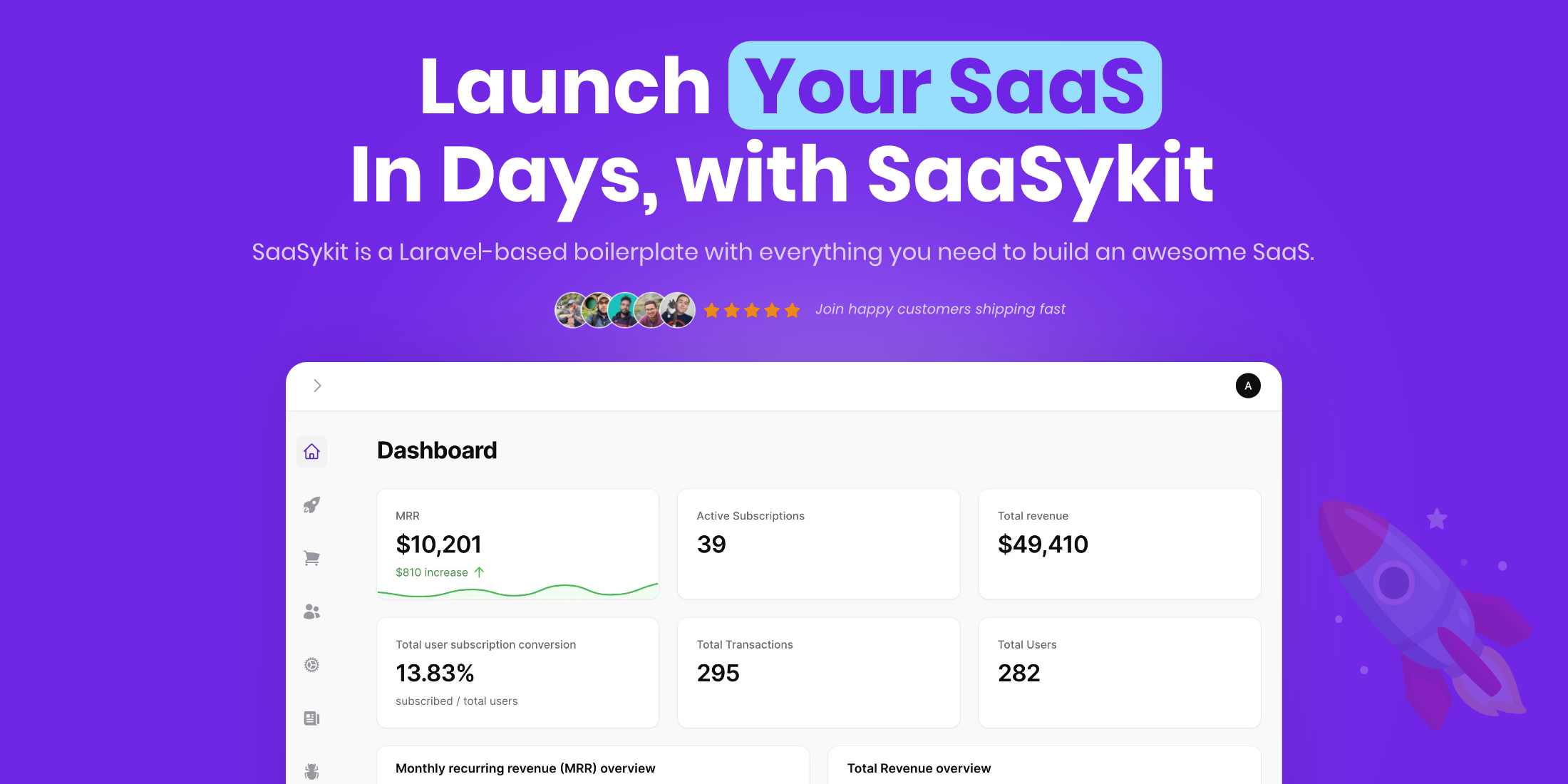
SaaSykit is a feature-rich Laravel SaaS boilerplate that helps you build and launch your SaaS application in days instead of months.
SaaSykit is a robust framework that includes everything needed to run a modern SaaS. It help your launch fast, iterate on your SaaS ideas quickly, save time and effort, and focus on implementing your core SaaS features instead of reinventing the wheel by building every component from scratch to run your SaaS.
The unofficial frisbee throwing speed record is 89.5 mph, and the furthest a disc was ever thrown was 1109 feet. We Make Machines attempted to beat both of these records with the help of a motorized disc launcher. After developing a mini disc launcher, scaling up the design to throw a regulation disc was significantly more challenging and dangerous.
