL, MongoDB, MariaDB, and Valkey. It operates independently of cloud providers and database vendors, supporting on premises, cloud, and hybrid environments. This vendor neutrality ensures institutions maintain full control over technology choices without being locked into specific platforms or ecosystems.
Predictable support costs without licensing dependency
Percona’s pricing model decouples support costs from database licensing and creates transparent, forecastable expenses. While proprietary databases force organizations to pay escalating per-core or usage-based fees, Percona’s support subscriptions operate independently of infrastructure growth. For example, organizations like BBVA reduced licensing and support costs while simultaneously improving backup performance by 20% after migrating to Percona Server for MongoDB.
Proven experience supporting regulated financial systems
Percona supports regulated financial systems, including Fortune 500 companies and government agencies, and meets compliance standards such as HIPAA, PCI DSS, GDPR, and DORA EU.
Major financial services implementations include:
Merchant Warrior: Australia’s payments gateway relies on Percona for critical MySQL availability, supporting millions of transactions across 30,000+ customers.
MultiPay and Bukalapak: Financial services and e-commerce platforms leveraging Percona’s support to maintain high availability and optimize deployment performance.
Conclusion: Database performance as a spend control strategy
Databases have evolved from technical infrastructure into financial assets. Their uptime, performance, and flexibility influence costs, vendor leverage, and operational resilience. For procurement, buying databases is a strategic investment to control expenses and manage risks.
Organizations gain predictable costs, measurable ROI, vendor optionality, and long-term operational control by choosing open-source databases and partnering with Percona. These advantages compound over time, while proprietary systems often fall short.
Get started with Percona Operators and see how consistency, scale, and freedom come together.