The Ultimate Laravel Admin Panels Overview in 2024
Laravel is popular PHP framework, that allows rapid web app development. Many apps are built around CRUD operations (create, read, update, delete) on database entities. These operations typically involve a listing table, form for creating a record, data validation and other repetitive tasks and components. Admin panel packages have gained popularity in recent years, because they automate many of these repetitive tasks, saving programmers hours of work.
In this article, we will take a look at different approaches of admin panels and compare the most popular solutions, so you can choose the best admin panel for your project in 2024.
To generate or to configure — admin CRUD generators vs configurators
Admin panel packages can generally be classified into two groups: CRUD generators or CRUD configurators. Apart from their different approaches, they also differ in terms of the use case they are best suited for.
Generators, as their name implies, generate source files that can be directly manipulated. In the context of Laravel, this means that the package will generate routes, controllers, views, form requests, and more. This generated code is regular Laravel code that you would otherwise have to write manually. As a result, any developer familiar with Laravel (and potentially frontend technology like Vue.js) will be able to understand and customize the code without much effort.
Configurators offer a different approach to creating CRUD admin panels. Instead of directly generating files, they provide predefined concepts and an API for customizing the admin panel. This means, that you will write specific code (mostly PHP) to define resources, forms, tables and the tool will behind the scenes take care of routes, views and others. While this may be more challenging to get started, due to learning and understanding additional concepts and syntax, they tend to be faster in terms of simple customizations once you know what to do. However, this may not be true if your requirements exceed the capabilities of the tool.
Craftable PRO
Craftable PRO is the successor to the established Laravel CRUD generator, Craftable. It falls into the category of admin panel generators as it generates customizable Laravel source code and files. It utilizes the popular VILT stack (Vue, Inertia, Laravel, Tailwind) for development. Although it is a paid package, it offers many essential features out of the box, including user management, roles and permissions, media management, and translations.
The main and most powerful feature of Craftable PRO is probably the CRUD Generator. It is a command line tool that can generate a complete CRUD (Create, Read, Update, Delete) functionality for your predefined application model with just one command. This tool can be used to add an admin panel to an existing database or to quickly start a newly created project. After running the command, you will have the following generated:
routes
controllers
form requests
Vue files for pages (since it uses Inertia)
Since these files are regular Laravel files, you can directly edit them without the need of learning any new concepts or syntax. This automation will save you hours of repeating work for scaffholding the CRUDs so you can focus on the more important advanced tasks.
Customizability may be the biggest strength of the Craftable PRO, but for some people, it may be the exact opposite. After running the generator, you will have all the files for the CRUD generated and ready for direct editing, which means that you cannot run the generator for the specific module again without loosing your changes. This can be “fixed“ by using GIT history, but it is not as convenient.
Backpack
Backpack from the point of generator/configurator approach would fall somewhere in between. It generates some of the source files like you would normally do in Laravel, but you still use some of the tool specific API to create CRUD for your resource. It uses a different approach than typical configuration-based admin panels like Filament or Nova, which share some of the common principles. Another difference from the other admin panels is the tech stack. Backpack uses Bootstrap and jQuery. While you may entirely omit working with Tailwind or Bootstrap in some admin panels, it may be an important point if you plan to extend the panel with custom functionality.
Backpack provides all the core features you need to create a CRUD admin panel, as well as the official and community addons. You have also ability to create your custom addon, but the process feels a little bit more complicated then in Filament. The UI feels a little bit older, but that is more of a subjective opinion.
While Backpack core is open-source and free, it has its PRO version which is paid, and it will provide you with additional tools, like new fields, columns, charts and many more.
Filament
Filament is an open-source “collection of beautiful full-stack components” which are mainly used to create admin panels, but can be also used outside of admin panels for crafting standalone forms, tables and more. Filament is build on top of TALL stack (Tailwind, Alpine.js, Laravel, Livewire). It provides a simple API for managing resources, creating flexible tables, forms via classes that acts as configuration.
Like all configuration based admin panels, it requires an initial understanding of concepts and learning the syntax, but it is pretty simple to get up and running in a short time. If you can fit the needs of your administration within the provided features of Filament, all you have to touch are resources files and you do not have to deal with Livewire at all. Anyway, Filament provides a great developer experience when it comes to extending and creating plugins, which may be the reason behind community creating dozens of them.
On the other hand of simplicity, we found a few caveats after working with Filament for a while. Filament can sometimes feel a little bit “slow” or “laggy”, mainly if you do not optimize your queries and actions. This is mainly caused by Livewire doing AJAX requests behind the scenes. Since the Livewire v3 introduced some optimalizations, it may not happen as much, but some may still find Filament a little bit slower than competitors. Another problem is heavy customization, which may require advanced Livewire and Alpine skills together with some creative workarounds.
Laravel Nova
Another super popular package for creating admin panels in Laravel is Nova, which is a premium package from creators of Laravel. Based on VILT stack (Vue, Inertia, Laravel, Tailwind), Nova is configuration based admin panel solution, which provides a wide variety of tools to manage resources, menus, search, filters and many more. This way, you don’t directly create routes and views, but rather write classes that follow Nova conventions and syntax.
After the initial learning curve (which is in my opinion a little more steep than in Filament), one can pretty easily create and customize a lot of things. Everything can be found in extensive documentation.
A general problem of admin panel configurators is customization that is behind the predefined features. With Nova, this seems to be the most problematic part as it is harder to extend functionality and create custom components than it is for the competitors. There are, however, a plenty of open source packages available from the community.
An experimental satellite that launched in 1974 disappeared from ground-based sensors in the 1990s, only to be found again this week. Some defunct satellites or debris can often go missing for years, presenting hazards within an increasingly crowded Earth orbit. But, how exactly do objects disappear in space?
Astronomers Could Soon Get Warnings When SpaceX Satellites Threaten Their View
The Infra-Red Calibration Balloon (S73-7) satellite was part of the United States Air Force’s Space Test Program. After launching on April 10, 1974, a large reconnaissance satellite, called KH-9 Hexagon, ejected the 26-inch-wide (66-centimeter-wide) satellite, boosting it to a 500 mile (800 kilometers) circular orbit.
The Air Force’s KH-9 Hexagon satellite, pictured above, deployed the tiny IRCB (S73-7) satellite in 1974.Illustration: U.S. Air Force
The tiny satellite was supposed to inflate in orbit and serve as a calibration target for remote sensing equipment. Its deployment, however, failed, and it became another piece of space junk. When looking over the satellite’s archival data, Jonathan McDowell, an astrophysicist from the Harvard-Smithsonian Center for Astrophysics, found that it had gone missing once before, with radars tracking it in the 1970s before it disappeared, and then again in the 1990s before it disappeared once more.
The satellite was rediscovered earlier this week after being untracked for the past 25 years, according to tracking data from the Space Force’s 18th Space Defense Squadron. “The problem is that it possibly has a very low radar cross section,” McDowell told Gizmodo over the phone. “And maybe the thing that they’re tracking is a dispenser or a piece of the balloon that didn’t deploy right, so it’s not metal and doesn’t show up well on radar.”
Ground-based radar and optical sensors are keeping track of more than 20,000 objects in orbit, and that can get quite tricky. There is a global network of sensors that feeds information to an up-to-date catalogue of satellites, but the majority of objects don’t transmit their identities. Instead, the sensors depend on identifying the orbit of a moving object and matching it with the designated orbit of a satellite.
“It’s basically like air traffic control,” McDowell said. “All this stuff is whizzing around and if you’re going to try flying through that, you want to know where the hazards are.”
After a satellite is launched, engineers on the ground know roughly where it’s going to be and at what altitude it’s going to be drifting. If an object is found in that designated area, then they can rewind that orbit and see if it meets with the orbit of when the satellite was last seen.
“If you’ve got a recent orbital data set, and there’s not too many things that are similar orbit, it’s probably an easy match,” McDowell said. “But if it’s a very crowded bit of parameter space, and you haven’t seen it for a while, then it’s not so easy to match up.”
Tracking satellites in geostationary orbit—a circular orbit directly above the equator—can be challenging because there are no radars positioned to monitor objects precisely on the equator. “There’s actually a hole in the tracking,” McDowell said. “If you hug the equator, you can hide from the tracking.”
If a satellite also carries out an unexpected maneuver, then engineers are forced to hunt for it in Earth orbit. “If you don’t know exactly where the maneuver was, you may have trouble locating it,” McDowell said. “If I rewind the orbit of an object and fast forward for the missing object, do they meet and is the point where they meet where the maneuver happened?”
Most things that end up go missing in space are either defunct satellites or broken up fragments of debris. The Department of Defense’s global Space Surveillance Network is currently tracking more than 27,000 objects in orbit, the majority of which are spent rocket boosters, and operational and dead satellites.
As Earth orbit gets more crowded with a growing number of satellite constellations and rocket launches, it’s become more crucial to keep track of all these objects.
“If you’re missing one or two objects, that’s not a huge risk,” McDowell said. “But you want to do as good a job as you can.”
For more spaceflight in your life, follow us on X and bookmark Gizmodo’s dedicated Spaceflight page.
https://www.percona.com/blog/wp-content/uploads/2024/05/MySQL-8.4-First-Peek-200×112.jpgMySQL 8.4 has now been officially released, and this is a quick review of what is in the release notes. This is momentous as it is designated a Long-Term Support (LTS) release. Various 8.0 releases introduced material changes that impacted speed and stability, causing hair-pulling and swearing among those affected. Please note this is a […]Percona Database Performance Blog
On October 7, more than 1,200 Israeli citizens were brutally murdered, and 250 were taken hostage. The carnage of the attack was apocalyptic. The videos — many taken by the Hamas terrorists themselves — are horrific and terrible to watch. There were countless rapes. Children were burned alive in ovens. Bodies were mutilated and torn apart.
And yet, fairly quickly, Hamas and an ever-growing radical contingent in the West were quick to change the narrative. Hamas jihadis positioned themselves not only as the victims but as the resistance fighters. What they did on October 7 — an ethnic cleansing — is the real outrage and the actual violation of human rights, not the so-called “war crimes” Israel is ostensibly committing against Gaza.
Sheryl Sandberg, former Facebook COO, has been fighting to bring justice and witness to the suffering and atrocities committed against the Israelis, particularly the mass rape of women. She has created and recently released a documentary called “Screams Before Silence,” in which she interviews victims, witnesses, and released hostages. The documentary includes footage of captured Hamas operatives admitting to their crimes.
In an interview with Fox News, Sandberg got right to the point, saying, “If you believe that October 7 was resistance — and I do not believe that; I don’t believe terror is resistance — but if you believe that, sexual violence doesn’t fit into that narrative because rape is never resistance.”
It’s also not politically correct to point out that rape is a common weapon used by men against women of that culture. In an interview with Jordan Peterson, Mosab Hassan Yousef, whose father was a Hamas leader, describes his own experiences living in Gaza, where rape is a way to insult your enemies and killing the victim is a way to hide your shame.
Sandberg also declared that this should be a nonpartisan issue. We all should be able to agree that rape is a human rights violation. Sandberg laments what is occurring on college campuses: “University is a time where you go to college. You can talk about any issue, open dialogue. The truth is, the disorder on campus — having places where people don’t feel safe — that doesn’t lend itself to real dialogue about hard issues. That stops the honest conversations we need to have.”
Aside from the fact that colleges enforce diktats against certain types of speech all the time, it’s worth pointing out that a former Facebook COO saying she is a free speech advocate is interesting because of how guilty the social media platform is of censorship and stifling free speech.
What is happening on college campuses is about so much more than misguided college idiots and zealots causing chaos. Many who are instigating these “protests” are bused-in professional activists bought and paid for by interests such as George Soros who benefit from this sort of social turmoil.
By dismissing the rapes and the brutal murders and by flippantly claiming that Gaza’s damages go all the way back to the first Arab-Israeli war in 1948 trivializes a complex conflict that is far older than that. These atrocities should horrify and sober any sane person. Sandberg is doing her part to wake up the complacent, propagandized West in the hopes of bearing witness to the tragedy and calling attention to the severe blind spot in the discourse regarding the Israel-Hamas war.
https://planetscale.com/assets/blog/content/the-mysql-adaptive-hash-index/social.jpgThe adaptive hash index help to improve performance of the already-fast B-tree lookupsPlanet MySQL
prisoninmate writes: Fedora Linux 40 distribution has been officially released — powered by the latest Linux 6.8 kernel series, and featuring the GNOME 46 and KDE Plasma 6 desktop environments, reports 9to5Linux: "Powered by the latest and greatest Linux 6.8 kernel series, the Fedora Linux 40 release ships with the GNOME 46 desktop environment for the flagship Fedora Workstation edition and the KDE Plasma 6 desktop environment for the Fedora KDE Spin, which defaults to the Wayland session as the X11 session was completely removed." "Fedora Linux 40 also includes some interesting package management changes, such as dropping Delta RPMs and disabling support in the default configuration of DNF / DNF5. It also changes the DNF behavior to no longer download filelists by default. However, this release doesn’t ship with the long-awaited DNF5 package manager. For AMD GPUs, Fedora Linux 40 ships with AMD ROCm 6.0 as the latest release of AMD’s software optimized for AI and HPC workload performance, which enables support for the newest flagship AMD Instinct MI300A and MI300X datacenter GPUs."
We’ve seen how they make disco balls in the last American mirror ball factory; now see how they do it in Japan. Nissho Co., Ltd. makes shiny spheres by bending sheet metal into domes, screwing them together, hand-cutting and gluing hundred of round mirror tiles then filling the gaps with grout. Note that the tiles are different sizes depending on their placement.

 MySQL 8.4 has now been officially released, and this is a quick review of what is in the release notes. This is momentous as it is designated a Long-Term Support (LTS) release. Various 8.0 releases introduced material changes that impacted speed and stability, causing hair-pulling and swearing among those affected. Please note this is a […]Percona Database Performance Blog
MySQL 8.4 has now been officially released, and this is a quick review of what is in the release notes. This is momentous as it is designated a Long-Term Support (LTS) release. Various 8.0 releases introduced material changes that impacted speed and stability, causing hair-pulling and swearing among those affected. Please note this is a […]Percona Database Performance Blog
